AI Request Routing — це інфраструктурний функціонал для керування ресурсами багатомодельного інференсу. Оскільки великі мовні моделі, як-от GPT, Claude, Gemini та DeepSeek, постійно розвиваються, дедалі більше застосунків ШІ одночасно інтегрують кілька моделей. Питання інтелектуального вибору між різними моделями стало ключовим у проєктуванні систем штучного інтелекту.
Gate.AI розташований між застосунками та сервісами моделей, виконуючи функцію шлюзу ШІ та рівня маршрутизації моделей. Із утвердженням багатомодельних архітектур як галузевого стандарту маршрутизація моделей впливає не лише на продуктивність системи, а й на контроль витрат, стабільність сервісу та автономні можливості AI Agents.
Що таке маршрутизація запитів ШІ?
Як механізм диспетчеризації, що автоматично обирає цільову модель залежно від характеристик завдання, маршрутизація запитів ШІ в традиційних архітектурах зазвичай передбачає виклик застосунком однієї фіксованої моделі для виконання завдань інференсу. У багатомодельній архітектурі різні моделі пропонують різні переваги: здатність до міркування, генерацію коду, обробку довгих текстів або економічну ефективність.
Рівень маршрутизації моделей аналізує вміст запиту та надсилає його до найвідповіднішої моделі для виконання, підвищуючи загальне використання ресурсів.
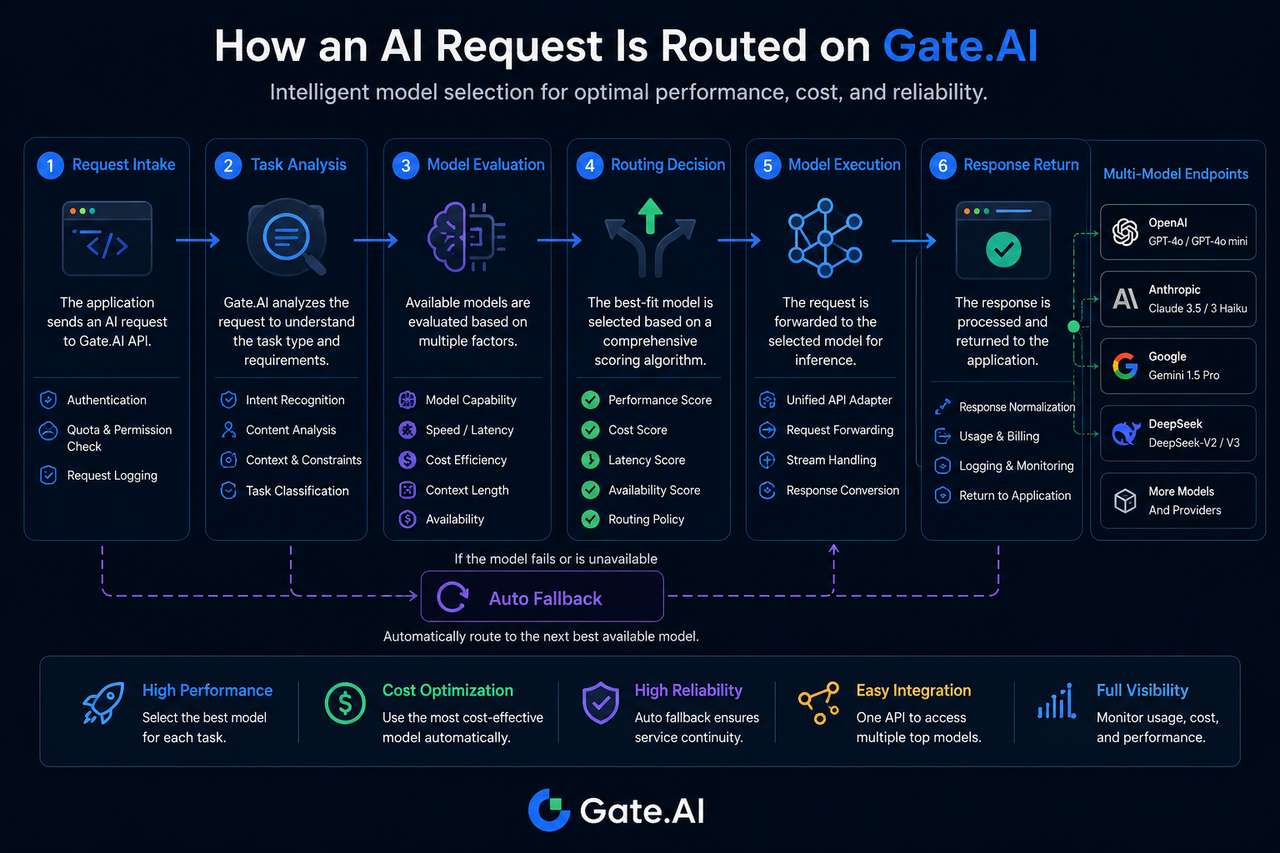
Крок 1: запит ШІ надходить до Gate.AI
Процес маршрутизації починається з фази доступу до запиту.
