Fuente: Wall Street Journal
16 de marzo de 2026, la conferencia GTC 2026 de NVIDIA abrió oficialmente, con el fundador y CEO Jensen Huang dando su discurso principal.
En esta conferencia considerada como la “peregrinación anual de la industria de la IA”, Huang explicó la transformación de NVIDIA de una “empresa de chips” a una “empresa de infraestructura y fábricas de IA”. Frente a las preocupaciones del mercado sobre la sostenibilidad del rendimiento y el espacio de crecimiento, Huang desglosó la lógica comercial subyacente que impulsa el crecimiento futuro: la “economía de la fábrica de tokens”.

Guía de rendimiento extremadamente optimista, “al menos 10 billones de dólares de demanda para 2027”
En los últimos dos años, la demanda global de computación de IA ha explotado exponencialmente. A medida que los grandes modelos evolucionan de “percepción” y “generación” a “razonamiento” y “ejecución (realización de tareas)”, el consumo de potencia de cálculo se ha disparado. Frente a los límites en pedidos y ingresos que el mercado observa con atención, Huang ofreció expectativas muy fuertes.
Huang afirmó claramente en su discurso:
Hace un año, dije que veíamos una demanda de 500 mil millones de dólares con alta confianza, cubriendo Blackwell y Rubin hasta 2026. Ahora, en este preciso momento, veo una demanda de al menos 1 billón de dólares para 2027.

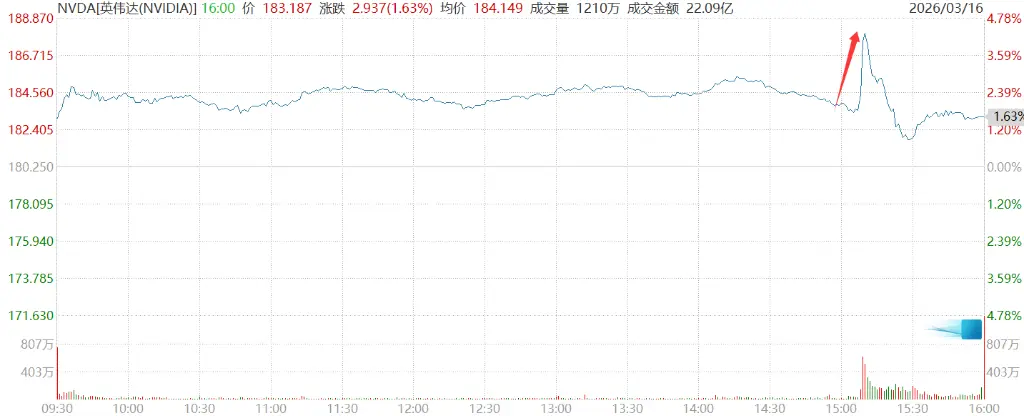
La expectativa de Huang de alcanzar un billón de dólares llevó en su momento a que las acciones de NVIDIA subieran más del 4.3%.
Además, añadió lo siguiente sobre esta cifra:
¿Es esto razonable? Eso es exactamente lo que voy a explicar a continuación. De hecho, incluso estaremos por encima de la demanda. Estoy seguro de que la demanda real de cálculo será mucho mayor.
Huang señaló que los sistemas de NVIDIA ya han demostrado ser la “infraestructura de menor costo” en todo el mundo. Debido a que NVIDIA puede ejecutar casi todos los modelos de IA en todos los ámbitos, esta versatilidad permite que los clientes aprovechen plenamente ese billón de dólares invertidos y mantengan un ciclo de vida largo.
Actualmente, el 60% del negocio de NVIDIA proviene de las cinco principales grandes nubes públicas, mientras que el otro 40% se distribuye ampliamente en nubes soberanas, empresas, industrias, robótica y computación en el edge.
Economía de la fábrica de tokens, el rendimiento por vatio determina la supervivencia comercial
Para explicar la razonabilidad de esta demanda de 1 billón, Huang presentó a los CEO de empresas de todo el mundo un nuevo pensamiento comercial. Señaló que, en el futuro, los centros de datos ya no serán almacenes de archivos, sino “fábricas” de tokens (la unidad básica generada por IA).

Huang enfatizó:
Cada centro de datos, cada fábrica, por definición, está limitada por la electricidad. Una fábrica de 1 GW (gigavatio) nunca se convertirá en 2 GW; esto es una ley física y atómica. Con una potencia fija, quien tenga la mayor cantidad de tokens procesados por vatio, tendrá los costos de producción más bajos.
Huang divide los servicios de IA futuros en los siguientes niveles comerciales:
Nivel gratuito (alto rendimiento, baja velocidad)
Nivel intermedio (~3 dólares por millón de tokens)
Nivel avanzado (~6 dólares por millón de tokens)
Nivel de alta velocidad (~45 dólares por millón de tokens)
Nivel ultra rápido (~150 dólares por millón de tokens)
Señaló que, a medida que los modelos crecen en tamaño y el contexto se extiende, la IA se vuelve más inteligente, pero la velocidad de generación de tokens disminuye. Huang afirmó:
En esta fábrica de tokens, tu rendimiento y velocidad de generación de tokens se traducirán directamente en tus ingresos precisos del próximo año.
