Fonte: 华尔街见闻
16 de março de 2026, a conferência GTC 2026 da Nvidia abriu oficialmente, com o fundador e CEO 黄仁勋 a fazer o discurso principal.
Nesta conferência considerada uma “peregrinação anual da indústria de IA”, 黄仁勋 explicou a transformação da Nvidia de uma “empresa de chips” para uma “empresa de infraestrutura e fábricas de IA”. Frente às questões mais preocupantes do mercado sobre a sustentabilidade de desempenho e espaço de crescimento, 黄仁勋 detalhou a lógica empresarial subjacente que impulsiona o crescimento futuro — a “economia de fábricas de tokens”.

Orientação de desempenho extremamente otimista, “demanda de pelo menos 1 trilhão de dólares até 2027”
Nos últimos dois anos, a demanda global por computação de IA explodiu exponencialmente. À medida que os grandes modelos evoluíram de “percepção” e “geração” para “raciocínio” e “ação (execução de tarefas)”, o consumo de poder de processamento aumentou drasticamente. Em relação ao limite de pedidos e receitas que o mercado tanto observa, 黄仁勋 apresentou expectativas muito fortes.
Durante o discurso, 黄仁勋 afirmou:
Nessa época do ano passado, eu disse que víamos uma demanda de 500 bilhões de dólares com alta confiança, cobrindo Blackwell e Rubin até 2026. Agora, neste exato momento, vejo uma demanda de pelo menos 1 trilhão de dólares até 2027.

A previsão de trilhões de 黄仁勋 impulsionou o preço das ações da Nvidia a subir mais de 4,3%.
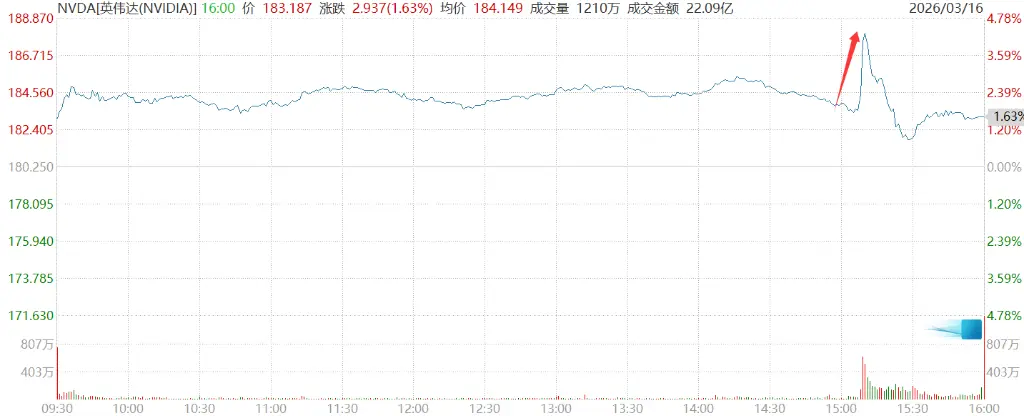
Além disso, ele complementou esse número:
Isso é razoável? É exatamente isso que vou falar a seguir. Na verdade, podemos até estar com oferta insuficiente. Tenho certeza de que a demanda real por computação será muito maior do que isso.
黄仁勋 destacou que os sistemas atuais da Nvidia já provaram ser a infraestrutura de menor custo globalmente. Como a Nvidia consegue rodar quase todos os modelos de IA em diversos setores, essa versatilidade permite que o investimento de 1 trilhão de dólares dos clientes seja plenamente aproveitado e mantenha uma longa vida útil.
Atualmente, 60% dos negócios da Nvidia vêm dos cinco maiores provedores de nuvem de grande porte, enquanto os outros 40% estão amplamente distribuídos por nuvens soberanas, empresas, indústrias, robótica e computação de borda.
Economia de fábricas de tokens, o desempenho por watt decide o destino do negócio
Para explicar a razoabilidade dessa demanda de 1 trilhão de dólares, 黄仁勋 apresentou uma nova mentalidade empresarial aos CEOs globais. Ele apontou que, no futuro, os data centers não serão mais armazéns de arquivos, mas “fábricas de tokens” — unidades básicas geradas por IA.

黄仁勋 enfatizou:
Cada data center, cada fábrica, por definição, é limitada pela energia. Uma fábrica de 1 GW (gigawatt) nunca se tornará de 2 GW; isso é uma lei física e atômica. Com potência fixa, quem tiver maior throughput de tokens por watt terá menor custo de produção.
黄仁勋 divide os serviços de IA do futuro em diferentes níveis comerciais:
Nível gratuito (alto throughput, baixa velocidade)
Nível intermediário (~3 dólares por milhão de tokens)
Nível avançado (~6 dólares por milhão de tokens)
Nível de alta velocidade (~45 dólares por milhão de tokens)
Nível ultra-rápido (~150 dólares por milhão de tokens)
Ele apontou que, à medida que os modelos ficarem maiores e o contexto mais longo, a IA ficará mais inteligente, mas a taxa de geração de tokens diminuirá. 黄仁勋 afirmou:
Dentro dessa fábrica de tokens, seu throughput e velocidade de geração de tokens irão diretamente se traduzir na sua receita exata no próximo ano.
