A medida que los modelos de IA evolucionan hacia la multimodalidad, los casos de uso verticales y los agentes inteligentes, el consenso del sector está migrando de "cuantos más datos, mejor" a "los datos de alta fidelidad, trazables y conformes con la privacidad son el recurso escaso". Las plataformas de etiquetado centralizadas tradicionales se topan con cuellos de botella en costes, capacidad de respuesta ante la demanda de cola larga y distribución equitativa de los contribuyentes. Las redes de datos de IA descentralizadas buscan reconfigurar las relaciones de producción de datos mediante inteligencia colectiva, coordinación de tokens e interfaces abiertas. Para entender cómo opera Alaya AI, es necesario examinar sus capas técnicas, su canalización de autoetiquetado, su lógica de muestreo y sus mecanismos económicos en cadena, en lugar de descartarlo como un mero «servicio externalizado de etiquetado sobre blockchain».
Desde una perspectiva de arquitectura industrial, Alaya AI representa la convergencia de Web3 y la IA en la capa de datos: las contribuciones de datos pueden incentivarse, los permisos de tareas pueden tokenizarse como NFT y el desarrollo de modelos puede financiarse mediante el apoyo comunitario a través del pool de staking de AGT, mientras que la Plataforma de Datos Abiertos (ODP) conecta la oferta y la demanda. Las secciones siguientes desglosan la arquitectura central de la red, los mecanismos de mejora de la eficiencia, la integración con Web3, los sistemas de staking y contribución, las diferencias con las plataformas tradicionales, los desafíos reales y las direcciones futuras, ofreciendo un marco estructurado para evaluar su viabilidad técnica y el valor del ecosistema.
Desglose de la arquitectura técnica central de Alaya AI
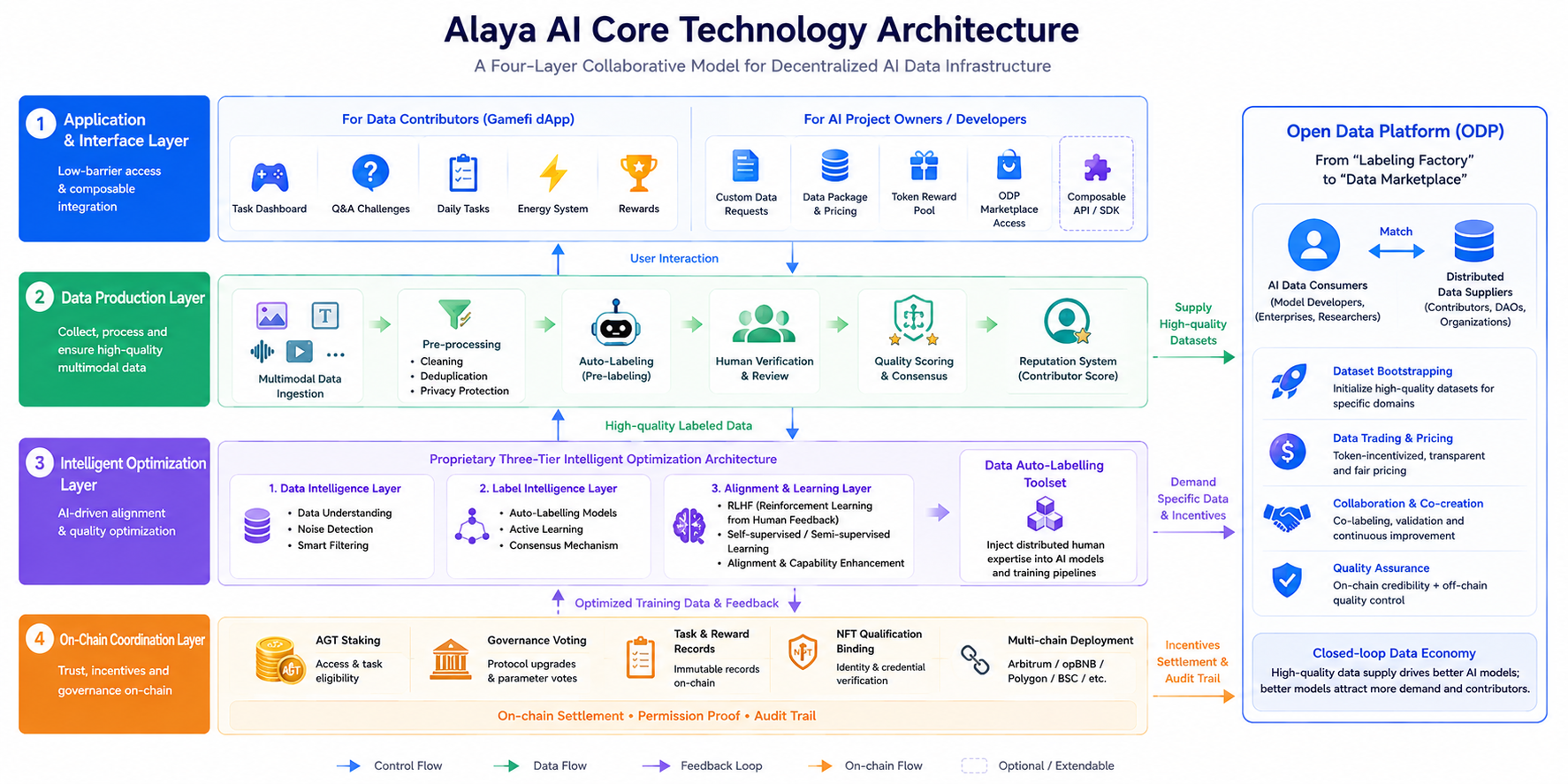
La arquitectura general de Alaya AI puede describirse como un modelo colaborativo de cuatro capas, donde cada capa tiene responsabilidades claramente separadas con flujos de datos y control diferenciados, evitando la sobrecarga de rendimiento de «poner todo en cadena».
-
Capa de aplicación e interfaz. Incluye una dApp gamificada para los contribuyentes de datos (con paneles de tareas, desafíos de preguntas, tareas diarias, etc.), así como solicitudes personalizadas de datos, ofertas de paquetes de datos y la entrada al mercado ODP para equipos de proyectos de IA. Esta capa prioriza la participación con barreras bajas y el acceso componible, permitiendo a los desarrolladores publicar necesidades de datos verticales a través de pools de recompensas de tokens personalizados.
