A medida que los modelos de lenguaje de gran tamaño (LLM) se consolidan como infraestructura crítica para las aplicaciones de IA, los desarrolladores que crean asistentes inteligentes, flujos de trabajo automatizados y agentes de IA se enfrentan a una decisión clave: llamar directamente a la API de OpenAI o emplear una plataforma AI Gateway para gestionar las llamadas a modelos de forma centralizada. Ambas opciones permiten dotar de inteligencia artificial a las aplicaciones, pero difieren sustancialmente en arquitectura del sistema, escalabilidad y complejidad operativa.
En un ecosistema multimodelo en plena evolución, empresas y desarrolladores optan cada vez más por usar varios modelos simultáneamente —como GPT, Claude, Gemini y DeepSeek—. Gestionar de forma centralizada los recursos de los modelos, reducir la dependencia de un único proveedor y mejorar la disponibilidad del sistema se han convertido en temas clave dentro de la infraestructura de IA. Gate.AI surge precisamente en este contexto como plataforma de enrutamiento de modelos y AI Gateway, con un posicionamiento fundamentalmente distinto al de la integración tradicional con una API de un único modelo.
¿Qué es la API de OpenAI?
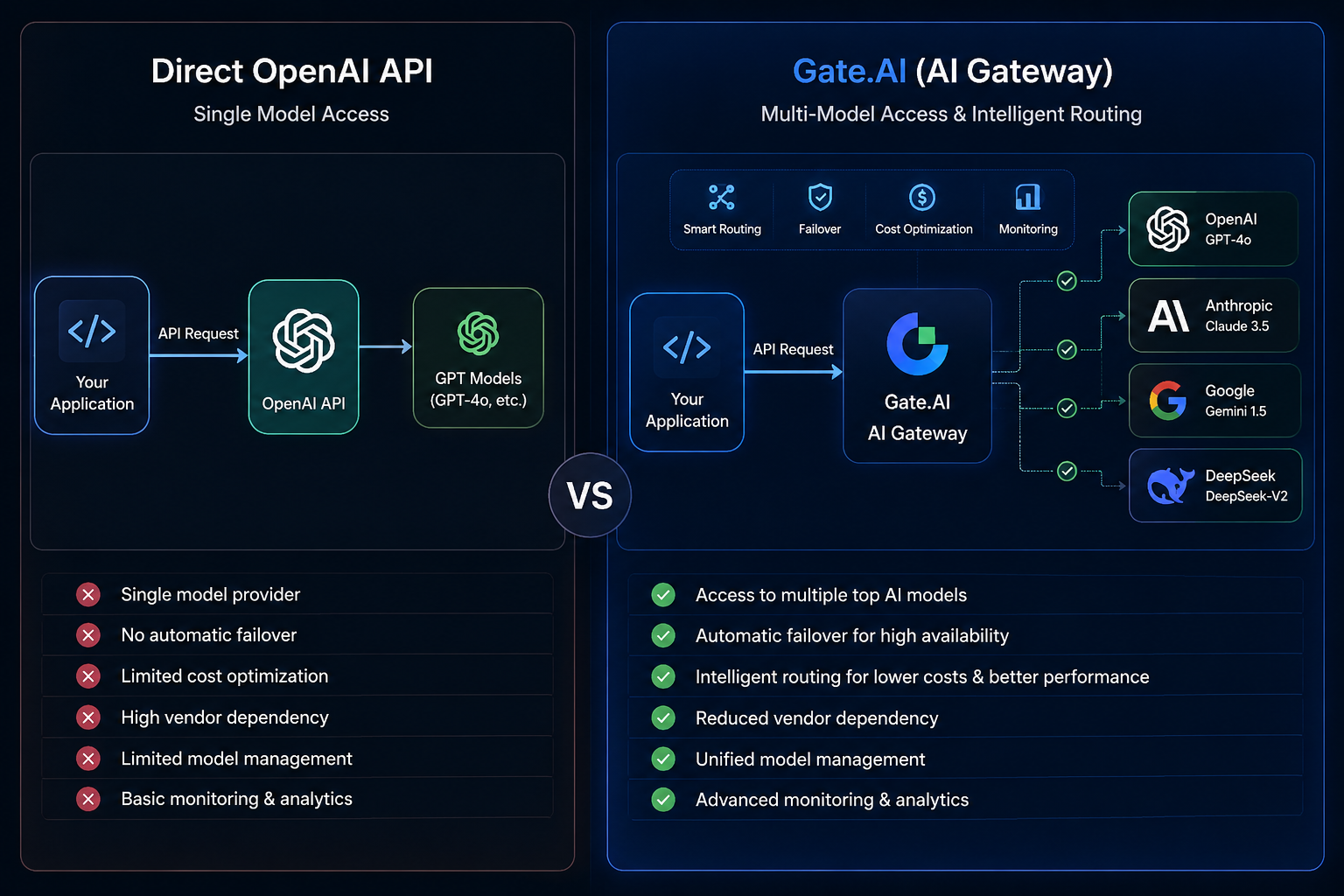
La API de OpenAI es una interfaz que permite a los desarrolladores invocar los modelos de la serie GPT mediante API estándar e integrarlos en chatbots, herramientas de generación de contenido, sistemas de búsqueda y aplicaciones automatizadas.