Коли застосунок надсилає запит, він спершу потрапляє на рівень шлюзу Gate.AI. На цьому етапі система перевіряє ідентифікаційні дані, дозволи доступу та фіксує параметри запиту.
Вміст запиту зазвичай включає:
- введення користувача
- конфігурацію моделі
- ліміти токенів
- вимоги до формату відповіді
- стратегію виклику
Після перевірки запит переходить до наступної фази аналізу.
Крок 2: система аналізує тип завдання
Ідентифікація завдання — ключовий компонент маршрутизації моделей.
Gate.AI визначає тип завдання на основі характеристик запиту, наприклад:
- загальна розмова
- підсумовування довгого тексту
- створення контенту
- генерація коду
- аналіз даних
- виклики інструментів AI Agent
Різні завдання мають суттєво різні вимоги до можливостей моделей.
Точна ідентифікація завдання робить подальший процес зіставлення моделей ефективнішим.
Крок 3: оцінка та зіставлення можливостей моделі
Фаза оцінки моделі визначає діапазон моделей-кандидатів.
Система звертається до бази даних можливостей моделей, щоб відфільтрувати поточні доступні моделі.
Критерії оцінки зазвичай включають:
- здатність до міркування
- довжина контексту
- швидкість відповіді
- здатність викликати інструменти
- підтримка мультимодальності
- рівень витрат
Наприклад, складні завдання міркування можуть надавати пріоритет моделям із сильнішими здатностями, тоді як завдання обробки довгих документів — моделям, що підтримують наддовгі вікна контексту.
Крок 4: формування рішення про маршрутизацію
Фаза прийняття рішення про маршрутизацію визначає остаточну модель виконання.
Після визначення моделей-кандидатів система оцінює їх, поєднуючи кілька метрик.
Поширені фактори, що враховуються:
Продуктивність моделі
Продуктивність моделі визначає якість виконання завдання.
Складні проблеми зазвичай потребують сильнішого логічного міркування, тоді як прості завдання можуть обходитися без найпродуктивнішої моделі.
Затримка відповіді
Швидкість відповіді безпосередньо впливає на досвід користувача.
Для сценаріїв взаємодії в реальному часі моделі з низькою затримкою часто отримують вищий пріоритет.
Вартість виклику
Витрати на інференцію варіюються залежно від моделі.
Коли кілька моделей можуть виконати одне й те саме завдання, система може надати пріоритет тій, яка має вищу ресурсну ефективність.
Доступність сервісу
Статус моделі також є важливим фактором у рішеннях про маршрутизацію.
Якщо модель має обмеження швидкості, стикається з помилками або перевантажена, система автоматично знижує її пріоритет.
Крок 5: запит надсилається до цільової моделі
Після прийняття рішення про маршрутизацію запит пересилається до цільової моделі.
На цьому етапі Gate.AI однаково обробляє відмінності інтерфейсів різних постачальників моделей.
