توجيه طلبات AI هو قدرة بنية تحتية مصممة لإدارة موارد الاستدلال عبر نماذج متعددة. مع استمرار تطور نماذج اللغة الكبيرة مثل GPT وClaude وGemini وDeepSeek، يدمج عدد متزايد من تطبيقات AI نماذج متعددة في وقت واحد. وأصبح الاختيار الذكي بين النماذج المختلفة موضوعًا محوريًا في تصميم أنظمة AI.
تعمل Gate.AI كطبقة وسيطة بين التطبيقات وخدمات النماذج، لتكون بمثابة بوابة AI وطبقة توجيه للنماذج. ومع اعتماد البنى متعددة النماذج كمعيار صناعي، لا يؤثر توجيه النماذج على أداء النظام فحسب، بل يمتد تأثيره إلى التحكم في التكاليف، واستقرار الخدمة، والقدرات الذاتية لوكلاء AI.
ما هو توجيه طلبات AI؟
باعتبارها آلية جدولة تختار تلقائيًا نموذجًا مستهدفًا بناءً على خصائص المهمة، يتضمن توجيه طلبات AI في البنى التقليدية عادةً قيام تطبيق باستدعاء نموذج واحد ثابت لإكمال مهام الاستدلال. أما في البنى متعددة النماذج، فتقدم النماذج المختلفة مزايا متميزة، مثل قدرة الاستدلال، وتوليد الكود، ومعالجة النصوص الطويلة، أو كفاءة التكلفة.
تقوم طبقة توجيه النماذج بتحليل محتوى الطلب وإرساله إلى النموذج الأكثر ملاءمة للتنفيذ، مما يحسن استخدام الموارد الإجمالي.
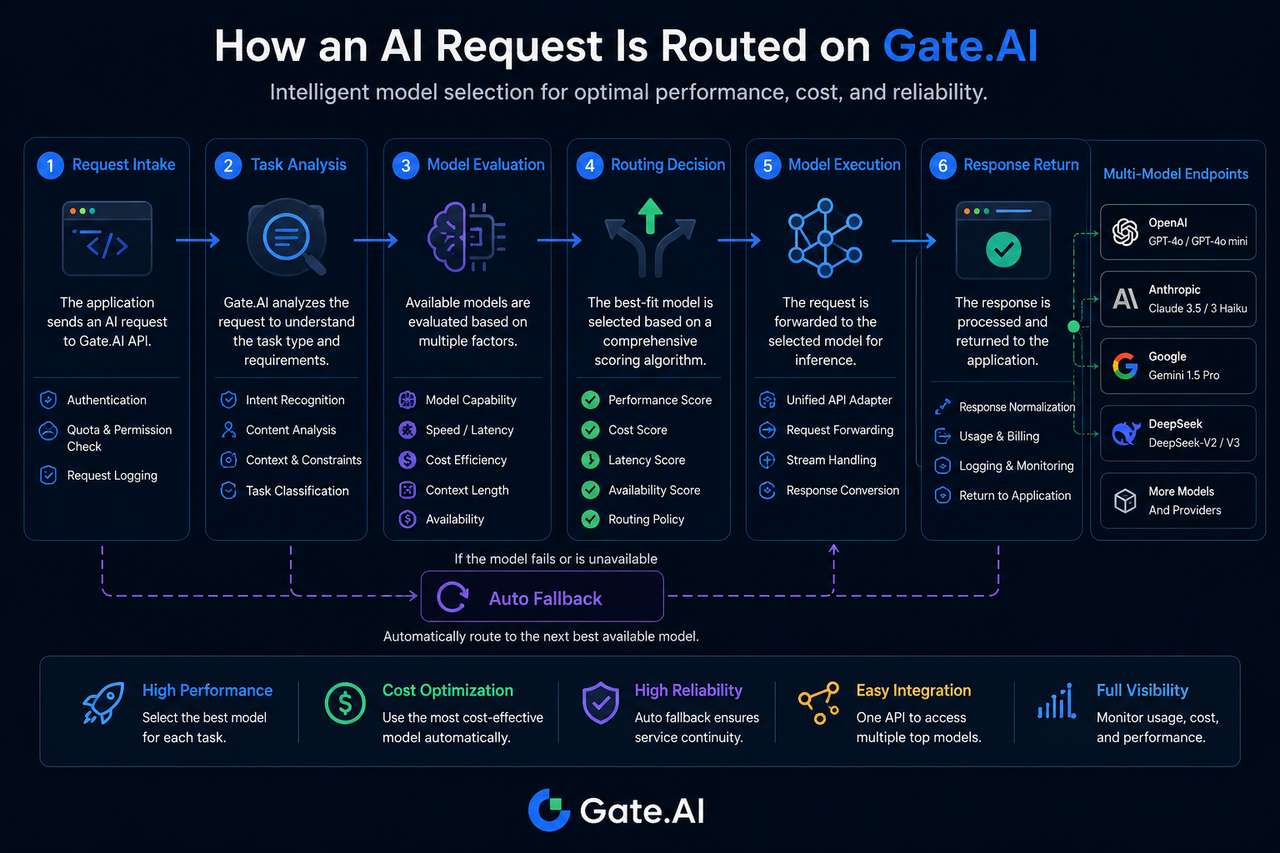
الخطوة 1: دخول طلب AI إلى Gate.AI
تبدأ عملية التوجيه بمرحلة استقبال الطلب.
