À medida que os modelos de IA evoluem para multimodalidade, casos de utilização vertical e agentes inteligentes, o consenso na indústria transita de «quanto mais dados, melhor» para «dados de alta fidelidade, rastreáveis e em conformidade com a privacidade são o recurso escasso.» As plataformas de etiquetagem centralizadas tradicionais enfrentam estrangulamentos ao nível dos custos, da resposta à procura de cauda longa e da distribuição equitativa entre contribuidores. As redes de dados de IA descentralizadas procuram reorganizar as relações de produção de dados através de inteligência de enxame, coordenação por tokens e interfaces abertas. Compreender o funcionamento da Alaya AI exige uma análise aprofundada das suas camadas técnicas, pipeline de autoetiquetagem, lógica de amostragem e mecanismos económicos on-chain, sem a reduzir a um mero «serviço de etiquetagem externalizado alimentado por blockchain.»
Do ponto de vista da arquitetura industrial, a Alaya AI representa a convergência da Web3 e da IA na camada de dados: as contribuições de dados podem ser incentivadas, as permissões de tarefas transformadas em NFT e o desenvolvimento de modelos financiado através do apoio da comunidade via pool de staking de AGT, enquanto a Plataforma de Dados Abertos (ODP) faz a ponte entre oferta e procura. As secções seguintes decompõem a arquitetura central da rede, os mecanismos de aumento de eficiência, a integração Web3, os sistemas de staking e contribuição, as diferenças relativamente às plataformas tradicionais, os desafios reais e as direções futuras, oferecendo uma estrutura organizada para avaliar a sua viabilidade técnica e o valor do ecossistema.
Decomposição da arquitetura técnica central da Alaya AI
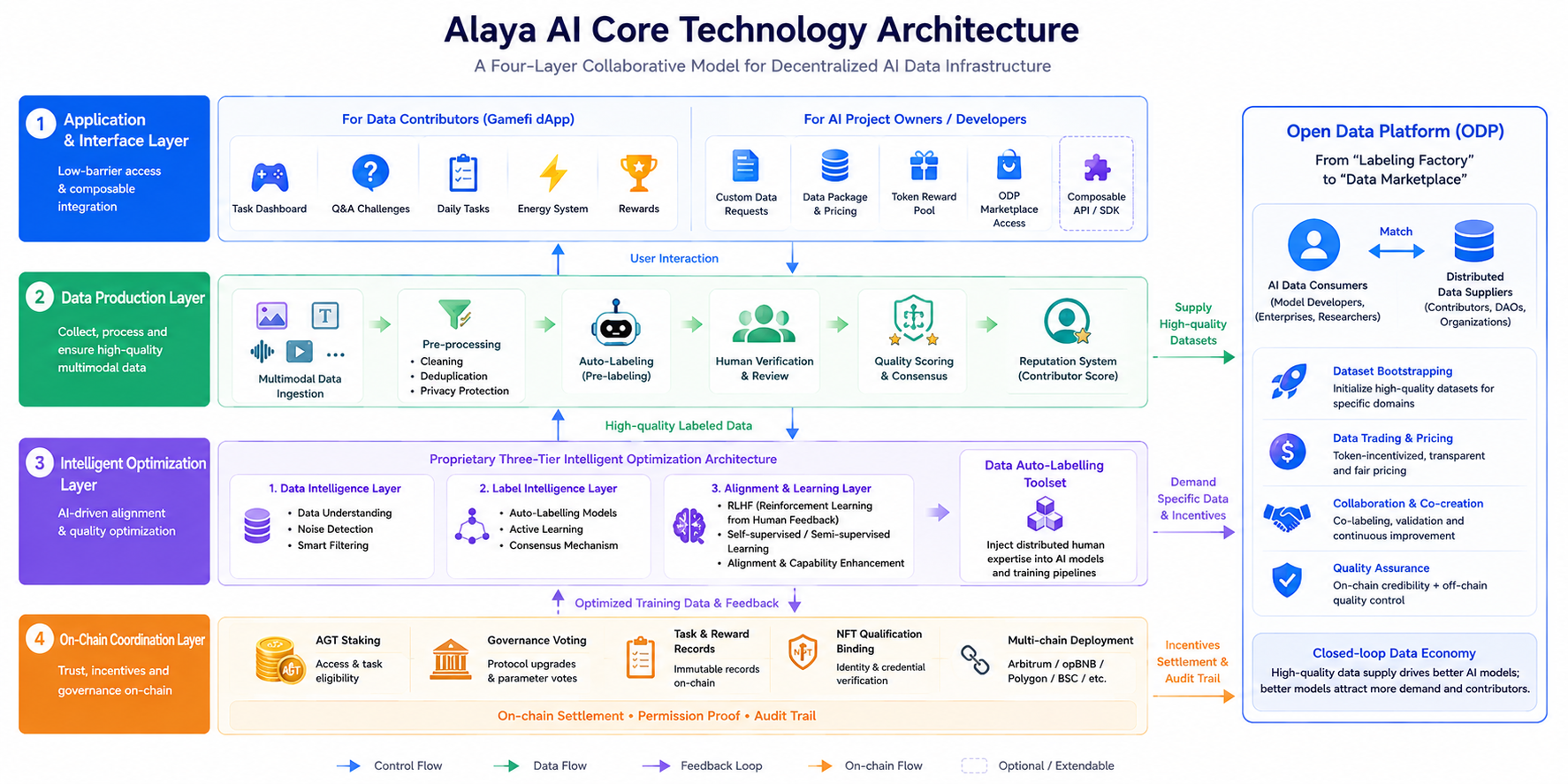
A arquitetura global da Alaya AI pode ser descrita como um modelo colaborativo de quatro camadas, onde cada camada tem responsabilidades claramente separadas com fluxos de dados e controlo distintos, evitando a sobrecarga de desempenho de «colocar tudo on-chain.»
-
Camada de aplicação e interface. Inclui um dApp gamificado para contribuidores de dados (com painéis de tarefas, desafios de questionários, tarefas diárias, etc.), bem como pedidos de dados personalizados, ofertas de pacotes de dados e a entrada no mercado ODP para equipas de projetos de IA. Esta camada enfatiza a participação de baixa barreira e o acesso composto, permitindo que os programadores publiquem necessidades de dados verticais através de pools de recompensa de tokens personalizados.