En este modelo, las aplicaciones envían solicitudes directamente a OpenAI, que devuelve los resultados de inferencia del modelo. La cadena de llamadas es relativamente sencilla: los desarrolladores solo necesitan gestionar la interfaz de un único proveedor para completar el despliegue.
Esta arquitectura resulta adecuada para la validación temprana de productos, aplicaciones que usan un solo modelo y escenarios con requisitos bien definidos. No obstante, a medida que el negocio crece, surgen limitaciones como una oferta de modelos reducida, una fuerte dependencia del proveedor y una capacidad de recuperación ante fallos insuficiente.
¿Qué es Gate.AI?
Gate.AI, una plataforma de enrutamiento de modelos para aplicaciones de IA y agentes de IA, conecta múltiples servicios de modelos de IA convencionales a través de una interfaz unificada.
A diferencia de la invocación directa a un único modelo, Gate.AI se sitúa entre la aplicación y los servicios de modelo, actuando como un IA Gateway que realiza enrutamiento de modelos, gobierno de solicitudes y conmutación entre modelos.
Los desarrolladores no necesitan crear interfaces independientes para cada modelo: acceden a todos ellos a través de un punto de entrada común. Cuando un modelo deja de estar disponible, el sistema puede cambiar automáticamente a otro siguiendo reglas predefinidas, lo que mejora la disponibilidad y la estabilidad generales.
¿Cómo difiere la cobertura de modelos entre la API de OpenAI y Gate.AI?
La cobertura de modelos constituye una de las diferencias más evidentes entre ambos enfoques.
Al invocar directamente la API de OpenAI, los desarrolladores acceden únicamente a los modelos proporcionados por OpenAI, sin posibilidad de usar otros servicios de modelo.
En cambio, Gate.AI está diseñado para agregar recursos de múltiples proveedores, lo que permite acceder a distintas capacidades de modelo desde una sola interfaz.
Por ejemplo, una aplicación puede emplear GPT para tareas de razonamiento complejo, Claude para análisis de textos extensos y DeepSeek para generación de código. Con la plataforma de enrutamiento de modelos, estas capacidades se gestionan de forma centralizada.
Este enfoque ayuda a evitar la dependencia de un único proveedor y aumenta la flexibilidad del sistema.
Diferencias arquitectónicas: AI Gateway frente a integración de un solo modelo
Desde el punto de vista arquitectónico, ambos sistemas operan en capas distintas de la infraestructura.
La invocación directa a la API de OpenAI conecta la capa de aplicación directamente con la capa de modelo:
Aplicación → API de OpenAI → Modelo GPT
Gate.AI introduce una capa intermedia de AI Gateway:
Aplicación → Gate.AI → Ecosistema multimodelo
Las funciones del AI Gateway van más allá del simple reenvío de solicitudes; también se encarga de:
- Enrutamiento de modelos
- Gobernanza de solicitudes
- Control de acceso
- Supervisión y auditoría
- Equilibrio de carga
- Recuperación ante fallos
Por tanto, no se trata de una mera sustitución, sino de dos patrones arquitectónicos distintos que adoptan sistemas de diferente complejidad.
¿Cómo difieren las capacidades de control de costes entre la API de OpenAI y Gate.AI?
A medida que las aplicaciones de IA ganan escala, el coste de las llamadas a los modelos se convierte en un factor determinante.
En una arquitectura de un solo modelo, todas las solicitudes se dirigen al mismo modelo, generando el mismo coste de inferencia incluso cuando la tarea no requiere el modelo más potente.
Una plataforma de enrutamiento de modelos puede seleccionar dinámicamente el modelo en función de la complejidad de la tarea.
Por ejemplo:
- Preguntas y respuestas sencillas: modelos ligeros
- Resumen de contenido: modelos medianos
- Razonamiento complejo: modelos de alto rendimiento
Esta programación por niveles mejora la utilización de los recursos y reduce el coste global de inferencia.
En consecuencia, las arquitecturas multimodelo suelen ofrecer un mayor potencial de optimización de costes que las arquitecturas de modelo fijo.
¿Cómo difieren la recuperación ante fallos y la disponibilidad entre la API de OpenAI y Gate.AI?