黄仁勋 destacou que a arquitetura da Nvidia permite que clientes atinjam throughput extremamente alto na camada gratuita, enquanto na camada de inferência de maior valor, o desempenho é aumentado em impressionantes 35 vezes.
Vera Rubin alcança 350 vezes de aceleração em dois anos, Groq preenche a velocidade de inferência máxima
Sob a limitação física, a Nvidia apresentou seu sistema de computação de IA mais complexo até hoje, Vera Rubin. 黄仁勋 afirmou:
Quando menciono Hopper, levanto um chip, o que é adorável. Mas ao falar de Vera Rubin, as pessoas pensam no sistema completo. Nesse sistema totalmente líquido, que elimina cabos tradicionais, o rack que levava dois dias para ser instalado agora leva apenas duas horas.
黄仁勋 destacou que, por meio de um design extremo de hardware e software integrados, Vera Rubin criou uma revolução de dados dentro de um data center de 1 GW:
Em apenas dois anos, elevamos a taxa de geração de tokens de 22 milhões para 700 milhões por segundo, um crescimento de 350 vezes. A Lei de Moore, nesse mesmo período, trouxe apenas cerca de 1,5 vezes de aumento.
Para resolver o gargalo de largura de banda na inferência ultrarrápida (como 1000 tokens/seg), a Nvidia apresentou a solução final ao adquirir a Groq: inferência assimétrica e separada. 黄仁勋 explicou:
Esses dois processadores têm características completamente diferentes. A chip Groq possui 500MB de SRAM, enquanto um chip Rubin tem 288GB de memória.

黄仁勋 apontou que, por meio do sistema Dynamo de software, a Nvidia delega a fase de “pré-preenchimento (Pre-fill)” e “decodificação” (que são altamente sensíveis à latência) para Vera Rubin, enquanto a fase de “decodificação de token” de alta sensibilidade de latência fica a cargo do Groq. Ele também deu recomendações para a configuração de capacidade computacional empresarial:
Se seu trabalho principal for alto throughput, use 100% Vera Rubin; se precisar gerar muitos tokens de alto valor, reserve cerca de 25% do data center para Groq.
Os chips Groq LP30, fabricados pela Samsung, já estão em produção em volume, com previsão de entrega no terceiro trimestre, enquanto o primeiro rack Vera Rubin já opera na nuvem Azure da Microsoft.
Além disso, em relação à tecnologia de interconexão óptica, 黄仁勋 apresentou o primeiro switch óptico de encapsulamento conjunto (CPO) de produção em massa, Spectrum X, e acalmou as preocupações do mercado sobre a rota “cobre para fibra”:
Precisamos de mais capacidade de cabos de cobre, mais chips ópticos e mais capacidade de CPO.
Agent: o fim do SaaS tradicional, “salário anual + token” torna-se padrão em Silicon Valley
Além das barreiras de hardware, 黄仁勋 dedicou grande parte do discurso à revolução do software de IA e do ecossistema, especialmente o surgimento de Agent (agentes inteligentes).
Ele descreveu o projeto de código aberto OpenClaw como “o projeto de código aberto mais popular da história da humanidade”, afirmando que em poucas semanas superou as realizações do Linux em 30 anos. 黄仁勋 afirmou diretamente que o OpenClaw é, na essência, o “sistema operacional” dos computadores de agentes.
黄仁勋 declarou:
Cada empresa de SaaS se tornará uma empresa de AaaS (Agent-as-a-Service, agentes como serviço). Sem dúvida, para garantir a implementação segura de agentes capazes de acessar dados sensíveis e executar códigos, a Nvidia lançou o design de referência empresarial NeMo Claw, que inclui motor de estratégias e roteador de privacidade.
Para o trabalhador comum, essa transformação também está próxima. 黄仁勋 descreveu a nova forma de trabalho do futuro:
No futuro, cada engenheiro da nossa empresa precisará de um orçamento anual de tokens. Seu salário base pode ser de dezenas de milhares de dólares, e reservarei cerca de metade desse valor em tokens para eles, permitindo um aumento de 10x na produtividade. Essa já é uma nova moeda de recrutamento no Vale do Silício: quanto de tokens seu pacote de oferta inclui?
Ao final do discurso, 黄仁勋 “vazou” a arquitetura de computação de próxima geração, Feynman, que permitirá a expansão conjunta de cobre e CPO pela primeira vez. Ainda mais, a Nvidia está desenvolvendo e implantando um data center espacial chamado Vera Rubin Space-1, abrindo a imaginação para uma extensão do poder de computação de IA além da Terra.
Transcrição completa do discurso de 黄仁勋 na GTC 2026 (com auxílio de ferramentas de IA):
Moderador: Bem-vindo ao palco 黄仁勋, fundador e CEO da Nvidia.
黄仁勋, fundador e CEO:
Bem-vindos à GTC. Gostaria de lembrar a todos que esta é uma conferência tecnológica. É uma grande satisfação ver tantas pessoas na fila cedo de manhã, e ver todos vocês aqui presentes.
Na GTC, focaremos em três temas principais: tecnologia, plataforma e ecossistema. A Nvidia atualmente possui três grandes plataformas: a plataforma CUDA-X, a plataforma de sistemas, e nossa mais recente plataforma de fábricas de IA.