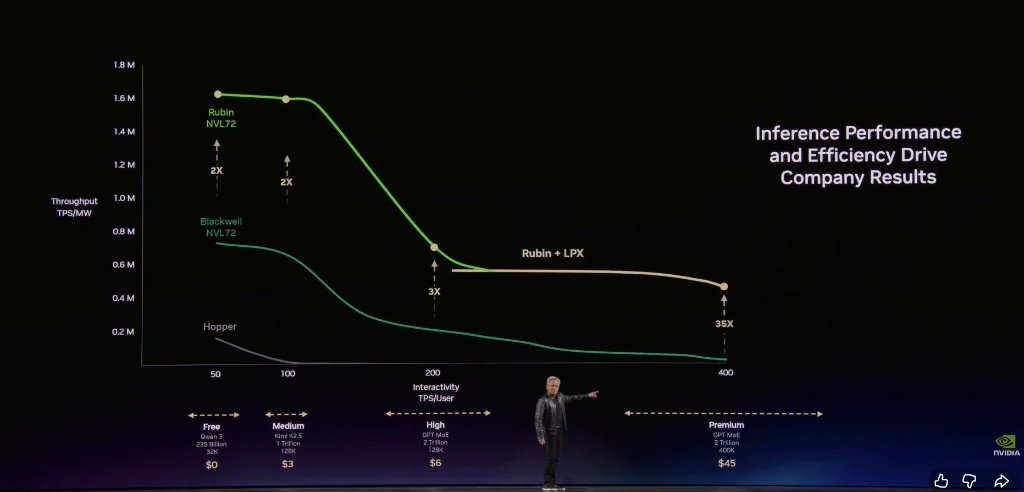
Huang destacó que la arquitectura de NVIDIA permite a los clientes lograr un rendimiento extremadamente alto en el nivel gratuito, mientras que en el nivel de inferencia de mayor valor, el rendimiento se incrementa en un sorprendente 35 veces.
Vera Rubin logra 350 veces de aceleración en dos años, Groq llena el vacío en inferencia ultrarrápida
Bajo las limitaciones físicas, NVIDIA presentó su sistema de cálculo de IA más complejo hasta la fecha, Vera Rubin. Huang dijo:
Cuando mencioné Hopper, levantaba un chip, y eso era adorable. Pero cuando hablo de Vera Rubin, la gente piensa en todo el sistema. En este sistema, completamente refrigerado por líquido y eliminando cables tradicionales, los racks que antes tomaban dos días en instalarse ahora solo necesitan dos horas.
Huang señaló que, mediante un diseño extremo de colaboración entre hardware y software, Vera Rubin ha logrado un salto de datos asombroso en un centro de datos de 1 GW:
En solo dos años, hemos aumentado la velocidad de generación de tokens de 22 millones a 700 millones, un crecimiento de 350 veces. La ley de Moore solo puede ofrecer un aumento de aproximadamente 1.5 veces en ese mismo período.
Para resolver el cuello de botella en inferencia ultrarrápida (como 1000 tokens/seg), NVIDIA presentó la solución final al integrar la adquisición de Groq: inferencia asimétrica y separada. Huang explicó:
Las características de estos dos procesadores son completamente diferentes. La chip de Groq tiene 500 MB de SRAM, mientras que una sola Rubin tiene 288 GB de memoria.

Huang indicó que, mediante el sistema de software Dynamo, NVIDIA delega la fase de “prellenado (Pre-fill)” y “decodificación” (que requiere mucha computación y memoria KV) a Vera Rubin, y la fase de “decodificación” de alta sensibilidad a la latencia (que requiere ancho de banda extremo y baja latencia) a Groq. Además, dio recomendaciones para la configuración de capacidad de cálculo empresarial:
Si tu trabajo principal es alto rendimiento, usa 100% Vera Rubin; si tienes una gran demanda de generación de tokens de alto valor, reserva un 25% del centro de datos para Groq.
Se reveló que el chip Groq LP30, fabricado por Samsung, ya está en producción en masa y se espera que comience a enviarse en el tercer trimestre, mientras que el primer rack Vera Rubin ya funciona en la nube de Azure de Microsoft.
Además, en cuanto a tecnología de interconexión óptica, Huang mostró el primer switch óptico empaquetado en masa del mundo, Spectrum X, y calmó las preocupaciones del mercado sobre la transición de cobre a fibra óptica:
Necesitamos más capacidad de cables de cobre, más chips ópticos y más capacidad de CPO.
Agent: el fin del SaaS tradicional, “salario + token” se convierte en el estándar de Silicon Valley
Además de las barreras de hardware, Huang dedicó mucho espacio a la revolución del software de IA y su ecosistema, especialmente a la explosión de los Agents (agentes inteligentes).
Describió el proyecto de código abierto OpenClaw como “el proyecto de código abierto más popular en la historia de la humanidad”, que en solo unas semanas superó los logros de Linux en 30 años. Huang afirmó directamente que OpenClaw es esencialmente el “sistema operativo” de las computadoras de agentes.