Las aplicaciones de IA exigen una estabilidad cada vez mayor.
Cuando los desarrolladores integran directamente un único servicio de modelo, las solicitudes pueden fallar si el servicio sufre una caída, supera el tiempo de espera o alcanza un límite de velocidad.
Una arquitectura de Gateway multimodelo permite la recuperación automática mediante un mecanismo de respaldo.
Si el modelo principal no responde, el sistema puede redirigir la solicitud a un modelo de respaldo de forma automática.
Este mecanismo reduce el riesgo de puntos únicos de fallo y garantiza la continuidad operativa del sistema.
Para agentes de IA o flujos de trabajo automatizados de larga duración, la conmutación por error entre modelos se ha convertido en una capacidad de infraestructura esencial.
Diferencias principales entre Gate.AI y la API de OpenAI
| Dimensión de comparación |
Gate.AI |
API de OpenAI |
| Posicionamiento |
AI Gateway y plataforma de enrutamiento de modelos |
Interfaz de servicio de modelo único |
| Fuente de modelos |
Ecosistema multimodelo |
Modelos de OpenAI |
| Cambio de modelo |
Compatible |
No compatible |
| Respaldo automático |
Compatible |
No compatible |
| Gestión centralizada |
Compatible |
Limitada |
| Optimización de costes |
Enrutamiento dinámico compatible |
Llamada a modelo fijo |
| Adaptabilidad para agentes de IA |
Alta |
Media |
| Dependencia del proveedor |
Baja |
Alta |
| Capacidad de ampliación |
Fuerte |
Relativamente limitada |
Escenarios adecuados para llamar directamente a la API de OpenAI
Para la validación de prototipos, proyectos pequeños y aplicaciones que dependen específicamente de los modelos GPT, la invocación directa a la API de OpenAI suele permitir un despliegue rápido con menor complejidad.
Cuando el sistema tiene un alcance reducido, los requisitos de modelo son únicos y las necesidades de recuperación ante fallos son bajas, la arquitectura de un solo modelo ofrece la ventaja de un bajo coste de implementación y un mantenimiento sencillo.
Escenarios más adecuados para usar Gate.AI
En productos de IA de larga duración, aplicaciones empresariales y sistemas de agentes de IA, las capacidades de gestión multimodelo suelen ser más importantes que las capacidades de un solo modelo.
Cuando el sistema requiere:
- Usar varios modelos simultáneamente
- Reducir la dependencia del proveedor
- Conmutación automática ante fallos
- Optimización de costes
- Gobernanza y supervisión centralizados
Una arquitectura de AI Gateway suele proporcionar mayor flexibilidad y escalabilidad.
Resumen
La diferencia entre Gate.AI y la invocación directa a la API de OpenAI se reduce, en esencia, a la diferencia entre una arquitectura de AI Gateway y una arquitectura de integración con un solo modelo.
La API de OpenAI ofrece acceso directo a un ecosistema de un único modelo, ideal para crear y desplegar aplicaciones de IA rápidamente. Gate.AI, por su parte, proporciona la infraestructura necesaria para la colaboración multimodelo, los sistemas de alta disponibilidad y los agentes de IA mediante enrutamiento de modelos y un mecanismo de Gateway unificado.
Preguntas frecuentes
¿Son competidores la API de OpenAI y Gate.AI?
No operan exactamente en el mismo plano. La API de OpenAI es un proveedor de servicios de modelo, mientras que Gate.AI es una plataforma de enrutamiento de modelos y AI Gateway que puede incluir los modelos de OpenAI como uno de sus recursos accesibles.
¿Gate.AI solo se conecta a los modelos de OpenAI?
No. El objetivo de Gate.AI es unificar el acceso a múltiples ecosistemas de modelos de IA, permitiendo a los desarrolladores acceder a diferentes capacidades desde una única interfaz.
¿Qué es un IA Gateway?
Un AI Gateway es una capa de infraestructura situada entre las aplicaciones y los modelos, encargada del reenvío de solicitudes, el enrutamiento de modelos, la gestión de permisos, la supervisión y la gobernanza, y la recuperación ante fallos.
¿Qué significa el mecanismo de respaldo?
El respaldo es un mecanismo automático de recuperación ante fallos. Cuando el modelo principal no está disponible, el sistema cambia a un modelo de respaldo para continuar procesando la solicitud, reduciendo así el riesgo de interrupción del servicio.
¿Usar un IA Gateway impide seleccionar un modelo directamente?
No. Un AI Gateway suele ser compatible tanto con el enrutamiento automático como con la selección manual del modelo por parte del desarrollador; ambos modos se pueden configurar según las necesidades específicas.