Antes de começar oficialmente, quero agradecer aos nossos anfitriões do pré-evento — Sarah Guo da Conviction, Alfred Lin da Sequoia Capital (nosso primeiro investidor de risco), e Gavin Baker, nosso primeiro grande investidor institucional. Essas três pessoas têm insights profundos em tecnologia e uma influência vasta no ecossistema tecnológico. Claro, também agradeço a todos os convidados especiais que convidei pessoalmente para estar aqui hoje. Uma equipe de estrelas.
Também quero agradecer às empresas presentes hoje. A Nvidia é uma empresa de plataformas, com tecnologia, plataformas e um ecossistema rico. Os representantes das empresas aqui presentes representam quase todos os participantes de uma indústria avaliada em 100 trilhões de dólares. São 450 empresas patrocinando este evento, meu sincero agradecimento.
Este evento conta com 1.000 fóruns técnicos e 2.000 palestrantes, cobrindo cada camada da arquitetura de “cinco camadas” de IA — desde infraestrutura básica como terra, energia e data centers, até chips, plataformas, modelos, e as aplicações que impulsionam toda a indústria.
CUDA: vinte anos de acumulação tecnológica
Tudo começa aqui. Este ano marca o 20º aniversário do CUDA.
Durante vinte anos, dedicamo-nos ao desenvolvimento dessa arquitetura. CUDA é uma invenção revolucionária — a tecnologia SIMT (Single Instruction Multiple Threads) permite que desenvolvedores escrevam código escalar e o expandam para aplicações multithread, com uma complexidade de programação muito menor do que as arquiteturas SIMD anteriores. Recentemente, adicionamos a funcionalidade Tiles, facilitando a programação de Tensor Cores, além de diversas operações matemáticas essenciais para IA. Hoje, o CUDA possui milhares de ferramentas, compiladores, frameworks e bibliotecas, com centenas de milhares de projetos de código aberto, profundamente integrados a todos os ecossistemas tecnológicos.
Este gráfico revela toda a lógica estratégica da Nvidia — sempre falei dele desde o começo. O elemento mais difícil de alcançar, e também o mais central, é a “capacidade instalada” na base, na parte inferior do gráfico. Após vinte anos, acumulamos centenas de milhões de GPUs e sistemas de computação rodando CUDA globalmente.
Nossas GPUs cobrem todas as nuvens, atendendo quase todos os fabricantes de computadores e setores. Essa vasta capacidade instalada é a força motriz que faz esse ciclo de crescimento acelerar continuamente. Capacidade instalada atrai desenvolvedores, que criam novos algoritmos e fazem avanços, esses avanços geram novos mercados, que por sua vez criam novos ecossistemas e atraem mais empresas, ampliando ainda mais a capacidade instalada — esse ciclo está em plena aceleração.
O número de downloads do repositório CUDA cresce a uma velocidade impressionante, com escala enorme e ritmo crescente. Esse ciclo permite que nossa plataforma de computação suporte aplicações massivas e novas descobertas constantes.
Mais importante, ela confere uma vida útil extremamente longa a essas infraestruturas. A razão é simples: aplicações rodando no NVIDIA CUDA são extremamente diversas, abrangendo todas as fases do ciclo de vida da IA, plataformas de processamento de dados, e solucionadores de princípios científicos. Assim, uma vez instalada uma GPU Nvidia, seu valor de uso real é altíssimo. É por isso que, mesmo seis anos após o lançamento da arquitetura Ampere, o preço na nuvem continua a subir.
Tudo isso se sustenta pelo fato de a capacidade instalada ser enorme, o ciclo de aceleração ser forte, e o ecossistema de desenvolvedores ser amplo. Quando esses fatores atuam juntos, e nós continuamos atualizando o software, os custos de computação caem continuamente. Acelerando o processamento, melhoramos o desempenho das aplicações, e ao longo do tempo, ao manter e iterar o software, os usuários não só obtêm saltos de desempenho iniciais, mas também desfrutam de custos de computação cada vez menores. Estamos dispostos a oferecer suporte de longo prazo a cada GPU globalmente, pois elas são compatíveis na arquitetura.
Fazemos isso porque a capacidade instalada é gigantesca — toda vez que lançamos uma otimização, ela beneficia milhões de usuários. Essa combinação dinâmica amplia nossa cobertura, acelera nosso crescimento, e reduz continuamente os custos de cálculo, estimulando novas ondas de crescimento. O CUDA é o núcleo de tudo isso.
De GeForce a CUDA: vinte e cinco anos de evolução
Nossa jornada com CUDA começou há, na verdade, vinte e cinco anos.
GeForce — muitos aqui cresceram com ela. GeForce foi o projeto de marketing mais bem-sucedido da Nvidia. Desde o início, cultivamos futuros clientes antes mesmo de eles poderem comprar nossos produtos — os pais de vocês, ao comprarem nossos primeiros produtos, se tornaram os primeiros usuários da Nvidia, ano após ano, até que vocês se tornaram cientistas da computação de verdade, clientes e desenvolvedores.