Huang afirmó:
Cada empresa de SaaS se convertirá en una empresa de AaaS (Agent-as-a-Service, agentes como servicio). Sin duda, para que estos agentes con acceso a datos sensibles y capacidad de ejecutar código sean seguros, NVIDIA ha lanzado el diseño de referencia empresarial NeMo Claw, que incluye un motor de políticas y un enrutador de privacidad.
Para los trabajadores comunes, esta transformación también está muy cerca. Huang describió la nueva forma de trabajo en el futuro:
En el futuro, cada ingeniero de nuestra empresa tendrá un presupuesto anual de tokens. Su salario base podría ser de decenas de miles de dólares, y además, les asignaré aproximadamente la mitad de esa cantidad en tokens, para que puedan multiplicar por 10 su eficiencia. ¿Qué tan importante será cuánto token tengan en su oferta de trabajo? Esa ya es una nueva estrategia de contratación en Silicon Valley.
Al final de su discurso, Huang “filtró” detalles sobre la próxima arquitectura de cálculo, Feynman, que logrará la primera expansión conjunta en nivel de cobre y CPO. Más aún, NVIDIA está desarrollando y desplegando en el espacio una computadora de centro de datos llamada Vera Rubin Space-1, abriendo la imaginación sobre la extensión del poder de cálculo de IA más allá de la Tierra.
Discurso completo de Huang en GTC 2026, con traducción completa (asistida por herramientas de IA):
Moderador: Bienvenidos a la presentación de Huang Renxun, fundador y CEO de NVIDIA.
Huang Renxun, fundador y CEO:
Bienvenidos a GTC. Quiero recordarles que esta es una conferencia tecnológica. Me alegra mucho ver a tanta gente haciendo fila desde temprano para entrar, y ver a todos ustedes aquí presentes.
En GTC, nos centraremos en tres temas principales: tecnología, plataforma y ecosistema. NVIDIA actualmente tiene tres plataformas principales: la plataforma CUDA-X, la plataforma de sistemas, y nuestra más reciente plataforma de fábricas de IA.
Antes de comenzar oficialmente, quiero agradecer a los anfitriones de nuestro evento previo—Sarah Guo de Conviction, Alfred Lin de Sequoia Capital (el primer inversor de riesgo de NVIDIA), y Gavin Baker, nuestro primer inversor institucional principal. Los tres tienen profundas perspectivas sobre tecnología y una influencia muy amplia en todo el ecosistema tecnológico. Por supuesto, también agradezco a todos los distinguidos invitados que he invitado personalmente a asistir hoy. Gracias a este equipo de estrellas.
También quiero agradecer a todas las empresas presentes. NVIDIA es una compañía de plataformas, con tecnología, plataformas y un ecosistema rico. Los representantes de las empresas aquí presentes representan casi a todos los participantes en la industria de 100 billones de dólares, con 450 empresas patrocinando este evento, a quienes agradezco sinceramente.
Este evento contará con 1,000 foros técnicos y 2,000 oradores, cubriendo cada nivel de la arquitectura de “las cinco capas” de la inteligencia artificial—desde infraestructura básica como tierra, electricidad y centros de datos, hasta chips, plataformas, modelos, y las diversas aplicaciones que impulsan toda la industria.
CUDA: 20 años de acumulación tecnológica
Todo comienza aquí. Este año marca el 20 aniversario de CUDA.
Durante veinte años, nos hemos dedicado al desarrollo de esta arquitectura. CUDA es una invención revolucionaria—la tecnología SIMT (Single Instruction Multiple Threads) permite a los desarrolladores escribir programas en código escalar y expandirlos a aplicaciones multihilo, mucho más sencilla que las arquitecturas SIMD anteriores. Recientemente, hemos añadido funciones Tiles para facilitar la programación de núcleos tensor (Tensor Cores), y diversas estructuras matemáticas en las que se basa la IA moderna. Actualmente, CUDA cuenta con miles de herramientas, compiladores, marcos y bibliotecas, con decenas de miles de proyectos públicos en la comunidad de código abierto, y está profundamente integrada en todos los ecosistemas tecnológicos.
Este gráfico revela toda la lógica estratégica de NVIDIA, y siempre he hablado de él desde el principio. La parte más difícil y central de lograrlo es la “capacidad instalada” en la parte inferior del gráfico. Tras veinte años, hemos acumulado en todo el mundo cientos de millones de GPUs y sistemas de cálculo que ejecutan CUDA.
Nuestras GPUs cubren todas las nubes, sirven a casi todos los fabricantes de computadoras y sectores. La enorme capacidad instalada de CUDA es la fuerza que impulsa este ciclo: atrae a los desarrolladores, quienes crean nuevos algoritmos y logran avances, estos avances generan nuevos mercados, que a su vez crean nuevos ecosistemas y atraen a más empresas, ampliando aún más la capacidad instalada—y así, el ciclo se acelera continuamente.
Las descargas de la biblioteca CUDA de NVIDIA crecen a un ritmo asombroso, con una escala enorme y en constante aumento. Este ciclo permite que nuestra plataforma de cálculo soporte aplicaciones masivas y nuevos avances sin fin.