-
Camada de produção de dados. Responsável pela ingestão de dados multimodais (texto, imagens, vídeo, áudio), pré-processamento (limpeza, desduplicação, proteção da privacidade), autoetiquetagem, verificação manual e classificação de qualidade. A Alaya AI baseia-se em princípios de inteligência coletiva: a mesma tarefa pode ser etiquetada de forma cruzada por vários contribuidores, utilizando mecanismos de consenso ou maioria para melhorar a consistência das etiquetas, enquanto a precisão histórica forma uma reputação do contribuidor que influencia a alocação futura de tarefas.
-
Camada de Otimização Inteligente. O componente central é o Conjunto de Ferramentas de Autoetiquetagem de Dados, impulsionado por uma arquitetura de otimização inteligente de três camadas proprietária. Combinado com a afinação RLHF (Aprendizagem por Reforço a partir de Feedback Humano), injeta conhecimento humano distribuído em processos auto-supervisionados e semi-supervisionados, apoiando o alinhamento e a melhoria da capacidade do modelo.
-
Camada de Coordenação On-Chain. As informações de coordenação chave — como staking de AGT, votação de governança, registos de estado de tarefas e recompensas, e qualificação de NFT vinculativa — dependem da blockchain (as implementações do ecossistema abrangem várias cadeias, incluindo Arbitrum, opBNB, Polygon e BSC; consulte os anúncios oficiais para obter detalhes). A cadeia não armazena grandes volumes de dados brutos, mas trata da liquidação de incentivos, prova de permissão e ancoragem de trilha de auditoria, seguindo o paradigma comum de design de IA Web3 de «computação off-chain, confiança on-chain.»
A Plataforma de Dados Abertos (ODP), lançada em novembro de 2024, expande a rede de uma «fábrica de etiquetagem» para um «mercado de dados»: os consumidores de dados de IA e os fornecedores distribuídos conectam-se diretamente através de incentivos de tokens personalizáveis, apoiando a inicialização, negociação e colaboração de conjuntos de dados para criar um ciclo fechado de oferta e procura.
Como o sistema de autoetiquetagem melhora a eficiência dos dados de IA
A autoetiquetagem é um módulo central para a Alaya AI reduzir custos marginais e encurtar ciclos de entrega. O projeto posiciona-a como a próxima fase da evolução da IA auto-supervisionada: as máquinas geram primeiro etiquetas candidatas, depois os humanos concentram-se em amostras ambíguas e julgamentos específicos do domínio, em vez de etiquetar manualmente cada dado de raiz.