Essa base foi estabelecida há vinte e cinco anos, com a invenção do shader programável — uma inovação óbvia, mas de grande impacto, que permitiu a aceleradores se tornarem programáveis, sendo a primeira GPU programável do mundo, o pixel shader. Cinco anos depois, criamos o CUDA — um dos maiores investimentos da Nvidia. Na época, a empresa tinha recursos limitados, mas apostamos grande na CUDA, estendendo-a do GeForce para todas as máquinas. Nossa convicção era profunda, e persistimos por 13 gerações, vinte anos, até que hoje, CUDA está onipresente.
Foi o pixel shader que revolucionou o GeForce. E cerca de oito anos atrás, lançamos a RTX — uma revolução completa na arquitetura de gráficos de computadores modernos. O GeForce levou o CUDA ao mundo, e foi assim que pesquisadores como Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng descobriram que GPUs podem acelerar profundamente o aprendizado de máquina, desencadeando a explosão de IA há uma década.
Há dez anos, decidimos fundir o shader programável com duas ideias inovadoras: uma, o Ray Tracing (traçado de raios), extremamente desafiador tecnicamente; e outra, uma visão avançada de uma década atrás — prever que a IA revolucionaria completamente a computação gráfica. Assim como o GeForce trouxe IA ao mundo, a IA agora irá transformar a forma de realizar gráficos de computador.
Hoje, quero mostrar o futuro. Nossa próxima geração de tecnologia gráfica, chamada Neural Rendering — uma fusão profunda de gráficos 3D e IA. Este é o DLSS 5, veja.
Neural Rendering: a fusão de dados estruturados e IA generativa
Incrível, não é? Os gráficos de computador ganham nova vida.
O que fizemos? Combinamos gráficos 3D controláveis (a base da realidade virtual) com seus dados estruturados, e os integramos à IA generativa e ao cálculo probabilístico. Uma abordagem totalmente determinística, outra altamente probabilística e realista — fundimos essas ideias, usando dados estruturados para controle preciso, enquanto geramos conteúdo em tempo real. Assim, o conteúdo fica bonito, impressionante, e totalmente controlável.
A fusão de dados estruturados com IA generativa será repetida em diversos setores. Dados estruturados são a base para IA confiável.
Plataforma de aceleração de dados estruturados e não estruturados
Agora, uma visão da arquitetura técnica.
Dados estruturados — todos conhecem SQL, Spark, Pandas, Velox, além de plataformas como Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery — lidam com Data Frames. Esses Data Frames são como planilhas gigantes, contendo toda a informação do mundo dos negócios, a verdade fundamental (Ground Truth).
Na era da IA, precisamos que a IA use esses dados estruturados com máxima velocidade. Antes, acelerar o processamento de dados estruturados era para tornar as empresas mais eficientes. Agora, a IA usará esses dados a uma velocidade muito maior que os humanos, e os agentes de IA irão consultar bancos de dados estruturados em grande escala.
Quanto aos dados não estruturados, eles incluem bancos de vetores, PDFs, vídeos, áudios — a maior parte dos dados do mundo. Cada ano, cerca de 90% dos dados gerados são não estruturados. Antes, esses dados eram quase inúteis: apenas os armazenávamos em arquivos, sem poder consultá-los ou indexá-los facilmente, pois faltava uma maneira simples de entender seu significado e contexto. Agora, a IA consegue fazer isso — usando percepção multimodal e compreensão, ela pode ler PDFs, entender seu conteúdo, e incorporá-los a estruturas maiores para consulta.
Para isso, a Nvidia criou duas bibliotecas fundamentais:
- cuDF: para processamento acelerado de Data Frames e dados estruturados
- cuVS: para armazenamento vetorial, dados semânticos e não estruturados de IA
Essas plataformas serão uma das bases mais importantes do futuro.
Hoje, anunciamos parcerias com várias empresas. IBM — inventora da linguagem SQL — usará cuDF para acelerar sua plataforma WatsonX Data. Dell criou conosco a plataforma de dados de IA Dell, integrando cuDF e cuVS, com melhorias de desempenho em projetos reais da NTT Data. Google Cloud, além de acelerar Vertex AI, também acelera BigQuery, e colaborou com Snapchat para reduzir quase 80% os custos de computação.
Os benefícios do processamento acelerado são três: velocidade, escala e custo. Seguem a lógica de Moore: acelerar o processamento para obter saltos de desempenho, enquanto otimizamos algoritmos para reduzir custos continuamente.
A Nvidia construiu uma plataforma de computação acelerada, com diversas bibliotecas — RTX, cuDF, cuVS, etc. Essas bibliotecas estão integradas aos provedores de nuvem globais e OEMs, alcançando usuários em todo o mundo.
Parcerias profundas com provedores de nuvem
Colaborações com principais provedores de nuvem:
Google Cloud: aceleramos Vertex AI e BigQuery, integrando profundamente com JAX/XLA, além de excelente desempenho no PyTorch — a Nvidia é a única aceleradora que funciona bem em PyTorch e JAX/XLA. Levamos clientes como Base10, CrowdStrike, Puma, Salesforce para o ecossistema Google Cloud.
AWS: aceleramos EMR, SageMaker e Bedrock, com forte integração. Este ano, estou especialmente animado: vamos levar o OpenAI para a AWS, impulsionando o consumo de nuvem AWS, ajudando o OpenAI a expandir sua implantação regional e escala de computação.