Y lo más importante, otorga a estas infraestructuras una vida útil extremadamente larga. La razón es simple: las aplicaciones que corren en NVIDIA CUDA son muy diversas, cubren cada etapa del ciclo de vida de la IA, plataformas de procesamiento de datos, y diversos solucionadores científicos. Por eso, una vez que se instala una GPU de NVIDIA, su valor práctico es muy alto. Por eso, hace seis años, cuando lanzamos la arquitectura Ampere, el precio en la nube incluso subió.
Todo esto se debe a que la capacidad instalada es enorme, el ciclo de aceleración es fuerte, y el ecosistema de desarrolladores es amplio. Cuando estos factores trabajan juntos, y además actualizamos continuamente el software, los costos de cálculo disminuyen constantemente. La computación acelerada mejora significativamente el rendimiento de las aplicaciones, y a medida que mantenemos y actualizamos el software a largo plazo, los usuarios no solo obtienen saltos de rendimiento iniciales, sino que también disfrutan de una reducción continua en los costos de cálculo. Estamos dispuestos a brindar soporte a cada GPU en todo el mundo a largo plazo, porque su arquitectura es completamente compatible.
Hacemos esto porque la capacidad instalada es tan grande—cada vez que optimizamos, beneficiamos a millones de usuarios. Esta dinámica hace que la arquitectura de NVIDIA siga expandiéndose, acelerando su crecimiento, y reduciendo los costos de cálculo, estimulando nuevas formas de crecimiento. CUDA es el núcleo de todo esto.
De GeForce a CUDA: 25 años de evolución
Y nuestro viaje con CUDA comenzó en realidad hace 25 años.
GeForce—muchos aquí crecieron con GeForce. GeForce ha sido uno de nuestros mayores éxitos en marketing. Desde antes de que pudieran comprar nuestros productos, empezamos a cultivar a los futuros clientes—sus padres, en realidad, fueron los primeros en usar NVIDIA, comprando nuestros productos año tras año, hasta que un día, ustedes se convirtieron en científicos de la computación y en clientes y desarrolladores reales.
Este fue el legado que GeForce sentó hace 25 años. Hace ese tiempo, inventamos los shaders programables—una invención obvia pero profunda que permitió la programabilidad de los aceleradores, y fue la primera aceleradora programable del mundo, el pixel shader. Cinco años después, creamos CUDA—una de nuestras inversiones más importantes. En ese momento, la compañía tenía recursos limitados, pero apostamos la mayor parte de las ganancias en ello, dedicados a extender CUDA desde GeForce a cada computadora. Nuestra convicción era profunda, y a pesar de las dificultades iniciales, mantuvimos esa visión durante 13 generaciones, veinte años en total, y ahora CUDA está en todas partes.
Fue el pixel shader el que impulsó la revolución de GeForce. Y hace unos ocho años, lanzamos RTX—una transformación completa en la arquitectura para la era moderna de gráficos por computadora. GeForce llevó CUDA a todo el mundo, y gracias a eso, académicos como Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng y otros descubrieron que las GPUs podían acelerar el aprendizaje profundo, desencadenando la explosión de la IA hace una década.
Hace diez años, decidimos fusionar el shader programable con dos ideas nuevas: uno, el trazado de rayos en hardware (Ray Tracing), que fue un gran desafío técnico; y dos, una idea muy visionaria en ese momento—hace aproximadamente diez años, anticipamos que la IA revolucionaría por completo la forma en que se hacen los gráficos por computadora. Así como GeForce llevó la IA a todo el mundo, ahora la IA también está transformando la forma en que se implementan los gráficos por computadora.
Hoy, quiero mostrarles el futuro. Es nuestra próxima generación de tecnología gráfica, que llamamos renderizado neuronal (Neural Rendering)—una profunda integración de gráficos 3D e inteligencia artificial. Esto es DLSS 5, miren.
Renderizado neuronal: la fusión de datos estructurados y IA generativa
¿No es esto impresionante? Los gráficos por computadora cobran nueva vida.
¿Qué hemos hecho? Hemos combinado gráficos 3D controlables (la base de los mundos virtuales) con sus datos estructurados, y los hemos fusionado con IA generativa y cálculo probabilístico. Una es completamente determinista, la otra altamente probabilística y realista—hemos fusionado estas ideas, logrando precisión y control mediante datos estructurados, mientras generamos en tiempo real. El contenido resulta hermoso, impactante y totalmente controlable.
La idea de fusionar información estructurada con IA generativa se repetirá en muchas industrias. Los datos estructurados son la base para IA confiable.
Plataforma de aceleración para datos estructurados y no estructurados
Ahora, quiero mostrarles un diagrama de arquitectura tecnológica.
Los datos estructurados—todos conocen SQL, Spark, Pandas, Velox, y plataformas clave como Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery—todos trabajan con Data Frames. Estos Data Frames son como enormes hojas de cálculo, que contienen toda la información del mundo empresarial, y son la verdad fundamental (Ground Truth) para el cómputo empresarial.