-
Capa de producción de datos. Se encarga de la ingesta de datos multimodales (texto, imágenes, vídeo, audio), preprocesamiento (limpieza, deduplicación, protección de la privacidad), autoetiquetado, verificación manual y puntuación de calidad. Alaya AI se basa en principios de inteligencia colectiva: una misma tarea puede ser etiquetada de forma cruzada por varios contribuyentes, utilizando mecanismos de consenso o mayoría para mejorar la consistencia de las etiquetas, mientras que la precisión histórica construye una reputación del contribuyente que influye en la asignación futura de tareas.
-
Capa de optimización inteligente. El componente central es el Conjunto de herramientas de autoetiquetado de datos, impulsado por una arquitectura de optimización inteligente de tres capas propia. Combinado con el ajuste fino RLHF (aprendizaje por refuerzo a partir de retroalimentación humana), inyecta experiencia humana distribuida en procesos autosupervisados y semisupervisados, apoyando la alineación y la mejora de la capacidad del modelo.
-
Capa de coordinación en cadena. La información clave de coordinación —como el staking de AGT, la votación de gobernanza, los registros de estado de tareas y recompensas, y la vinculación de calificaciones NFT— depende de la blockchain (los despliegues del ecosistema abarcan múltiples cadenas, incluyendo Arbitrum, opBNB, Polygon y BSC; consulta los anuncios oficiales para más detalles). La cadena no almacena grandes volúmenes de datos brutos, sino que gestiona la liquidación de incentivos, la prueba de permisos y el anclaje de pistas de auditoría, siguiendo el paradigma de diseño común de IA Web3 de «computación fuera de cadena, confianza en cadena».
La Plataforma de Datos Abiertos (ODP), lanzada en noviembre de 2024, transforma la red de una «fábrica de etiquetado» a un «mercado de datos»: los consumidores de datos de IA y los proveedores distribuidos se conectan directamente mediante incentivos de tokens personalizables, facilitando el arranque, el comercio y la colaboración de conjuntos de datos para crear un bucle cerrado de oferta y demanda.