O processo técnico inclui normalmente os seguintes passos:
-
Ingestão Multimodal: O conjunto de ferramentas aceita dados visuais estáticos e dinâmicos, texto e entradas de sensores, que entram todos num pipeline de pré-processamento unificado.
-
Pré-processamento Algorítmico: São realizadas limpeza automática e desduplicação. A encriptação de conhecimento zero (encriptação ZK) é aplicada a caminhos de dados sensíveis, permitindo computação enquanto minimiza a exposição de texto simples, respondendo aos requisitos dos clientes empresariais em matéria de privacidade e conformidade.
-
Pré-etiquetagem do Modelo: Um modelo de autoetiquetagem proprietário gera etiquetas iniciais. Para categorias comuns de dados de IA, o projeto afirma uma taxa de verificação superior a 80%, com processamento em tempo real de fluxos visuais dinâmicos, o que é crítico para cenários como a etiquetagem de fotogramas de condução autónoma e vídeos de inspeção de qualidade industrial.
-
Ciclo de Otimização RLHF: Os resultados da verificação dos contribuidores são realimentados no modelo, reduzindo continuamente a proporção de revisão manual. A prática da indústria mostra que dentro de um ciclo RLHF, a intervenção humana pode ser focada em aproximadamente 20% das amostras de alta dificuldade, reduzindo significativamente os custos globais e os prazos (as proporções exatas variam consoante o tipo de tarefa).
-
Camada de Verdade de Especialistas: Para pedidos empresariais de alta fidelidade, a plataforma pode implementar uma equipa interna de especialistas no domínio (engenheiros, linguistas, especialistas visuais, etc.) como camada de arbitragem final, criando uma estrutura de via dupla «rendimento automatizado + precisão de especialista» em conjunto com os resultados de crowdsourcing. Os materiais de 2026 enfatizam também que os grandes volumes de dados ruidosos estão a tornar-se um estrangulamento operacional, e os dados verticais de alta fidelidade são o combustível essencial para os modelos e agentes de próxima geração.
O valor desta arquitetura híbrida reside em: a rede pública fornece escala e velocidade, enquanto o pipeline fechado de especialistas mantém os padrões de qualidade em indústrias sensíveis ao risco, evitando que a descentralização seja mal interpretada como «crowdsourcing de baixa qualidade.»
Como Funciona o Mecanismo de Amostragem Distribuída de Dados
Ao contrário da «raspagem aleatória total», a Alaya AI enfatiza a otimização inteligente e a amostragem direcionada: selecionar amostras com alta densidade de informação com base nos objetivos do modelo, aliviando o problema de «grande conjunto de dados, baixo sinal efetivo.»
O mecanismo de amostragem pode ser compreendido a partir de três dimensões:
-
Impulsionado pela Procura: Os clientes de IA submetem pedidos personalizados (por exemplo, dialetos específicos, imagens médicas especializadas, condições de trânsito regionais). A plataforma encaminha as unidades de trabalho para pools de contribuidores que correspondem ao nível NFT exigido, idioma ou formação profissional, conseguindo um alinhamento aproximado entre trabalho e tarefas.
-
Amostragem com Redundância de Grupo: Múltiplas pessoas etiquetam independentemente o mesmo lote de dados. A deteção de consistência identifica etiquetas discrepantes; as amostras de baixa consistência entram automaticamente numa fila de revisão ou canal de especialistas. Isto substitui a supervisão total de um único inspetor de qualidade por redundância distribuída.
-
Separação Dinâmica e Estática: As tarefas de imagem estática e as tarefas de fluxo de vídeo dinâmico utilizam estratégias de rendimento diferentes. A visão dinâmica pode integrar segmentação automática e etiquetagem ao nível do fotograma para reduzir os custos manuais por fotograma.
-
Amostragem Temporal e de Cenário: Os cenários oficiais incluem a utilização de tempo fragmentado (por exemplo, deslocações) para participar em tarefas ligeiras, convertendo mão de obra inativa em capacidade de produção de dados. Uma UI gamificada (pontos de experiência, valores de energia) sustenta a retenção a longo prazo, tornando a pool de amostragem contínua em vez de um sprint de crowdsourcing único.