Microsoft Azure: o supercomputador de 100 PFLOPS da Nvidia foi a primeira máquina de alta performance implantada na Azure, estabelecendo uma parceria importante com o OpenAI. Aceleramos os serviços Azure e a plataforma AI Foundry, expandindo regiões Azure, e colaborando profundamente na busca do Bing. Nosso recurso de “Computação Confidencial” — que garante que nem mesmo o provedor de serviços possa ver os dados ou modelos do usuário — é suportado pelos primeiros GPUs do mundo a oferecer computação confidencial, permitindo implantação segura de modelos OpenAI e Anthropic em várias regiões de nuvem. Como exemplo, aceleramos todos os fluxos de trabalho EDA e CAD da Synopsys, implantados na Azure.
Oracle: somos o primeiro cliente de IA da Oracle, e tenho orgulho de ter explicado pela primeira vez o conceito de nuvem de IA para eles. Desde então, cresceram rapidamente, e introduzimos parceiros como Cohere, Fireworks, OpenAI.
CoreWeave: a primeira nuvem nativa de IA do mundo, especializada em hospedagem de GPUs e serviços de nuvem de IA, com uma base de clientes excelente e crescimento forte.
Palantir + Dell: criaram uma nova plataforma de IA, baseada na plataforma Ontology da Palantir e na plataforma de IA, capaz de implantar IA de forma totalmente local, em qualquer país, em ambientes isolados, com toda a cadeia de processamento — desde vetorização ou dados estruturados até toda a pilha de computação acelerada de IA.
A Nvidia estabeleceu esse tipo de parceria com provedores globais de nuvem — levando clientes à nuvem, criando um ecossistema de benefício mútuo.
Integração vertical, abertura horizontal: a estratégia central da Nvidia
A Nvidia é a primeira empresa global a adotar um modelo de integração vertical e abertura horizontal.
A necessidade é simples: computação acelerada não é apenas questão de chips ou sistemas, mas de aplicação acelerada. CPUs podem acelerar o funcionamento geral do computador, mas esse caminho atingiu um limite. No futuro, só o aceleramento específico por aplicação ou setor trará avanços de desempenho e redução de custos de forma contínua.
Por isso, a Nvidia precisa aprofundar seu trabalho em cada biblioteca, setor e indústria vertical. Somos uma empresa de computação verticalmente integrada, sem outro caminho. Precisamos entender aplicações, setores, algoritmos, e implantá-los em qualquer cenário — data centers, nuvem, local, borda, até robôs.
Ao mesmo tempo, mantemos uma abertura horizontal, integrando nossa tecnologia às plataformas de parceiros, para que o mundo todo possa se beneficiar do cálculo acelerado.
A composição dos participantes do GTC reflete isso. A maior participação é do setor financeiro — mais desenvolvedores do que traders. Nosso ecossistema cobre toda a cadeia de suprimentos, de fornecedores há 50, 70 ou 150 anos. Mesmo no ano passado, empresas centenárias tiveram seu melhor resultado histórico. Estamos no começo de algo muito, muito importante.
CUDA-X: motores de computação acelerada por setor
Em cada setor vertical, a Nvidia já tem uma presença profunda:
- Veículos autônomos: abrangente e de impacto profundo
- Serviços financeiros: a quantificação de investimentos está migrando de engenharia manual para deep learning movido por supercomputadores, vivendo seu “momento Transformer”
- Saúde: vivendo seu próprio “momento ChatGPT”, incluindo descoberta de medicamentos assistida por IA, diagnósticos por agentes inteligentes, atendimento médico
- Indústria: uma onda de construção global, com fábricas de IA, fábricas de chips, data centers
- Entretenimento e jogos: plataformas de IA em tempo real para tradução, streaming, interação em jogos, agentes de compras inteligentes
- Robótica: mais de dez anos de desenvolvimento, com três arquiteturas principais (treinamento, simulação, embarcada), com 110 robôs apresentados nesta feira
- Telecomunicações: setor de cerca de 2 trilhões de dólares, com estações base evoluindo de funções de comunicação para plataformas de infraestrutura de IA, como a plataforma Aerial, com parcerias com Nokia, T-Mobile, entre outros
Todos esses setores têm como núcleo as bibliotecas CUDA-X — a essência da Nvidia como uma empresa de algoritmos. Essas bibliotecas são seus ativos mais valiosos, permitindo que a plataforma de computação gere valor real em cada setor.
Uma das mais importantes é a cuDNN (CUDA Deep Neural Network Library), que revolucionou a IA e desencadeou a explosão moderna de IA.
(Exibição de vídeo de demonstração do CUDA-X)
Tudo que vocês viram até agora é simulação — incluindo solucionadores baseados em princípios físicos, modelos de agentes físicos, e modelos de robôs físicos de IA. Tudo é simulação, sem animações manuais ou articulações fixas. Essa é a capacidade central da Nvidia: através de uma compreensão profunda de algoritmos e uma plataforma de cálculo integrada, desbloqueando essas oportunidades.
Empresas nativas de IA e a nova era de computação
Vocês viram gigantes como Walmart, L’Oréal, JPMorgan, Roche, Toyota, além de muitas empresas que vocês nunca ouviram falar — chamamos de empresas nativas de IA. Essa lista é enorme, incluindo OpenAI, Anthropic, e muitas startups em diversos setores.