En la era de la IA, necesitamos que la IA utilice datos estructurados y los acelere al máximo. Antes, acelerar el procesamiento de datos estructurados era para que las empresas funcionaran mejor. Pero en el futuro, la IA usará estos datos a velocidades mucho mayores que los humanos, y los agentes de IA harán un uso masivo de bases de datos estructuradas.
En cuanto a datos no estructurados, los bases de datos vectoriales, PDFs, videos, audios constituyen la mayor parte de los datos en el mundo—aproximadamente el 90% de los datos generados cada año son no estructurados. Antes, estos datos eran casi inutilizables: los leíamos, los almacenábamos en sistemas de archivos, y nada más. No podíamos consultarlos ni buscarlos fácilmente, porque carecían de índices simples y requerían entender su significado y contexto. Pero ahora, la IA puede hacerlo—mediante percepción multimodal y comprensión, la IA puede leer PDFs, entender su contenido y convertirlos en estructuras que se puedan consultar.
Para ello, NVIDIA ha creado dos bibliotecas fundamentales:
- cuDF: para acelerar el procesamiento de Data Frames y datos estructurados
- cuVS: para almacenamiento vectorial, datos semánticos y datos no estructurados de IA
Estas plataformas serán algunas de las bases más importantes del futuro.
Hoy, anunciamos colaboraciones con varias empresas. IBM—el inventor del lenguaje SQL—usará cuDF para acelerar su plataforma WatsonX Data. Dell y NVIDIA han co-creado la plataforma de datos AI de Dell, integrando cuDF y cuVS, logrando mejoras de rendimiento en proyectos reales de NTT Data. Google Cloud no solo acelera Vertex AI, sino también BigQuery, y colabora con Snapchat para reducir en casi un 80% sus costos de cálculo.
Los beneficios del cómputo acelerado son tres: velocidad, escala y costo. Esto sigue la lógica de la ley de Moore—lograr saltos en rendimiento mediante aceleración, y optimizar continuamente los algoritmos para reducir los costos de cálculo para todos.
NVIDIA ha construido una plataforma de cálculo acelerado, con muchas bibliotecas integradas: RTX, cuDF, cuVS, etc. Estas bibliotecas se integran en servicios en la nube global y en OEMs, llegando a usuarios en todo el mundo.
Colaboración profunda con proveedores de servicios en la nube
Colaboraciones con principales proveedores en la nube:
Google Cloud: aceleramos Vertex AI y BigQuery, integrados profundamente con JAX/XLA, y sobresalimos en PyTorch—NVIDIA es el único acelerador que funciona bien en PyTorch y JAX/XLA. Hemos llevado clientes como Base10, CrowdStrike, Puma, Salesforce al ecosistema de Google Cloud.
AWS: aceleramos EMR, SageMaker y Bedrock, con una integración profunda. Este año, lo que me emociona mucho, es que llevaremos OpenAI a AWS, lo que impulsará mucho el consumo en la nube de AWS, ayudando a OpenAI a expandir despliegues regionales y escalas de cálculo.
Microsoft Azure: la supercomputadora de 100 PFLOPS de NVIDIA, la primera en Azure, sentó las bases para colaborar con OpenAI. Aceleramos los servicios en la nube de Azure y AI Foundry, expandiendo las regiones de Azure, y colaborando estrechamente en Bing Search. Además, nuestra capacidad de “computación confidencial”—que garantiza que incluso los operadores no puedan ver los datos y modelos de los usuarios—es la primera GPU en el mundo que soporta esta función, permitiendo despliegues confidenciales de modelos de OpenAI y Anthropic en diferentes regiones en la nube. Por ejemplo, con Synopsys, aceleramos todos sus flujos de trabajo EDA y CAD, desplegados en Azure.
Oracle: somos el primer cliente de IA de Oracle, y me enorgullece haberles explicado por primera vez el concepto de IA en la nube. Desde entonces, han crecido rápidamente, y también hemos integrado a socios como Cohere, Fireworks, OpenAI, entre otros.
CoreWeave: la primera nube nativa de IA en el mundo, especializada en alojamiento de GPUs y servicios en la nube de IA, con una base de clientes excelente y un crecimiento fuerte.
Palantir + Dell: crearon una nueva plataforma de IA basada en la ontología de Palantir y en plataformas de IA, que puede desplegarse en cualquier país, en entornos aislados, de forma completamente local, desde procesamiento de datos (vectorial o estructurado) hasta toda la pila de cálculo acelerado de IA.
NVIDIA ha establecido este tipo de colaboraciones con los principales proveedores en la nube—introduciendo clientes en la nube, creando un ecosistema de beneficio mutuo.
Estrategia central: integración vertical y apertura lateral
NVIDIA es la primera compañía en integrar verticalmente y abrir lateralmente.
La necesidad es simple: el cómputo acelerado no es solo un problema de chips o sistemas, sino de aplicación acelerada. Los CPU hacen que las computadoras funcionen más rápido, pero esa vía ha llegado a un límite. En el futuro, solo mediante aceleración específica por aplicación o por dominio, se podrán seguir logrando saltos en rendimiento y reducción de costos.