A limpeza e desduplicação no pré-processamento reduzem o enviesamento da amostragem na origem: se amostras duplicadas, ficheiros corrompidos ou metadados incorretos entrarem no conjunto de treino, amplificam as alucinações e enviesamentos do modelo. Por conseguinte, a amostragem não é apenas sobre «quanto amostrar», mas também um esforço de engenharia sistemático que envolve «o que amostrar, quem o faz e como verificar.»
Como a Web3 e as Redes de IA se Combinam
Os atributos Web3 da Alaya AI não se limitam a «pagar com tokens», mas envolvem a tokenização, NFTização e governação dos elementos de coordenação chave da rede de dados.
-
Coordenação por Token: O token nativo AGT serve como limiar de staking, votação de governança, desbloqueio de tarefas avançadas, atualização de NFT e entrada para financiamento de pools de staking de modelos. O design de staking enfatiza o custo irrecuperável e a segurança. O projeto afirma explicitamente que o staking de AGT por si só não fornece rendimento passivo, evitando que capital especulativo perturbe os incentivos de qualidade da etiquetagem.
-
Permissões NFT: O Alaya NFT e o Medallion NFT formam um sistema de identidade de via dupla, determinando o tipo de tarefas acessíveis, limites de nível e sistemas de realização. As atualizações de alto nível consomem AGT em nodos específicos, vinculando a identidade on-chain ao trabalho offline.
-
Combinações de Incentivos Abertos: Os projetos podem usar AGT ou os seus próprios tokens para criar pools de dados personalizados, adaptando-se às preferências de liquidação das equipas de IA nativas da Web3. Os programadores pequenos e médios podem inicializar conjuntos de dados com custos de caixa mais baixos através da ODP.
-
Auditoria e Linhagem On-Chain: Para clientes empresariais, a plataforma enfatiza a integridade criptográfica de ponta a ponta e trilhas de auditoria imutáveis, tornando a linhagem dos dados rastreável para apoiar as revisões de conformidade.
-
Crescimento Social e Gamificação: Mecanismos como tarefas diárias, comissões de referência e Resgate Mensal de AGT (os utilizadores trocam créditos AIA obtidos em tarefas por AGT numa pool de resgate com prazo fixo) mapeiam periodicamente a atividade offline para a distribuição de valor on-chain.
-
Implementação Multi-Cadeia: Reduz o atrito para utilizadores em diferentes ecossistemas. A mesma rede de dados pode alcançar grupos de utilizadores na Arbitrum, opBNB, etc. O roadmap menciona também a expansão para BNB Chain, Optimism, etc., para se adaptar às diferenças de taxas e velocidade.
A narrativa do ecossistema de 2026 posiciona ainda a Alaya AI como a espinha dorsal de dados para Agentes de IA: os agentes necessitam de feedback humano contínuo e conhecimento de nicho, enquanto a crowdsourcing Web3 combinada com autoetiquetagem fornece um pipeline de feedback escalável. A sinergia com estruturas de agente interativas em tempo real (como as capacidades do tipo OpenClaw discutidas externamente) aponta para um futuro de ciclo duplo de «aprendizagem em tempo real + conjuntos de dados verificados em grande escala.»
Análise dos Sistemas de Staking de Modelos de IA e Contribuição de Dados
A Tokenização de Modelos de IA é um mecanismo chave que distingue a Alaya AI das plataformas de etiquetagem gerais: a comunidade pode financiar e fornecer trabalho de dados para o desenvolvimento e afinação de modelos específicos através da pool de staking de AGT, facilitando o alinhamento de «aqueles que contribuem com dados beneficiam das melhorias do modelo.»
-
Caminho do Contribuidor: Registar no dApp → Concluir tarefas básicas para construir reputação → Fazer staking de AGT para desbloquear tarefas de nível superior (verificação, calibração, colaboração de autoetiquetagem) → Obter multiplicadores de recompensa mais altos; simultaneamente, ganhar créditos AIA para participar no Resgate Mensal de AGT.
-
Caminho do Projeto: Publicar pedidos de dados personalizados na plataforma → Configurar pools de recompensa de tokens AGT ou de terceiros → A plataforma atribui tarefas a contribuidores correspondentes → Após autoetiquetagem e controlo de qualidade manual, entregar o conjunto de dados → Opcionalmente, listar ou negociar na ODP.