Nos últimos dois anos, esse setor teve um crescimento extraordinário. Investimentos de risco em startups atingiram US$ 150 bilhões, recorde na história humana. Ainda mais, o tamanho de cada rodada de investimento saltou de milhões para centenas de milhões ou bilhões de dólares. O motivo? É a primeira vez na história que cada uma dessas empresas precisa de uma enorme quantidade de recursos de computação e tokens. O setor está criando, gerando tokens, ou valorizando tokens de instituições como Anthropic e OpenAI.
Assim como a revolução do PC, da internet e do mobile criaram empresas revolucionárias, essa transformação de plataformas de computação também dará origem a empresas influentes, que serão forças no futuro mundial.
Três avanços históricos que impulsionam tudo isso
O que aconteceu nos últimos dois anos? Três grandes eventos.
Primeiro: ChatGPT, que inaugurou a era da IA generativa (final de 2022 a 2023)
Ela não só percebe e entende, mas também gera conteúdo único. Mostrei a fusão de IA generativa com gráficos de computador. IA generativa mudou fundamentalmente a forma de computar — de uma abordagem de recuperação para geração, impactando profundamente arquitetura, implantação e significado geral.
Segundo: IA de raciocínio (Reasoning AI), representada pelo o1
A capacidade de raciocínio permite que a IA reflita, planeje e decompõe problemas — dividindo questões que ela não consegue entender diretamente em passos gerenciáveis. o1 torna a IA generativa confiável, capaz de raciocinar com base em informações reais. Para isso, aumenta significativamente o volume de tokens de entrada (contexto) e de saída (pensamento), elevando o cálculo de forma expressiva.
Terceiro: Claude Code, o primeiro modelo de agente
Ele consegue ler arquivos, escrever código, compilar, testar, avaliar e iterar. Claude Code revoluciona a engenharia de software — todos os engenheiros da Nvidia usam Claude Code, Codex ou Cursor, pelo menos um deles, sem exceção.
É um ponto de inflexão: não se trata mais de perguntar à IA “o que é, onde está, como fazer”, mas de fazer com que ela “crie, execute, construa”, usando ferramentas, lendo arquivos, decompondo problemas, agindo. A IA evolui de percepção, geração, raciocínio, para realmente fazer o trabalho.
Nos últimos dois anos, o cálculo necessário para raciocínio cresceu cerca de 10.000 vezes, e o uso aumentou cerca de 100 vezes. Sempre acreditei que, nesse período, a demanda de computação cresceu 1 milhão de vezes — uma sensação comum a todos, do OpenAI ao Anthropic. Quanto mais poder de cálculo, mais tokens podem ser gerados, mais receita, e mais inteligente a IA fica. O ponto de inflexão do raciocínio chegou.
Era da infraestrutura de IA de um trilhão de dólares
No mesmo período do ano passado, eu disse que tínhamos alta confiança na demanda e pedidos de Blackwell e Rubin até 2026, na ordem de US$ 500 bilhões. Hoje, um ano depois, digo que até 2027 vejo pelo menos US$ 1 trilhão, e tenho certeza de que a demanda real será muito maior.
2025: o ano do raciocínio na Nvidia
2025 será o “Ano do Raciocínio” da Nvidia. Queremos garantir que, além do treinamento e pós-treinamento, a infraestrutura de IA seja eficiente em todas as fases do ciclo de vida, com maior durabilidade e menor custo por unidade.
Ao mesmo tempo, Anthropic e Meta se juntaram à plataforma Nvidia, representando um terço da demanda global de IA. Modelos de código aberto estão chegando ao estado de arte, presentes em todos os lugares.
A Nvidia é atualmente a única plataforma capaz de rodar todos os tipos de IA — de linguagem, biologia, gráficos, visão computacional, voz, proteínas, química, robótica — em qualquer ambiente, seja na borda ou na nuvem, em qualquer idioma. Essa arquitetura universal faz de nós a plataforma de menor custo e maior confiabilidade.
60% dos negócios da Nvidia vêm das cinco maiores nuvens de grande porte, os outros 40% estão distribuídos em nuvens regionais, soberanas, empresas, indústrias, robótica e computação de borda. A abrangência da IA é sua maior resiliência — sem dúvida, uma revolução de plataforma de computação totalmente nova.
Grace Blackwell e NVLink 72: inovação arquitetônica audaciosa
Quando a arquitetura Hopper ainda estava no auge, decidimos reestruturar completamente o sistema, expandindo NVLink de 8 para 72 vias, para uma reconstrução total do sistema de computação. Grace Blackwell NVLink 72 foi uma aposta tecnológica enorme, difícil para todos os parceiros, e agradeço sinceramente a todos.
Ao mesmo tempo, lançamos o NVFP4 — uma nova classe de núcleos tensor e unidades de cálculo, não apenas FP4 comum. Comprovamos que o NVFP4 pode fazer inferência sem perda de precisão, com ganhos de desempenho e eficiência energética. Ele também serve para treinamento. Além disso, novas técnicas como Dynamo e TensorRT-LLM foram lançadas, e construímos um supercomputador dedicado, DGX Cloud, para otimizar kernels.