Cómo el sistema de autoetiquetado mejora la eficiencia de los datos de IA
El autoetiquetado es un módulo central para que Alaya AI reduzca los costes marginales y acorte los ciclos de entrega. El proyecto lo posiciona como la siguiente fase de la evolución de la IA autosupervisada: las máquinas generan primero etiquetas candidatas, luego los humanos se centran en muestras ambiguas y juicios específicos del dominio, en lugar de etiquetar manualmente cada dato desde cero.
El proceso técnico normalmente incluye estos pasos:
-
Ingesta multimodal: El conjunto de herramientas acepta datos visuales estáticos y dinámicos, texto y entradas de sensores, que pasan a un pipeline de preprocesamiento unificado.
-
Preprocesamiento algorítmico: Se realiza limpieza automática y deduplicación. Se aplica cifrado de conocimiento cero (ZK-encryption) a las rutas de datos sensibles, permitiendo la computación mientras se minimiza la exposición de texto plano, abordando los requisitos de privacidad y cumplimiento de los clientes empresariales.
-
Preetiquetado del modelo: Un modelo de autoetiquetado propietario genera etiquetas iniciales. Para categorías comunes de datos de IA, el proyecto afirma una tasa de verificación superior al 80 %, con procesamiento en tiempo real de flujos visuales dinámicos, algo crítico para escenarios como el etiquetado de fotogramas de conducción autónoma y vídeos de inspección de calidad industrial.
-
Bucle de optimización RLHF: Los resultados de verificación de los contribuyentes se retroalimentan al modelo, reduciendo continuamente la proporción de revisión manual. La práctica del sector muestra que dentro de un bucle RLHF, la intervención humana puede concentrarse en aproximadamente el 20 % de las muestras de alta dificultad, reduciendo significativamente los costes y plazos generales (las proporciones exactas varían según el tipo de tarea).
-
Capa de verdad experta: Para pedidos de alta fidelidad de nivel empresarial, la plataforma puede desplegar un equipo interno de expertos en el dominio (ingenieros, lingüistas, especialistas visuales, etc.) como capa de arbitraje final, creando una estructura de doble vía de «rendimiento automatizado + precisión experta» junto con los resultados de crowdsourcing. Los materiales de 2026 también enfatizan que los datos masivos y ruidosos se están convirtiendo en un cuello de botella operativo, y que los datos verticales de alta fidelidad son el combustible esencial para los modelos y agentes de próxima generación.
El valor de esta arquitectura híbrida radica en que la red pública proporciona escala y velocidad, mientras que el pipeline cerrado de expertos mantiene los niveles de calidad de referencia en industrias sensibles al riesgo, evitando que la descentralización se malinterprete como «crowdsourcing de baja calidad».
Cómo funciona el mecanismo de muestreo distribuido de datos
A diferencia del «raspado aleatorio completo», Alaya AI enfatiza la optimización inteligente y el muestreo dirigido: seleccionar muestras con alta densidad de información en función de los objetivos del modelo, aliviando el problema de «gran conjunto de datos, baja señal efectiva».
El mecanismo de muestreo puede entenderse desde tres dimensiones:
-
Impulsado por la demanda: Los clientes de IA envían solicitudes personalizadas (por ejemplo, dialectos específicos, imágenes médicas especializadas, condiciones de tráfico regionales). La plataforma dirige las unidades de trabajo a grupos de contribuyentes que coincidan con el nivel NFT requerido, idioma o antecedentes profesionales, logrando una alineación aproximada entre la mano de obra y las tareas.
-
Muestreo de redundancia grupal: Varias personas etiquetan de forma independiente el mismo lote de datos. La detección de consistencia identifica etiquetas atípicas; las muestras de baja consistencia entran automáticamente en una cola de revisión o un canal de expertos. Esto reemplaza la supervisión completa de un único inspector de calidad con redundancia distribuida.
-
Derivación dinámica y estática: Las tareas de imágenes estáticas y las tareas de flujo de vídeo dinámico utilizan diferentes estrategias de rendimiento. La visión dinámica puede integrar segmentación automática y etiquetado a nivel de fotograma para reducir los costes manuales por fotograma.
-
Muestreo temporal y de escenario: Los escenarios oficiales incluyen utilizar tiempo fragmentado (por ejemplo, desplazamientos) para participar en tareas ligeras, convirtiendo la mano de obra inactiva en capacidad de producción de datos. Una interfaz de usuario gamificada (puntos de experiencia, valores de energía) mantiene la retención a largo plazo, haciendo que el pool de muestreo sea continuo en lugar de un sprint de crowdsourcing único.
