En résumé
- ARC-AGI-3 révèle un écart massif entre les revendications d’AGI et la réalité, avec les meilleurs modèles d’IA obtenant moins de 1 % alors que les humains atteignent une performance parfaite.
- Le benchmark teste la véritable généralisation — exigeant des agents qu’ils explorent, planifient et apprennent de zéro dans des environnements inconnus plutôt que de se souvenir de modèles entraînés.
- Malgré le battage médiatique de l’industrie, les systèmes d’IA actuels restent loin de l’AGI, manquant de raisonnement et d’adaptabilité que même les jeunes humains manifestent naturellement.
Le PDG de Nvidia, Jensen Huang, est passé la semaine dernière sur le podcast de Lex Fridman et a déclaré, simplement : « Je pense que nous avons atteint l’AGI. » Deux jours plus tard, le test le plus rigoureux en recherche IA a publié son dernier benchmark d’intelligence générale artificielle — et tous les modèles de pointe ont obtenu moins de 1 %.
La Fondation du Prix ARC a lancé cette semaine ARC-AGI-3, et les résultats sont brutaux. Gemini 3.1 Pro de Google a mené avec 0,37 %. GPT-5.4 d’OpenAI a obtenu 0,26 %. Claude Opus 4.6 d’Anthropic a atteint 0,25 %, tandis que Grok-4.20 de xAI a scoré exactement zéro. Les humains, quant à eux, ont résolu 100 % des environnements.
Ce n’est pas un quiz ou un examen de codage, ni même des questions ultra-difficiles de niveau doctorat. ARC-AGI-3 est quelque chose de totalement différent de tout ce que l’industrie de l’IA a affronté auparavant.
Le benchmark a été créé par la fondation de François Chollet et Mike Knoop, qui a mis en place un studio de jeux interne et conçu 135 environnements interactifs originaux à partir de zéro. L’idée est de plonger un agent d’IA dans un monde de type jeu inconnu, sans instructions, sans objectifs déclarés, et sans description des règles. L’agent doit explorer, comprendre ce qu’il doit faire, élaborer un plan et l’exécuter.
Si cela ressemble à quelque chose qu’un enfant de cinq ans peut faire, vous commencez à comprendre le problème. Si vous souhaitez voir si vous êtes meilleur que l’IA, vous pouvez jouer aux mêmes jeux que ceux du test en cliquant sur ce lien. Nous en avons essayé un ; c’était étrange au début, mais après quelques secondes, on s’y habitue facilement.
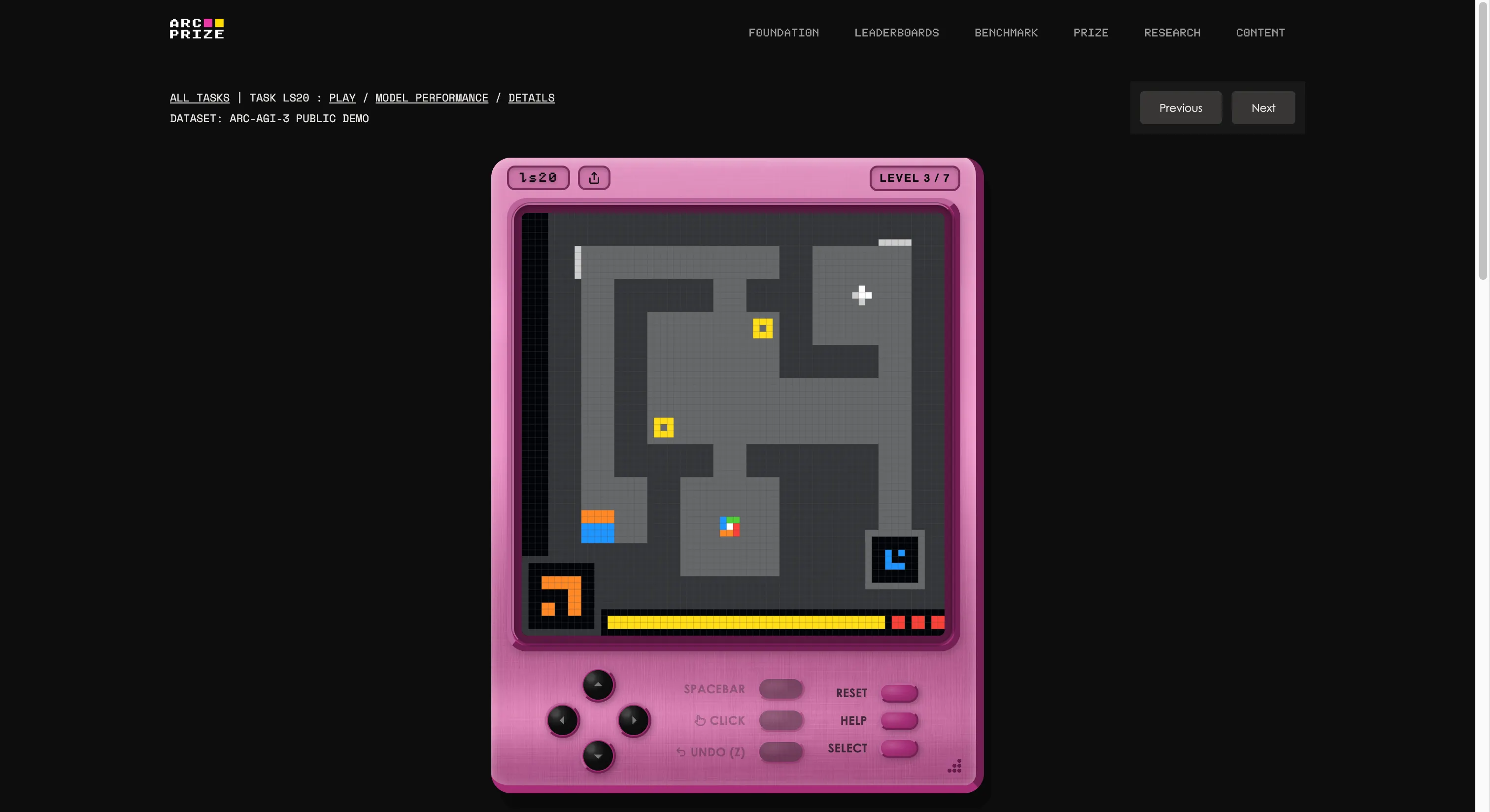
C’est aussi l’exemple le plus clair de ce que signifie le “G” dans AGI. Lorsqu’on généralise, on est capable de créer de nouvelles connaissances (comment fonctionne un jeu étrange) sans y avoir été entraîné à l’avance.