عندما يرسل تطبيق طلبًا، يدخل أولاً إلى طبقة بوابة Gate.AI. هنا، يتحقق النظام من معلومات الهوية، ويتحقق من أذونات الوصول، ويسجل معلمات الطلب.
يتضمن محتوى الطلب عادةً:
- إدخال المستخدم
- تكوين النموذج
- حدود الرموز
- متطلبات تنسيق الاستجابة
- استراتيجية الاستدعاء
بعد التحقق، ينتقل الطلب إلى مرحلة التحليل التالية.
الخطوة 2: تحليل النظام لنوع المهمة
يعد تحديد نوع المهمة مكونًا رئيسيًا لتوجيه النماذج.
تحدد Gate.AI نوع المهمة بناءً على خصائص الطلب، على سبيل المثال:
- محادثة عامة
- تلخيص نصوص طويلة
- إنشاء محتوى
- توليد كود
- تحليل بيانات
- استدعاءات أدوات الوكيل
تختلف متطلبات قدرة النموذج اختلافًا كبيرًا باختلاف المهام.
يُسهم تحديد المهمة بدقة في جعل عملية مطابقة النموذج اللاحقة أكثر كفاءة.
الخطوة 3: تقييم قدرة النموذج ومطابقته
تحدد مرحلة تقييم النموذج نطاق النماذج المرشحة.
يرجع النظام إلى قاعدة بيانات قدرة النموذج لتصفية النماذج المتاحة حاليًا.
تشمل أبعاد التقييم عادةً:
- قدرة الاستدلال
- طول السياق
- سرعة الاستجابة
- قدرة استدعاء الأداة
- دعم الوسائط المتعددة
- مستوى التكلفة
على سبيل المثال، قد تعطي مهام الاستدلال المعقدة الأولوية للنماذج ذات قدرات الاستدلال الأقوى، بينما قد تفضل مهام معالجة المستندات الطويلة النماذج التي تدعم نوافذ سياق فائقة الطول.
الخطوة 4: توليد قرار التوجيه
تحدد مرحلة قرار التوجيه نموذج التنفيذ النهائي.
بعد تحديد النماذج المرشحة، يقوم النظام بتسجيلها من خلال الجمع بين مقاييس متعددة.
تشمل العوامل المرجعية الشائعة ما يلي:
أداء النموذج
يحدد أداء النموذج جودة إتمام المهمة.
تتطلب المشكلات المعقدة عادةً استدلالًا منطقيًا أقوى، بينما قد لا تحتاج المهام البسيطة إلى أعلى نموذج أداء.
زمن الاستجابة
تؤثر سرعة الاستجابة بشكل مباشر على تجربة المستخدم.
بالنسبة لسيناريوهات التفاعل في الوقت الفعلي، غالبًا ما تحصل النماذج منخفضة زمن الاستجابة على أولوية أعلى.
تكلفة الاستدعاء
تختلف تكاليف الاستدلال عبر النماذج المختلفة.
عندما يمكن لنماذج متعددة إتمام نفس المهمة، قد يعطي النظام الأولوية للنموذج ذي كفاءة الموارد الأعلى.
توفر الخدمة
حالة النموذج هي أيضًا عامل مهم في قرارات التوجيه.
إذا كان النموذج محدودًا بالمعدل، أو يواجه أعطالًا، أو مزدحمًا، يخفض النظام تلقائيًا أولويته.
الخطوة 5: إرسال الطلب إلى النموذج المستهدف
بعد اتخاذ قرار التوجيه، يتم إعادة توجيه الطلب إلى النموذج المستهدف.
في هذه المرحلة، تتعامل Gate.AI مع الاختلافات في الواجهات عبر مختلف موفري النماذج بشكل موحد.
لا يحتاج مطورو التطبيقات إلى تطوير واجهات منفصلة لنماذج مختلفة.
تعمل طبقة الوصول الموحدة على تقليل تعقيد التطوير وتحسين قابلية توسيع النظام.
