En résumé
- Google a déclaré que son algorithme TurboQuant peut réduire d’au moins six fois un important goulot d’étranglement de la mémoire dans l’IA sans perte de précision lors de l’inférence.
- Les actions liées à la mémoire, telles que Micron, Western Digital et Seagate, ont chuté après la diffusion du document.
- La méthode compresse la mémoire d’inférence, pas les poids du modèle, et n’a été testée que sur des benchmarks de recherche.
Google Research a publié mercredi TurboQuant, un algorithme de compression qui réduit d’au moins 6 fois un important goulot d’étranglement de la mémoire d’inférence tout en maintenant une précision zéro perte.
Le document doit être présenté à l’ICLR 2026, et la réaction en ligne a été immédiate.
Le PDG de Cloudflare, Matthew Prince, a qualifié cela de moment DeepSeek de Google. Le prix des actions liées à la mémoire, notamment Micron, Western Digital et Seagate, a chuté le même jour.
Alors, est-ce réel ?
L’efficacité de la quantification est déjà une grande réussite en soi. Mais « zéro perte de précision » doit être mis en contexte.
TurboQuant cible le cache KV — la partie de la mémoire GPU qui stocke tout ce dont un modèle de langage a besoin pour se souvenir lors d’une conversation.
À mesure que les fenêtres de contexte atteignent des millions de tokens, ces caches gonflent jusqu’à plusieurs centaines de gigaoctets par session. C’est le vrai goulot d’étranglement. Pas la puissance de calcul, mais la mémoire brute.
Les méthodes de compression traditionnelles tentent de réduire ces caches en arrondissant les nombres — par exemple, en passant de flottants 32 bits à 16, puis à 8 ou 4 bits entiers. Pour mieux comprendre, c’est comme réduire la résolution d’une image de 4K à Full HD, puis à 720p, etc. On peut dire que c’est la même image dans l’ensemble, mais avec plus de détails en résolution 4K.
Le problème : elles doivent stocker des « constantes de quantification » supplémentaires avec les données compressées pour éviter que le modèle ne devienne incohérent. Ces constantes ajoutent 1 à 2 bits par valeur, ce qui réduit partiellement les gains.
TurboQuant affirme éliminer totalement cet overhead.
Il le fait via deux sous-algorithmes. PolarQuant sépare la magnitude de la direction dans les vecteurs, et QJL (Johnson-Lindenstrauss quantifié) réduit l’erreur résiduelle à un seul bit de signe, positif ou négatif, sans stocker de constantes.
Le résultat, selon Google, est une estimation mathématiquement non biaisée pour les calculs d’attention qui alimentent les modèles transformateurs.
Dans des benchmarks utilisant Gemma et Mistral, TurboQuant a égalé la performance en précision totale sous 4x de compression, y compris une précision parfaite de récupération sur des tâches « aiguille dans une botte de foin » jusqu’à 104 000 tokens.
Pour comprendre pourquoi ces benchmarks sont importants, étendre le contexte utilisable d’un modèle sans perte de qualité a été l’un des plus grands défis dans le déploiement des LLM.
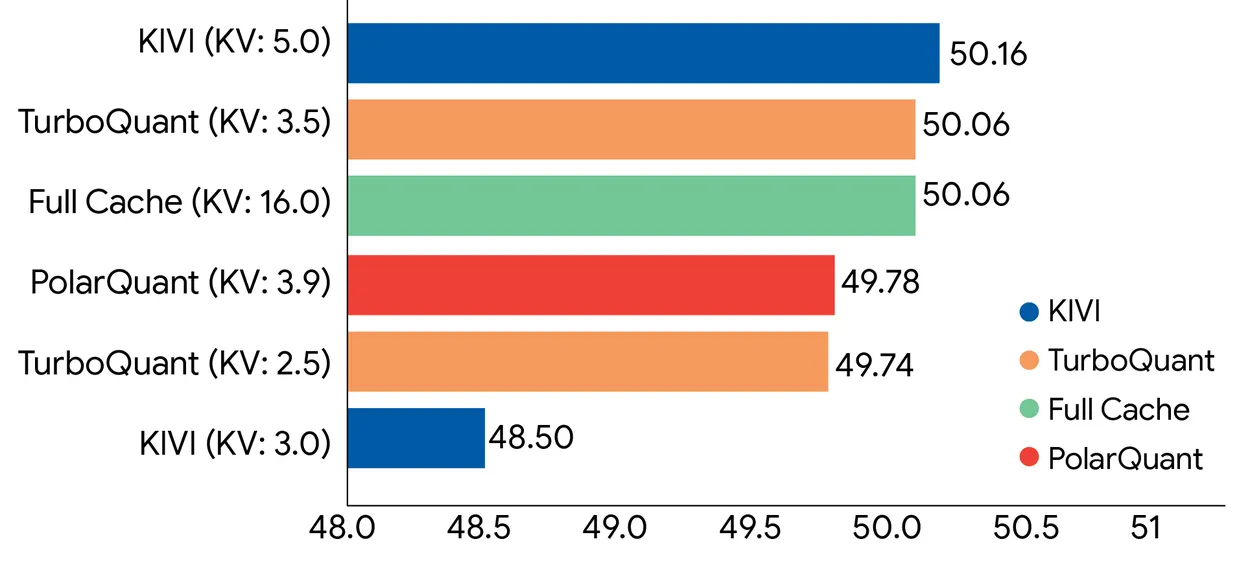
Maintenant, les détails fins.
« Zéro perte de précision » s’applique à la compression du cache KV lors de l’inférence — pas aux poids du modèle. La compression des poids est un problème complètement différent et plus difficile. TurboQuant ne touche pas à ces derniers.
Ce qu’il compresse, c’est la mémoire temporaire stockant les calculs d’attention en cours de session, ce qui est plus tolérant car ces données peuvent théoriquement être reconstruites.
Il y a aussi l’écart entre un benchmark propre et un système en production servant des milliards de requêtes. TurboQuant a été testé sur des modèles open-source — Gemma, Mistral, Llama — et non sur la propre stack Gemini de Google à grande échelle.
Contrairement aux gains d’efficacité de DeepSeek, qui nécessitaient des décisions architecturales profondes dès le départ, TurboQuant ne nécessite pas de réentraînement ou de réglages fins et revendique un overhead d’exécution négligeable. En théorie, il s’intègre directement dans les pipelines d’inférence existants.
C’est cette partie qui a effrayé le secteur du matériel mémoire — car si cela fonctionne en production, chaque grand laboratoire d’IA fonctionne avec moins de ressources sur les mêmes GPU qu’ils possèdent déjà.
Le document sera présenté à l’ICLR 2026. Jusqu’à sa mise en production, le titre « zéro perte » restera en laboratoire.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.