Os resultados mostram desempenho de inferência impressionante. Dados do Semi Analysis — a avaliação mais abrangente de desempenho de inferência de IA até hoje — mostram que a Nvidia lidera em eficiência por watt e custo por token. Enquanto a Lei de Moore previa um aumento de 1,5x no H200, conseguimos 35x. Dylan Patel do Semi Analysis até disse: “黄仁勋 foi conservador, na verdade é 50x.” E ele não está errado.
Citando-o: “Jensen fez sandbagging (foi conservador na contagem).”
O custo por token da Nvidia é o mais baixo do mundo, sem concorrência. A razão é o design de co-design extremo.
Por exemplo, antes da atualização de software e algoritmos, a velocidade média de tokens na Fireworks era cerca de 700 por segundo; após a atualização, quase 5.000 por segundo — um aumento de cerca de 7 vezes. Essa é a força do co-design extremo.
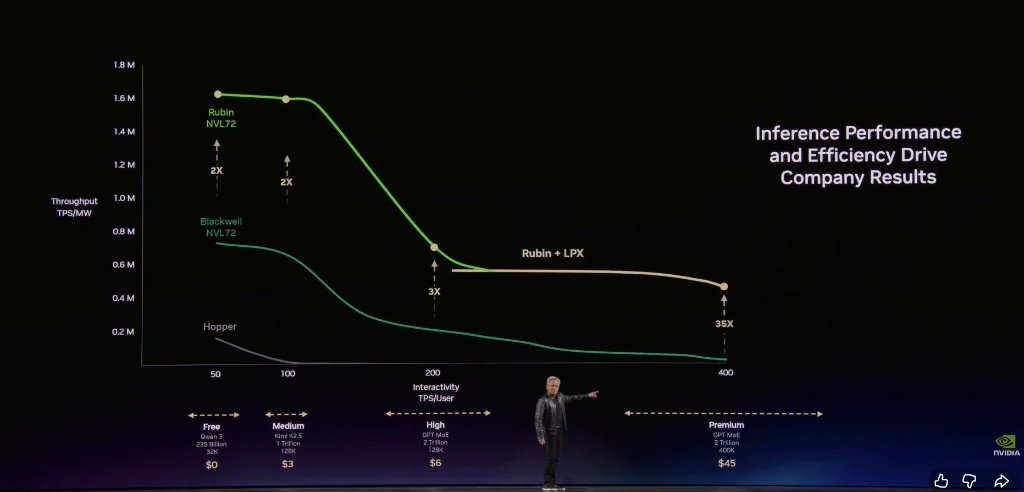
Fábrica de tokens: de data center a fábrica de produção de tokens
Data centers antes eram armazéns de arquivos, agora são fábricas de tokens. Cada provedor de nuvem, cada empresa de IA, no futuro, usará “eficiência de fábrica de tokens” como métrica principal.
Minha tese:
- Eixo vertical: throughput — tokens gerados por segundo sob potência fixa
- Eixo horizontal: velocidade de interação — resposta por inferência, quanto mais rápido, maior o modelo, maior o contexto, mais inteligente a IA
Tokens serão uma nova commodity, com preços em camadas:
- Camada gratuita (alto throughput, baixa velocidade)
- Camada intermediária (~$3 por milhão de tokens)
- Camada avançada (~$6 por milhão de tokens)
- Camada de alta velocidade (~$45 por milhão de tokens)
- Camada ultra-rápida (~$150 por milhão de tokens)
Comparado ao Hopper, Grace Blackwell aumentou o throughput na camada de maior valor em 35x, e introduziu novas camadas. Com uma estimativa simplificada, dividir 25% de potência entre as quatro camadas, Grace Blackwell gera 5x mais receita que Hopper.
Vera Rubin: a próxima geração de sistema de IA
(Vídeo de apresentação do Vera Rubin)
Vera Rubin é um sistema completo, otimizado de ponta a ponta, projetado para cargas de trabalho de agentes (Agentic):
- Núcleo de computação de grandes modelos de linguagem: cluster de GPUs NVLink 72, para pré-preenchimento e KV Cache
- Novo CPU Vera: otimizado para alta performance de thread única, com memória LPDDR5, eficiência energética superior, único CPU de data center com LPDDR5, ideal para chamadas de ferramentas de agentes de IA
- Sistema de armazenamento: BlueField 4 + CX 9, nova plataforma de armazenamento para a era da IA, com participação de 100% do setor de armazenamento
- Switch óptico CPO Spectrum X: o primeiro switch de Ethernet óptico de encapsulamento conjunto em produção, já em volume
- Rack Kyber: novo sistema de rack, suportando 144 GPUs em um único domínio NVLink, com computação front-end e troca NVLink no back-end, formando um supercomputador gigante
- Rubin Ultra: próxima geração de nós de supercomputador, com design vertical, compatível com Kyber, suportando maior escala de NVLink
Vera Rubin já é totalmente líquido, com instalação reduzida de dois dias para duas horas, usando resfriamento por água quente a 45°C, reduzindo significativamente a carga de resfriamento do data center. Satya Nadella confirmou que o primeiro rack Vera Rubin já está em operação na Azure, o que me deixa muito animado.