الخطوة 6: توليد النموذج للنتيجة وإعادتها
بعد أن يكمل النموذج المستهدف الاستدلال، يتم إرجاع النتيجة إلى Gate.AI.
تقوم Gate.AI بتوحيد الاستجابة، مما يضمن هياكل بيانات متسقة من نماذج مختلفة.
يقلل تنسيق الإخراج الموحد من أعمال التكيف في طبقة التطبيق ويبسط تكامل النظام اللاحق.
يتم إرجاع النتيجة النهائية إلى التطبيق أو وكيل AI.
ماذا يحدث عندما يكون النموذج المستهدف غير متاح؟
عدم توفر النموذج هو أمر شائع في النظام البيئي متعدد النماذج.
إذا انتهت مهلة النموذج المستهدف، أو كان محدودًا بالمعدل، أو عانى من حالات شاذة في الخدمة، يمكن لـ Gate.AI تشغيل آلية تراجع تلقائي.
يقوم النظام بإعادة اختيار نموذج احتياطي وفقًا للسياسات المحددة مسبقًا لمواصلة تنفيذ المهمة.
تقلل هذه الآلية من خطر نقاط الفشل الفردية وتحسن استمرارية الخدمة الإجمالية.
لمزيد من المعلومات حول هذه العملية، راجع "ماذا يحدث عندما يفشل نموذج AI؟ تحليل التدفق الكامل لآلية التراجع التلقائي في Gate.AI."
مثال على عملية توجيه طلبات AI
يوضح المثال التالي تدفقًا نموذجيًا لمهمة إنشاء محتوى:
| المرحلة |
إجراء النظام |
| استلام الطلب |
يرسل التطبيق طلب إنشاء |
| تحليل المهمة |
تم تحديدها على أنها إنشاء محتوى نص طويل |
| تصفية النموذج |
اختيار النماذج المرشحة التي تدعم السياق الطويل |
| قرار التوجيه |
التسجيل بناءً على الأداء والتكلفة وزمن الاستجابة |
| تنفيذ النموذج |
إرسال الطلب إلى النموذج المستهدف |
| معالجة النتيجة |
إرجاع مخرجات موحدة |
| التعافي من الفشل |
التبديل تلقائيًا إلى النموذج الاحتياطي إذا لزم الأمر |
عادةً ما تُكتمل هذه العملية في وقت قصير جدًا، وغالبًا لا يلاحظ المستخدمون اختيار النموذج الذي يحدث خلف الكواليس.
ملخص
باعتبارها قدرة أساسية لبوابة AI، يقوم توجيه طلبات AI ديناميكيًا باختيار النموذج الأكثر ملاءمة لتنفيذ مهمة من بين نماذج لغة كبيرة متعددة. مقارنة بالاستدعاء الثابت لنموذج واحد، يستفيد توجيه النماذج بشكل كامل من نقاط قوة النماذج المختلفة، مما يعزز مرونة النظام واستقراره واستخدام الموارد.
في بنية Gate.AI، يمر طلب AI بعدة مراحل: استلام الطلب، تحديد المهمة، تقييم النموذج، قرار التوجيه، تنفيذ النموذج، وإرجاع النتيجة.
الأسئلة الشائعة
لماذا تحتاج Gate.AI إلى توجيه النماذج؟
تربط Gate.AI أنظمة بيئية متعددة لنماذج AI، حيث تتفوق النماذج المختلفة في الاستدلال، وتوليد الكود، ومعالجة النصوص الطويلة، وغيرها من المجالات. يختار توجيه النماذج تلقائيًا النموذج الأكثر ملاءمة بناءً على متطلبات المهمة.
هل يمكن لطلب AI واحد استدعاء نماذج متعددة في نفس الوقت؟
عادةً، يُنفَّذ طلب AI واحد بواسطة نموذج مستهدف واحد. ومع ذلك، في بعض السيناريوهات المعقدة، قد يُستخدم نمط تعاون متعدد النماذج، حيث تتعامل نماذج مختلفة مع أجزاء مختلفة من المهمة.
ما العوامل التي تؤخذ بعين الاعتبار بشكل أساسي في قرارات توجيه AI؟
تأخذ قرارات توجيه AI عادةً في الاعتبار عوامل متعددة مثل أداء النموذج، وسرعة الاستجابة، وتكلفة الاستدلال، وطول السياق، وقدرة استدعاء الأداة، وتوفر الخدمة.
ما الفرق بين توجيه النموذج وموازنة الحمل؟
تُعنى موازنة الحمل أساسًا بتوزيع حركة المرور، بينما يركز توجيه النموذج على مطابقة قدراته مع المهمة. يختار توجيه النموذج النموذج الأكثر ملاءمة بناءً على خصائص المهمة، وليس مجرد توزيع حركة الطلبات.