La limpieza y deduplicación en el preprocesamiento reducen el sesgo de muestreo en el origen: si muestras duplicadas, archivos corruptos o metadatos incorrectos entran en el conjunto de entrenamiento, amplifican las alucinaciones y los sesgos del modelo. Por lo tanto, el muestreo no se trata solo de «cuánto muestrear», sino también de un esfuerzo de ingeniería sistemático que involucra «qué muestrear, quién lo hace y cómo verificar».
Cómo se combinan Web3 y las redes de IA
Los atributos Web3 de Alaya AI no se limitan a «pagar con tokens», sino que implican tokenizar, convertir en NFT y gobernar los elementos clave de coordinación de la red de datos.
-
Coordinación de tokens: El token nativo AGT sirve como umbral de staking, voto de gobernanza, desbloqueo de tareas avanzadas, actualización de NFT y entrada de financiación del pool de staking de modelos. El diseño de staking enfatiza el coste hundido y la seguridad. El proyecto establece explícitamente que el staking de AGT no proporciona rendimiento pasivo, evitando que el capital especulativo distorsione los incentivos de calidad del etiquetado.
-
Permisos NFT: El Alaya NFT y el Medallion NFT forman un sistema de identidad de doble vía, determinando el tipo de tareas accesibles, los límites de nivel y los sistemas de logros. Las actualizaciones de alto nivel consumen AGT en nodos específicos, vinculando la identidad en cadena con la producción laboral fuera de cadena.
-
Combinaciones de incentivos abiertos: Los proyectos pueden usar AGT o sus propios tokens para crear pools de datos personalizados, atendiendo a las preferencias de liquidación de los equipos de IA nativos de Web3. Los desarrolladores pequeños y medianos pueden arrancar conjuntos de datos con costes de efectivo más bajos a través de ODP.
-
Auditoría en cadena y linaje: Para clientes empresariales, la plataforma enfatiza la integridad criptográfica de extremo a extremo y las pistas de auditoría inmutables, haciendo que el linaje de datos sea rastreable para apoyar las revisiones de cumplimiento.
-
Gamificación y crecimiento social: Mecanismos como tareas diarias, comisiones por referidos y la redención mensual de AGT (los usuarios intercambian créditos AIA obtenidos de tareas por AGT en un pool de redención de tiempo fijo) mapean periódicamente la actividad fuera de cadena a la distribución de valor en cadena.
-
Despliegue multicadena: Reduce la fricción para los usuarios en diferentes ecosistemas. La misma red de datos puede llegar a grupos de usuarios en Arbitrum, opBNB, etc. La hoja de ruta también menciona la expansión a BNB Chain, Optimism, etc., para adaptarse a las diferencias de tarifas y velocidad.
La narrativa del ecosistema de 2026 posiciona aún más a Alaya AI como la columna vertebral de datos para los agentes de IA: los agentes requieren retroalimentación humana continua y conocimiento de nicho, mientras que el crowdsourcing Web3 combinado con autoetiquetado proporciona un pipeline de retroalimentación escalable. La sinergia con frameworks de agentes interactivos en tiempo real (como las capacidades similares a OpenClaw discutidas externamente) apunta a un futuro de doble bucle de «aprendizaje sobre la marcha + conjuntos de datos verificados a gran escala».
Análisis de los sistemas de staking de modelos de IA y contribución de datos
La tokenización de modelos de IA es un mecanismo clave que distingue a Alaya AI de las plataformas de etiquetado generales: la comunidad puede financiar y proporcionar mano de obra de datos para el desarrollo y ajuste fino de modelos específicos a través del pool de staking de AGT, facilitando la alineación de «quien contribuye con datos se beneficia de las mejoras del modelo».
-
Ruta del contribuyente: Registrar dApp → Completar tareas básicas para construir reputación → Hacer staking de AGT para desbloquear tareas de nivel superior (verificación, calibración, colaboración de autoetiquetado) → Obtener multiplicadores de recompensa más altos; simultáneamente ganar créditos AIA para participar en la redención mensual por AGT.
-
Ruta del proyecto: Publicar solicitudes de datos personalizadas en la plataforma → Configurar pools de recompensas de tokens AGT o de terceros → La plataforma asigna tareas a contribuyentes coincidentes → Después del autoetiquetado y control de calidad manual, entregar el conjunto de datos → Opcionalmente listar o comerciar en ODP.