Por eso, NVIDIA debe profundizar en cada biblioteca, en cada campo, en cada industria vertical. Somos una compañía de cálculo verticalmente integrada, sin otra opción. Necesitamos entender las aplicaciones, los dominios, los algoritmos, y poder desplegarlos en cualquier escenario—centros de datos, nube, local, edge, incluso robots.
Al mismo tiempo, mantenemos una apertura lateral, dispuestos a integrar nuestra tecnología en las plataformas de socios, para que todo el mundo pueda beneficiarse del cómputo acelerado.
La estructura de asistentes a GTC refleja esto claramente. La industria de servicios financieros tiene la mayor participación—los que vienen son desarrolladores, no traders. Nuestro ecosistema cubre toda la cadena de suministro, desde proveedores con 50, 70 o 150 años de historia, que tuvieron su mejor año el año pasado. Estamos en el inicio de algo muy, muy importante.
CUDA-X: motores de aceleración para cada industria
En cada sector vertical, NVIDIA ya tiene una presencia profunda:
- Conducción autónoma: cobertura amplia, impacto profundo
- Servicios financieros: la inversión cuantitativa pasa de ingeniería manual a aprendizaje profundo impulsado por supercomputadoras, en su “momento Transformer”
- Salud: llega su propio “momento ChatGPT”, incluyendo descubrimiento de fármacos asistido por IA, diagnósticos con agentes inteligentes, atención médica y soporte
- Industria: la mayor ola de construcción global, con fábricas de IA, fábricas de chips, centros de datos en marcha
- Entretenimiento y juegos: plataformas en tiempo real con traducción, streaming, interacción en juegos, y agentes de compras inteligentes
- Robótica: más de diez años de desarrollo, con tres arquitecturas principales (entrenamiento, simulación, en robots), con 110 robots en esta conferencia
- Telecomunicaciones: un sector de aproximadamente 2 billones de dólares, donde las estaciones base evolucionarán de funciones de comunicación a plataformas de infraestructura IA, con plataformas como Aerial, en colaboración con Nokia, T-Mobile y otros
Todos estos campos tienen en común las bibliotecas CUDA-X—el núcleo de NVIDIA como empresa de algoritmos. Estas bibliotecas son los activos más importantes, permitiendo que la plataforma de cálculo tenga un valor real en cada industria.
Una de las bibliotecas más importantes es cuDNN (CUDA Deep Neural Network Library), que revolucionó la IA y desencadenó la explosión moderna de la IA.
(Se reproduce un video de demostración de CUDA-X)
Todo lo que han visto hasta ahora es simulación—incluyendo solucionadores físicos, modelos físicos de agentes IA, y modelos físicos de robots. Todo es simulación, sin animaciones manuales ni articulaciones vinculadas. Esa es la capacidad central de NVIDIA: mediante una comprensión profunda de algoritmos y la integración con plataformas de cálculo, desbloqueamos estas oportunidades.
Empresas nativas de IA y la nueva era del cálculo
Han visto a gigantes como Walmart, L’Oréal, JPMorgan, Roche, Toyota, y también muchas empresas que ustedes nunca han oído—las llamamos empresas nativas de IA. Esta lista es enorme, incluyendo OpenAI, Anthropic, y muchas startups en diferentes verticales.
En los últimos dos años, esta industria ha experimentado un crecimiento asombroso. La inversión de riesgo en startups alcanzó 150 mil millones de dólares, un récord histórico. Y lo más importante, la escala de inversión individual pasó de millones a cientos de millones o miles de millones de dólares. La razón: por primera vez en la historia, cada una de estas empresas necesita una gran cantidad de recursos de cálculo y tokens. Este sector está creando, generando tokens, o valorizando tokens de instituciones como Anthropic y OpenAI.
Al igual que la revolución del PC, la revolución de Internet y la revolución móvil, esta transformación de plataformas de cálculo también dará lugar a empresas revolucionarias que serán fuerzas importantes en el futuro.
Tres avances históricos que impulsan todo esto
¿Qué ocurrió en los últimos dos años? Tres eventos principales.
Primero: ChatGPT, que inauguró la era de la IA generativa (finales de 2022 a 2023)
No solo percibe y comprende, sino que también genera contenido único. Mostré cómo la IA generativa se fusiona con gráficos por computadora. La IA generativa cambia fundamentalmente la forma en que se calcula—de un enfoque de recuperación a uno de generación, afectando profundamente la arquitectura, el despliegue y el significado general.
Segundo: IA de razonamiento (Reasoning AI), representada por o1
La capacidad de razonamiento permite a la IA reflexionar, planear y descomponer problemas—dividir problemas que no puede entender directamente en pasos manejables. o1 hace que la IA generativa sea confiable, capaz de razonar con información real. Para ello, la cantidad de tokens de entrada (contexto) y de salida (pensamiento) aumenta mucho, y el cálculo se dispara.
Tercero: Claude Code, el primer modelo de agente
Puede leer archivos, escribir código, compilar, probar y mejorar iterativamente. Claude Code revoluciona la ingeniería de software—todos los ingenieros de NVIDIA usan uno o más de Claude Code, Codex o Cursor, sin excepción, para potenciar su trabajo con IA.