-
Lógica de Segurança do Staking: O AGT serve como ferramenta de coordenação de Proof-of-Stake, aumentando o custo económico de etiquetagem maliciosa e cultivo de volume. Combinado com o Medallion NFT, restringe ainda mais o acesso a tarefas de alto nível, protegendo pedidos de dados de alto valor.
-
Retorno de Valor: O plano oficial é utilizar as receitas do serviço de dados da plataforma para recomprar AGT e injetá-lo na pool de recompensa dos utilizadores, tentando fechar o volante de negócio «procura do cliente → receita → reincentivo → mais dados de qualidade.» O seu efeito real depende do volume de pedidos empresariais e da transparência da recompra.
Este sistema transforma a contribuição de dados de trabalho único numa colaboração em rede com participação: contribuidores, stakers e projetos competem e cooperam sob o mesmo conjunto de regras — uma estrutura Web3 que as plataformas SaaS de etiquetagem tradicionais não podem suportar nativamente.
| Dimensão |
Alaya AI |
Plataformas Tradicionais (ex: Scale AI, Labelbox) |
| Forma Organizacional |
Comunidade distribuída + Plataforma aberta |
Operações centralizadas e contratos empresariais |
| Incentivo |
AGT, AIA, NFT, Gamificação |
Principalmente compensação fiduciária |
| Personalização de Dados |
Pools de tokens personalizados, pedidos P2P |
Acordos de nível de serviço (SLA) e processos de aquisição padrão |
| Expressão de Propriedade |
NFT e registos on-chain enfatizam capital de contribuição |
Termos contratuais definem |
| Automação |
Autoetiquetagem de três camadas + RLHF + Revisão de especialistas |
Pipelines maduros, muitos casos verticais profundos (ex: automóvel) |
| Tipo de Cliente |
Nativos Web3 e equipas de IA pequenas/médias, expansão empresarial em curso |
Grandes empresas de tecnologia, projetos governamentais dominam |
As vantagens da Alaya AI residem na cauda longa, transfronteiriça, formação rápida de pools e incentivos transparentes. As plataformas tradicionais destacam-se na certeza de entrega, maturidade jurídica, certificações da indústria e experiência com projetos de megaescala. As redes descentralizadas não substituem os fornecedores centralizados em todos os cenários, mas estabelecem diferenciação na interseção de «sensível ao orçamento, nicho vertical, cripto-nativo.»
Além disso, a Alaya enfatiza dados verticais de alta fidelidade em vez de acumulação infinita de volume, diferindo da lógica tradicional de competição de «grande conjunto de dados.» Isto é mais favorável para pequenos modelos e agentes eficientes em termos de parâmetros, mas também exige que os clientes aceitem o modelo de preços e entrega de um pipeline híbrido (automático + especialista).
Desafios Enfrentados pelas Redes de Dados de IA Descentralizadas
Apesar da arquitetura completa, as redes de dados de IA descentralizadas enfrentam constrangimentos reais.
-
Equilíbrio entre Qualidade e Escala: Entre milhões de utilizadores registados, a proporção de etiquetadores consistentemente de alta qualidade é difícil de verificar externamente. Se os incentivos favorecerem o cultivo de volume, prejudicará as renovações dos clientes de IA e a reputação da rede.
-
Barreiras de Adoção Empresarial: Jurídico, SOC2, gestores de projeto dedicados, compensação de acidentes, etc., são requisitos de aquisição empresarial padrão. A transparência on-chain por si só é insuficiente para assinar grandes contratos; é necessário um acúmulo contínuo de casos auditáveis.
-
Complexidade da Experiência do Utilizador: Carteiras, NFT, tokens duplos (AGT/AIA), staking e regras de resgate aumentam o custo de aprendizagem para novos utilizadores, limitando potencialmente o influxo de contribuidores não Web3.
-
Incerteza Regulatória: Dados transfronteiriços, trabalho incentivado por tokens e conformidade para dados sensíveis como os de saúde variam consoante o país. As alterações políticas podem afetar as regiões operacionais e o design dos tokens.
-
Sustentabilidade dos Incentivos e Liquidez: A capitalização de mercado e o volume de negociação do AGT ainda são pequenos em relação ao mercado geral. Se as receitas da plataforma e as recompras não acompanharem a oferta de desbloqueio e resgate, os incentivos podem depender de novos utilizadores em vez de fluxo de caixa interno.