Розробникам застосунків не потрібно створювати окремі інтерфейси для різних моделей.
Єдиний рівень доступу зменшує складність розробки та підвищує масштабованість системи.
Крок 6: модель генерує результат і повертає його
Після завершення інференції цільовою моделлю результат повертається до Gate.AI.
Gate.AI стандартизує відповідь, забезпечуючи узгоджені структури даних від різних моделей.
Уніфікований формат виведення зменшує роботу з адаптації на рівні застосунку та спрощує подальшу інтеграцію системи.
Кінцевий результат повертається до застосунку або AI Agent.
Що відбувається, коли цільова модель недоступна?
Недоступність моделі — поширене явище в багатомодельній екосистемі.
Якщо цільова модель вичерпала час очікування, має обмеження швидкості або виникають аномалії сервісу, Gate.AI може ініціювати процес автоматичного фолбеку.
Система повторно обирає резервну модель згідно з попередньо встановленими політиками для продовження виконання завдання.
Цей механізм знижує ризик єдиної точки відмови та підвищує загальну безперервність сервісу.
Докладніше про цей процес див. у статті «Що відбувається, коли модель ШІ виходить з ладу? Повний аналіз процесу автоматичного фолбеку Gate.AI».
Приклад процесу маршрутизації запитів ШІ
Наведений нижче приклад ілюструє типовий потік для завдання генерації контенту:
| Фаза |
Дія системи |
| Доступ до запиту |
Застосунок надсилає запит на генерацію |
| Аналіз завдання |
Визначено як створення довгого тексту |
| Фільтрація моделей |
Вибір моделей-кандидатів, що підтримують довгий контекст |
| Рішення про маршрутизацію |
Оцінка на основі продуктивності, вартості та затримки |
| Виконання моделі |
Запит надіслано до цільової моделі |
| Обробка результату |
Повернення стандартизованого виведення |
| Відновлення після збою |
Автоматичне перемикання на резервну модель у разі потреби |
Цей процес зазвичай завершується за дуже короткий час, і користувачі часто не помічають вибору моделі, що відбувається за лаштунками.
Підсумок
Як основна функція шлюзу ШІ, маршрутизація запитів ШІ динамічно обирає найвідповіднішу модель для виконання завдання серед кількох великих мовних моделей. Порівняно з фіксованим одномодельним викликом, маршрутизація моделей повністю використовує переваги різних моделей, підвищуючи гнучкість системи, стабільність та ефективність використання ресурсів.
В архітектурі Gate.AI запит ШІ проходить кілька етапів: доступ до запиту, ідентифікація завдання, оцінка моделі, рішення про маршрутизацію, виконання моделі та повернення результату.
Поширені запитання
Чому Gate.AI потребує маршрутизації моделей?
Gate.AI з'єднує екосистеми кількох моделей ШІ, де різні моделі відмінні у міркуванні, генерації коду, обробці довгих текстів та інших сферах. Маршрутизація моделей автоматично обирає найвідповіднішу модель відповідно до вимог завдання.
Чи може один запит ШІ викликати одночасно кілька моделей?
Зазвичай один запит ШІ виконується однією цільовою моделлю. Однак у деяких складних сценаріях може використовуватися шаблон багатомодельної колаборації, де різні моделі обробляють різні частини завдання.
Які фактори насамперед враховуються при прийнятті рішень про маршрутизацію ШІ?
Рішення про маршрутизацію ШІ зазвичай враховують кілька факторів: продуктивність моделі, швидкість відповіді, вартість інференції, довжина контексту, здатність виклику інструментів та доступність сервісу.
Яка різниця між маршрутизацією моделей та балансуванням навантаження?
Балансування навантаження насамперед стосується розподілу трафіку, тоді як маршрутизація моделей зосереджена на зіставленні можливостей моделей. Маршрутизація моделей обирає найвідповіднішу модель на основі характеристик завдання, а не просто розподіляє трафік запитів.