Es un punto de inflexión: ya no solo se pregunta a la IA “qué es”, “dónde está” o “cómo hacerlo”, sino que se le pide que “cree”, “ejecute” y “construya”, usando herramientas, leyendo archivos, descomponiendo problemas y actuando. La IA ahora pasa de percepción a generación, razonamiento y acción concreta.
En los últimos dos años, el cálculo necesario para el razonamiento creció unas 10,000 veces, y el uso aumentó unas 100 veces. Siempre pensé que en esos dos años, la demanda de cálculo creció un millón de veces—una percepción compartida por todos, por OpenAI, por Anthropic. Cuanta más potencia de cálculo, más tokens se generan, más ingresos, y más inteligente se vuelve la IA. El punto de inflexión del razonamiento ya está aquí.
Era de infraestructura de IA de un billón de dólares
El año pasado, aquí mismo, expresé que confiábamos mucho en la demanda y pedidos de Blackwell y Rubin antes de 2026, con un tamaño de aproximadamente 500 mil millones de dólares. Hoy, un año después en GTC, digo que para 2027, veo esa cifra al menos en 1 billón de dólares. Y estoy seguro de que la demanda real será mucho mayor.
2025: el año de la inferencia de NVIDIA
2025 será el “Año de la Inferencia” de NVIDIA. Queremos asegurar que, además del entrenamiento y post-entrenamiento, podamos mantener un rendimiento sobresaliente en cada etapa del ciclo de vida de la IA, para que la infraestructura invertida siga funcionando eficientemente, y cuanto más larga sea su vida útil, menor sea el costo unitario.
Al mismo tiempo, Anthropic y Meta se unen oficialmente a la plataforma de NVIDIA, representando juntos un tercio de la demanda global de capacidad de IA. Los modelos de código abierto están alcanzando niveles de vanguardia, y están en todas partes.
NVIDIA es actualmente la única plataforma capaz de ejecutar todos los tipos de modelos de IA—de lenguaje, biología, gráficos, visión, voz, proteínas, química, robots—en cualquier entorno, en la nube o en el edge, en cualquier idioma. La arquitectura de NVIDIA es universal para todos estos escenarios, lo que nos convierte en la plataforma de menor costo y mayor confianza.
El 60% de nuestro negocio proviene de las cinco principales grandes nubes públicas, y el 40% restante se distribuye en nubes regionales, soberanas, empresas, industrias, robótica y edge. La amplitud de cobertura de IA en sí misma es una fortaleza—sin duda, esto es una transformación radical de la plataforma de cálculo.
Grace Blackwell y NVLink 72: innovaciones audaces en arquitectura
Mientras Hopper aún está en auge, decidimos reestructurar completamente el sistema, expandiendo NVLink de 8 a 72 canales, para una reconstrucción integral del sistema. Grace Blackwell NVLink 72 es una apuesta tecnológica enorme, y agradezco sinceramente a todos los socios por su apoyo.
Al mismo tiempo, lanzamos NVFP4—no solo FP4, sino un nuevo tipo de núcleo tensor y unidad de cálculo. Hemos demostrado que NVFP4 puede hacer inferencia sin pérdida de precisión, con mejoras de rendimiento y eficiencia energética significativas, y también es aplicable al entrenamiento. Además, nuevas algoritmos como Dynamo y TensorRT-LLM han llegado, y hemos invertido decenas de millones de dólares en construir un supercomputador llamado DGX Cloud para optimizar los núcleos.
Los resultados en rendimiento de inferencia son impresionantes. Datos de Semi Analysis—la evaluación más completa de rendimiento de inferencia IA—muestran que NVIDIA lidera en eficiencia por vatio y costo por token. La ley de Moore solo podría ofrecer un aumento de 1.5 veces en H200, pero logramos 35 veces. Dylan Patel de Semi Analysis incluso dice: “H. Huang ha sido conservador, en realidad es 50 veces.” Tiene razón.
Cito sus palabras: “Jensen ha subestimado (sandbagged).”
El costo por token de NVIDIA es el más bajo del mundo, sin competencia. La clave está en un diseño de co-diseño extremo (Extreme Co-design).
Por ejemplo, con Fireworks, antes de actualizar todo el software y algoritmos, la velocidad promedio era de unos 700 tokens por segundo; después, casi 5,000 tokens por segundo, un aumento de aproximadamente 7 veces. Esa es la fuerza del co-diseño extremo.
Fábrica de IA: de centros de datos a fábricas de tokens
Los centros de datos solían ser solo almacenamiento de archivos, ahora son fábricas de tokens. Cada proveedor de nube y cada empresa de IA en el futuro medirá su éxito en “eficiencia de fábrica de tokens”.
Mi argumento central:
- Eje vertical: rendimiento (Throughput)—tokens generados por segundo a potencia fija
- Eje horizontal: velocidad de interacción (Token Speed)—respuesta por inferencia, cuanto más rápido, mayor tamaño de modelo y contexto, más inteligente será la IA
El token será la nueva mercancía, y una vez maduro, tendrá precios en capas:
- Nivel gratuito (alto rendimiento, baja velocidad)
- Nivel intermedio (~3 dólares por millón de tokens)
- Nivel avanzado (~6 dólares por millón de tokens)
- Nivel de alta velocidad (~45 dólares por millón de tokens)
- Nivel ultra rápido (~150 dólares por millón de tokens)
En comparación con Hopper, Grace Blackwell aumenta en 35 veces el rendimiento en el nivel de mayor valor, e introduce nuevas capas. Con una estimación simplificada, distribuir un 25% de potencia a cada capa, Grace Blackwell puede generar 5 veces más ingresos que Hopper.