-
Riscos Técnicos: Vulnerabilidades de contratos inteligentes, erros de vinculação de carteira que impedem a recolha de resgates e amplificação de erros do modelo de autoetiquetagem em categorias de cauda longa exigem investimento contínuo em engenharia.
-
Pressão Competitiva: Os gigantes centralizados têm recursos profundos e elevada fidelidade de clientes. Outros projetos de dados Web3 também competem pela mesma narrativa, e a diferenciação deve ser comprovada com dados entregues.
Direções Futuras de Desenvolvimento da Tecnologia Alaya AI
Combinando o roadmap oficial e as dinâmicas de 2025–2026, a evolução técnica provavelmente concentrar-se-á nas seguintes direções.
-
Integração Profunda da Autoetiquetagem e RLHF: Melhorar as capacidades de processamento em tempo real para visão dinâmica, multilingue e dados de feedback de agentes, encurtando o ciclo de «recolher → etiquetar → reimplementar no modelo.»
-
ODP e Colaboração Social de Dados: Expandir da inicialização de conjuntos de dados para funcionalidades mais ativas de negociação, partilha e colaboração, melhorando os efeitos de rede.
-
DAO e Melhoria da Governança: Submeter mais decisões (ex: prioridades de funcionalidades de autoetiquetagem, parâmetros económicos) à votação dos stakers de AGT, aumentando a credibilidade das narrativas de soberania comunitária.
-
Sinergia Multi-Cadeia e Ecossistema de Computação: Integrar com DePIN, computação descentralizada (ex: Akash, Golem) e protocolos de mercado de modelos (ex: Bittensor), explorando a stack aberta «dados → treino → inferência» para reduzir o bloqueio de plataforma única.
-
Posicionamento na Era dos Agentes: Reforçar continuamente dados de alta fidelidade com humano no circuito como espinha dorsal de raciocínio para agentes; colaborar com estruturas de aprendizagem de agentes em tempo real para formar ciclos duplos rápido-lento.
-
Melhoria da Conformidade Empresarial: Expandir a encriptação ZK, a auditoria de linhagem e a cobertura de revisão de especialistas para ganhar pedidos em indústrias altamente regulamentadas como saúde e finanças.
Mecanismos como o Resgate Mensal de AGT em 2026 indicam que o lado operacional está a usar uma cadência fixa para manter as expectativas dos contribuidores. Se o lado técnico corresponde à cadência operacional depende do investimento sustentado na precisão da autoetiquetagem, nos algoritmos de encaminhamento de tarefas e na camada de especialistas.
Resumo
A rede de dados de IA descentralizada da Alaya AI é essencialmente um sistema de colaboração em camadas: a camada de aplicação reduz a barreira de participação, a camada de produção de dados melhora a eficiência com autoetiquetagem e amostragem distribuída, a camada de otimização inteligente absorve conhecimento humano através de RLHF, e a camada de coordenação on-chain alinha incentivos e segurança com AGT, NFTs e regras de governança. A Plataforma de Dados Abertos atualiza a rede de uma plataforma de tarefas para um mercado de dados composto, enquanto a pool de staking de modelos introduz capital e trabalho comunitário no ciclo de afinação do modelo.
O significado da sua lógica operacional para a indústria de IA é: quando os dados verticais de alta qualidade se tornam um estrangulamento, a aquisição centralizada por si só não consegue cobrir a cauda longa e a mão de obra fragmentada globalmente; a arquitetura Web3 oferece uma curva de oferta alternativa. Ao mesmo tempo, os desafios são reais — verificação de qualidade, SLAs empresariais, regulamentação e sustentabilidade dos incentivos determinarão se esta arquitetura técnica pode passar de «demonstrável» a «comercialmente escalável.»
Para observadores técnicos, avaliar a Alaya AI não deve olhar apenas para volumes de transações on-chain ou registos de utilizadores, mas também acompanhar indicadores concretos como taxas de verificação de autoetiquetagem, transações ODP, renovações de clientes empresariais e execução de recompras. Estes indicadores respondem coletivamente a uma questão: pode uma rede de dados de IA descentralizada superar simultaneamente os pontos fortes centrais das plataformas tradicionais em eficiência e confiabilidade?