Les versions précédentes d’ARC testaient des puzzles visuels statiques — montrer un motif, prédire le suivant. Ils étaient difficiles au début. Ensuite, les laboratoires ont investi en puissance de calcul et en entraînement jusqu’à ce que ces benchmarks deviennent pratiquement obsolètes. ARC-AGI-1, introduit en 2019, s’est concentré sur l’entraînement en temps de test et les modèles de raisonnement. ARC-AGI-2 a duré environ un an avant que Gemini 3.1 Pro n’atteigne 77,1 %. Les laboratoires sont très efficaces pour saturer les benchmarks contre lesquels ils peuvent s’entraîner.
La version 3 a été conçue spécifiquement pour empêcher cela. Avec 110 des 135 environnements maintenus privés — 55 semi-privés pour les tests API, 55 entièrement verrouillés pour la compétition — il n’y a pas de dataset à mémoriser. On ne peut pas forcer une logique de jeu nouvelle qu’on n’a jamais vue.
Le score n’est pas non plus un simple réussi/échoué. ARC-AGI-3 utilise ce que la fondation appelle le RHAE — Efficacité Relative d’Action Humaine. La référence est la deuxième meilleure performance humaine lors de la première tentative. Un IA qui prend dix fois plus d’actions qu’un humain obtient 1 % pour ce niveau, pas 10 %. La formule amplifie la pénalité pour inefficacité. Errer, revenir en arrière et deviner pour trouver une solution est fortement pénalisé.
Le meilleur agent IA lors de la préversion d’un mois a obtenu 12,58 %. Les LLM de pointe testés via l’API officielle, sans outils personnalisés, n’ont pas réussi à dépasser 1 %. Les humains ordinaires ont résolu tous les 135 environnements sans entraînement préalable ni instructions. Si c’est le standard, alors la génération actuelle de modèles ne le dépasse pas.
Il y a un vrai débat méthodologique ici. Le rapport d’ARC indique qu’un système personnalisé développé par Duke a permis à Claude Opus 4.6 de passer de 0,25 % à 97,1 % sur une variante d’environnement appelée TR87. Cela ne signifie pas que Claude a obtenu 97,1 % sur l’ensemble d’ARC-AGI-3 ; son score officiel est resté à 0,25 %, mais ce changement mérite d’être noté.
Le benchmark officiel fournit aux agents du code JSON, pas des visuels. C’est soit une faille méthodologique, soit une démonstration que les modèles d’aujourd’hui sont meilleurs pour traiter des informations compréhensibles par l’humain que des données brutes structurées. La fondation de Chollet a reconnu le débat, mais ne modifie pas le format.
« La perception du contenu du cadre et le format API ne limitent pas la performance des modèles de pointe sur ARC-AGI-3 », indique le rapport. En d’autres termes, ils rejettent l’idée que les modèles échouent parce qu’ils « ne peuvent pas voir » correctement les tâches, arguant plutôt que la perception est déjà suffisante — et que le vrai écart réside dans le raisonnement et la généralisation.
Le constat sur la réalité de l’AGI est arrivé à un moment où la machine à hype tournait à plein régime. Outre le commentaire de Huang, Arm a nommé son nouveau processeur de centre de données le « CPU AGI ». Sam Altman d’OpenAI a déclaré qu’ils avaient « pratiquement construit l’AGI », et Microsoft commercialise déjà un laboratoire axé sur la construction d’un ASI : une évolution de ce qui vient après l’atteinte de l’AGI. Le terme est étiré jusqu’à ce qu’il signifie tout ce qui est commercialement pratique, semble-t-il.
La position de Chollet est plus simple. Si un humain normal sans instructions peut le faire, et que votre système ne peut pas, alors vous n’avez pas d’AGI — vous avez une autocomplétion très coûteuse qui nécessite beaucoup d’aide.
Le Prix ARC 2026 offre 2 millions de dollars répartis sur trois catégories de compétition, toutes hébergées sur Kaggle. Chaque solution gagnante doit être open source. Le temps presse, et pour l’instant, les machines ne sont même pas proches.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.