Vera Rubin: la próxima generación de sistemas de cálculo IA
(Se reproduce video de presentación de Vera Rubin)
Vera Rubin es un sistema completo, optimizado de extremo a extremo, diseñado para cargas de trabajo de agentes (Agentic):
- Núcleo de cálculo para modelos de lenguaje grandes: clúster de GPUs NVLink 72, para prellenado y KV Cache
- Nuevo CPU Vera: diseñado para rendimiento de un solo hilo extremo, con memoria LPDDR5, eficiencia energética sobresaliente, único en centros de datos con LPDDR5, ideal para llamadas a herramientas de agentes IA
- Sistema de almacenamiento: BlueField 4 + CX 9, plataforma de almacenamiento para la era IA, con participación del 100% en la industria del almacenamiento
- Switch óptico CPO Spectrum X: primer switch óptico empaquetado en masa del mundo, ya en producción
- Rack Kyber: nuevo sistema de racks, soporta 144 GPU en un solo dominio NVLink, con computación front-end y conmutación NVLink en back-end, formando una supercomputadora gigante
- Rubin Ultra: próxima generación de nodos de supercomputación, con diseño en vertical, compatible con el rack Kyber, para mayor escala NVLink
Vera Rubin ya es 100% refrigerado por líquido, con tiempos de instalación reducidos de dos días a solo dos horas, usando agua caliente a 45°C, reduciendo significativamente la carga de enfriamiento en centros de datos. Satya Nadella ya confirmó que la primera unidad Vera Rubin está en producción en Azure, y esto me emociona mucho.
Integración de Groq: extensión extrema en rendimiento de inferencia
Adquirimos el equipo de Groq y su tecnología. Groq es un procesador de flujo de datos determinista (Deterministic Dataflow Processor), que usa compilación estática y programación optimizada, con mucha SRAM, diseñado para cargas de inferencia de un solo trabajo, con latencia ultra baja y velocidad de generación de tokens muy alta.
Pero, la memoria de Groq es limitada (solo 500 MB de SRAM en chip), dificultando manejar modelos grandes y KV Cache de forma independiente, limitando su aplicación a gran escala.
La solución es Dynamo—un sistema de programación de inferencia. Con Dynamo, desacoplamos la canalización de inferencia:
- La fase de prellenado y atención (que requiere mucha computación y memoria KV) se realiza en Vera Rubin (requiere mucha potencia y memoria)
- La fase de decodificación (generación de tokens, muy sensible a la latencia) se realiza en Groq (requiere ancho de banda extremo y baja latencia)
Estas dos partes se acoplan mediante Ethernet, usando modos especiales para reducir la latencia en aproximadamente la mitad. Bajo Dynamo, la “sistema operativo de la fábrica de IA”, el rendimiento total aumenta 35 veces, abriendo nuevas capas de inferencia que antes no eran alcanzables con NVLink 72.
La combinación de Groq y Vera Rubin recomienda:
- Si la carga principal es alto rendimiento, usar 100% Vera Rubin
- Si hay muchas tareas de generación de tokens de alto valor, incluir Groq, con una proporción aproximada de 25% Groq y 75% Vera Rubin
El chip Groq LP30, fabricado por Samsung, ya está en producción, y se espera que comience a enviarse en el tercer trimestre. Gracias a Samsung por su apoyo.
Saltos históricos en rendimiento de inferencia
Cuantificando los avances: en solo 2 años, la velocidad de generación de tokens en una fábrica de IA de 1 GW pasará de 22 millones a 700 millones por segundo, un aumento de 350 veces. Esa es la fuerza del diseño de co-diseño extremo.
Hoja de ruta tecnológica
- Blackwell: en producción, sistema estándar Oberon, expansión de NVLink a 72 canales con cables de cobre, opción de expansión óptica a NVLink 576
- Vera Rubin (actual): rack Kyber, NVLink 144 (cobre); rack Oberon, NVLink 72 + óptico, expansión a NVLink 576; Spectrum 6, primer switch CPO del mundo
- Vera Rubin Ultra (próximo): nueva GPU Rubin Ultra, chip LP35 (con NVFP4 integrado), varias veces más potente
- Feynman (futuro): nueva GPU, chip LP40 (desarrollado en colaboración con Groq, con NVFP4); CPU Rosa (Rosalyn); BlueField 5; CX 10; soporte para expansión con cobre y CPO en el sistema de racks Kyber
La hoja de ruta muestra que las rutas de expansión con cobre, fibra óptica y CPO avanzan en paralelo, y necesitamos que todos los socios aumenten la producción en cobre, fibra y CPO.
NVIDIA DSX: plataforma digital de gemelos para fábricas de