-
Lógica de seguridad del staking: AGT sirve como herramienta de coordinación de prueba de participación, aumentando el coste económico del etiquetado malicioso y el cultivo de volumen. Combinado con Medallion NFT, restringe aún más el acceso a tareas de alto nivel, protegiendo los pedidos de datos de alto valor.
-
Retorno de valor: El plan oficial es utilizar los ingresos del servicio de datos de la plataforma para recomprar AGT e inyectarlo en el pool de recompensas de usuarios, intentando cerrar el volante de negocio de «demanda del cliente → ingresos → reincentivo → más datos de alta calidad». Su efecto real depende del volumen de pedidos empresariales y la transparencia de la recompra.
Este sistema transforma la contribución de datos de un trabajo único a una colaboración en red con participación: los contribuyentes, los stakers y los proyectos compiten y cooperan bajo el mismo conjunto de reglas, una estructura Web3 que las plataformas de etiquetado SaaS tradicionales no pueden soportar de forma nativa.
| Dimensión |
Alaya AI |
Plataformas tradicionales (ej. Scale AI, Labelbox) |
| Forma organizativa |
Comunidad distribuida + Plataforma abierta |
Operaciones centralizadas y contratos empresariales |
| Incentivo |
AGT, AIA, NFT, gamificación |
Principalmente compensación en Fiat |
| Personalización de datos |
Pools de tokens personalizados, solicitudes P2P |
SLA estándar y procesos de adquisición |
| Expresión de propiedad |
NFT y registros en cadena enfatizan la equidad de contribución |
Términos contractuales definen |
| Automatización |
Autoetiquetado de tres capas + RLHF + Revisión de expertos |
Pipelines maduros, muchos casos verticales profundos (ej. automoción) |
| Tipo de cliente |
Equipos de IA nativos de Web3 y pequeños/medios, expansión empresarial en curso |
Grandes empresas tecnológicas, proyectos gubernamentales dominan |
Las ventajas de Alaya AI residen en la cola larga, el alcance transfronterizo, la formación rápida de pools y los incentivos transparentes. Las plataformas tradicionales destacan en certeza de entrega, madurez legal, certificaciones del sector y experiencia con proyectos de megaescala. Las redes descentralizadas no reemplazan a los proveedores centralizados en todos los escenarios, sino que establecen diferenciación en la intersección de «presupuesto sensible, nicho vertical, criptonativo».
Además, Alaya enfatiza los datos verticales de alta fidelidad en lugar de la acumulación infinita de volumen, diferenciándose de la lógica de competencia tradicional de «gran conjunto de datos». Esto favorece a los modelos pequeños y agentes eficientes en parámetros, pero también requiere que los clientes acepten el modelo de precios y entrega de un pipeline híbrido (automático + experto).
Desafíos que enfrentan las redes de datos de IA descentralizadas
A pesar de la arquitectura completa, las redes de datos de IA descentralizadas enfrentan limitaciones del mundo real.
-
Equilibrio entre calidad y escala: Entre millones de usuarios registrados, la proporción de etiquetadores consistentemente de alta calidad es difícil de verificar externamente. Si los incentivos favorecen el cultivo de volumen, perjudicará la renovación de los clientes de IA y la reputación de la red.
-
Barreras de adopción empresarial: Aspectos legales, SOC2, gestores de proyectos dedicados, compensación por accidentes, etc., son requisitos estándar de adquisición empresarial. La transparencia en cadena por sí sola no es suficiente para firmar grandes contratos; se necesita una acumulación continua de casos auditables.
-
Complejidad de la experiencia del usuario: Billeteras, NFT, tokens duales (AGT/AIA), reglas de staking y redención aumentan el coste de aprendizaje para nuevos usuarios, limitando potencialmente la entrada de contribuyentes no Web3.
-
Incertidumbre regulatoria: Los datos transfronterizos, la mano de obra incentivada con tokens y el cumplimiento de datos sensibles como los de salud varían según el país. Los cambios de política pueden afectar las regiones operativas y el diseño del token.
-
Sostenibilidad de liquidez e incentivos: La capitalización de mercado y el volumen de negociación de AGT siguen siendo pequeños en relación con el mercado general. Si los ingresos de la plataforma y las recompras no pueden seguir el ritmo de la oferta de desbloqueo y redención, los incentivos pueden depender de nuevos usuarios en lugar del flujo de caja interno.
-
Riesgos técnicos: Vulnerabilidades de contratos inteligentes, errores de vinculación de billeteras que impiden la recolección de redenciones y amplificación de errores del modelo de autoetiquetado en categorías de cola larga requieren inversión continua en ingeniería.
-
Presión competitiva: Los gigantes centralizados tienen bolsillos profundos y alta fidelidad de clientes. Otros proyectos de datos Web3 también compiten por la misma narrativa, y la diferenciación debe demostrarse con datos entregados.
Direcciones futuras de desarrollo de la tecnología de Alaya AI
Combinando la hoja de ruta oficial y la dinámica de 2025-2026, es probable que la evolución técnica se centre en las siguientes direcciones.
-
Integración profunda de autoetiquetado y RLHF: Mejorar las capacidades de procesamiento en tiempo real para visión dinámica, datos multilingües y de retroalimentación de agentes, acortando el ciclo de «recopilar → etiquetar → implementar de vuelta al modelo».
-
ODP y colaboración social de datos: Expandir desde el arranque de conjuntos de datos hasta funciones de comercio, intercambio y colaboración más activas, mejorando los efectos de red.
-
DAO y mejora de la gobernanza: Someter más decisiones (por ejemplo, prioridades de funciones de autoetiquetado, parámetros económicos) a la votación de los stakers de AGT, aumentando la credibilidad de las narrativas de soberanía comunitaria.
-
Sinergia multicadena y del ecosistema informático: Integrarse con DePIN, computación descentralizada (ej. Akash, Golem) y protocolos de mercado de modelos (ej. Bittensor), explorando el stack abierto «datos → entrenamiento → inferencia» para reducir el bloqueo de plataforma única.
-
Posicionamiento en la era de los agentes: Fortalecer continuamente los datos de alta fidelidad con intervención humana como columna vertebral de razonamiento para los agentes; colaborar con frameworks de aprendizaje de agentes en tiempo real para formar bucles duales rápidos-lentos.
-
Mejora del cumplimiento empresarial: Expandir el cifrado ZK, la auditoría de linaje y la cobertura de revisión de expertos para ganar pedidos en industrias altamente reguladas como la salud y las finanzas.
Mecanismos como la redención mensual de AGT en 2026 indican que el lado operativo está utilizando una cadencia fija para mantener las expectativas de los contribuyentes. Si el lado técnico coincide con la cadencia operativa depende de la inversión sostenida en precisión de autoetiquetado, algoritmos de enrutamiento de tareas y la capa de expertos.
Resumen
La red de datos de IA descentralizada de Alaya AI es esencialmente un sistema de colaboración en capas: la capa de aplicación reduce las barreras de participación, la capa de producción de datos mejora la eficiencia con autoetiquetado y muestreo distribuido, la capa de optimización inteligente absorbe el conocimiento humano a través de RLHF, y la capa de coordinación en cadena alinea incentivos y seguridad con AGT, NFT y reglas de gobernanza. La Plataforma de Datos Abiertos actualiza la red de una plataforma de tareas a un mercado de datos componible, mientras que el pool de staking de modelos introduce capital y mano de obra de la comunidad en el bucle de ajuste fino del modelo.
La relevancia de su lógica operativa para la industria de la IA es la siguiente: cuando los datos verticales de alta calidad se convierten en un cuello de botella, la adquisición centralizada por sí sola no puede cubrir la mano de obra fragmentada de cola larga y global; la arquitectura Web3 ofrece una curva de oferta alternativa. Al mismo tiempo, los desafíos son reales: la verificación de calidad, los SLA empresariales, la regulación y la sostenibilidad de los incentivos determinarán si esta arquitectura técnica puede pasar de «demostrable» a «comercializable a escala».
Para los observadores técnicos, evaluar Alaya AI no debe limitarse a los volúmenes de transacciones en cadena o los registros de usuarios, sino que también debe realizar un seguimiento de indicadores duros como las tasas de verificación de autoetiquetado, las transacciones de ODP, las renovaciones de clientes empresariales y la ejecución de recompras. Estos indicadores responden colectivamente a una pregunta: ¿puede una red de datos de IA descentralizada superar simultáneamente los puntos fuertes principales de las plataformas tradicionales en eficiencia y fiabilidad?