Integração com Groq: extensão máxima de desempenho de inferência
Adquirimos a equipe Groq e sua tecnologia. Groq é um processador de fluxo de dados determinístico, com compilador estático, SRAM em grande quantidade, otimizado para cargas de trabalho de inferência única, com latência extremamente baixa e velocidade de geração de tokens muito alta.
Porém, a memória do Groq é limitada (500MB de SRAM on-chip), dificultando suportar grandes modelos com muitos parâmetros e KV Cache, limitando aplicações em larga escala.
A solução é Dynamo — um sistema de agendamento de inferência. Com Dynamo, desagregamos a pipeline de inferência:
- Pré-preenchimento e atenção (attention) de decodificação (decode) são feitos na Vera Rubin (requer muita computação e armazenamento de KV Cache)
- Decodificação de rede feed-forward (geração de tokens) é feita no Groq (requer alta largura de banda e baixa latência)
Essas duas partes são conectadas por Ethernet, com modos especiais que reduzem a latência em cerca de metade. Sob o sistema de agendamento unificado Dynamo, o desempenho total aumenta 35x, abrindo novas camadas de inferência que antes eram inacessíveis.
A combinação de Groq e Vera Rubin recomenda-se assim:
- Para cargas de trabalho de alto throughput, usar 100% Vera Rubin
- Para tarefas de geração de tokens de alto valor, reservar cerca de 25% do data center para Groq
Os chips Groq LP30, fabricados pela Samsung, já estão em produção em volume, com previsão de entrega no Q3. Agradeço à Samsung pelo apoio.
Salto histórico no desempenho de inferência
Quantificando o avanço: em dois anos, a taxa de geração de tokens de uma fábrica de IA de 1 GW passará de 22 milhões para 700 milhões por segundo, um aumento de 350x. Essa é a força do co-design extremo.
Roteiro tecnológico
- Blackwell: em produção, com sistema Oberon, NVLink 72; opcionalmente, NVLink 576 com fibra óptica
- Vera Rubin (atual): rack Kyber, NVLink 144 (cabo de cobre); rack Oberon, NVLink 72 + fibra óptica, até NVLink 576; Spectrum 6, o primeiro switch CPO do mundo
- Vera Rubin Ultra (em breve): nova GPU Rubin Ultra, com chip LP35 (com NVFP4 integrado), com desempenho várias vezes maior
- Feynman (próxima geração): nova GPU, chip LP40 (desenvolvido em parceria Nvidia-Groq, com NVFP4); CPU Rosa (Rosalyn); BlueField 5; CX 10; suporte a ambos cobre e CPO em racks Kyber
O roteiro mostra que as três rotas — expansão por cobre, fibra óptica (Scale-Up) e fibra óptica em escala (Scale-Out) — avançam simultaneamente, e que todos os parceiros devem ampliar continuamente a capacidade de cobre, fibra e CPO.
NVIDIA DSX: plataforma de gêmeos digitais para fábricas de IA
Fábricas de IA estão se tornando cada vez mais complexas, mas seus componentes — fornecedores de tecnologia — nunca haviam colaborado na fase de projeto, apenas na operação. Isso é insuficiente.
Por isso, criamos o Omniverse e a plataforma NVIDIA DSX, uma plataforma de projeto e operação de fábricas de IA de gigavatts em ambiente virtual. O DSX oferece:
- Simulação de racks, térmica, elétrica, rede
- Conexão com a rede elétrica, para coordenação de economia de energia
- Otimização dinâmica de consumo e resfriamento com Max-Q
Estimamos que esse sistema pode melhorar a eficiência energética em cerca de 2x, um ganho significativo em escala. O Omniverse, desde o “globo digital”, suportará gêmeos digitais de qualquer tamanho, em colaboração global, construindo a maior máquina de computação da história.
Além disso, estamos avançando na exploração espacial. O chip Thor passou na certificação de radiação, e está sendo utilizado em satélites. Estamos colaborando com parceiros no desenvolvimento do Vera Rubin Space-1, um data center espacial, abrindo a imaginação para uma extensão do poder de computação de IA além da Terra. No espaço, o resfriamento por radiação é obrigatório, e esse é o maior desafio técnico. Estamos reunindo engenheiros de ponta para resolver essa questão.
OpenClaw: o sistema operacional da era dos agentes
Peter Steinberger desenvolveu um software chamado OpenClaw. É o projeto de código aberto mais popular da história, que em poucas semanas superou as realizações do Linux em 30 anos.
OpenClaw é, na essência, um sistema operacional de agentes (Agentic System), capaz de:
- Gerenciar recursos, acessar ferramentas, arquivos e grandes modelos de linguagem
- Executar agendamento, tarefas periódicas
- Decompor problemas em etapas, chamando sub-agentes
- Suportar entrada e saída multimodal (voz, vídeo, texto, email, etc.)
Em termos de sistema operacional, é um sistema operacional — o sistema operacional de computadores de agentes. Assim como o Windows tornou possível o uso de computadores pessoais, o OpenClaw torna possível a computação de agentes inteligentes.
Cada empresa precisará definir sua estratégia de OpenClaw, assim como tem sua estratégia de Linux, HTML, Kubernetes.
A revolução na TI empresarial
Antes do OpenClaw, a TI empresarial consistia em dados e arquivos entrando no sistema, passando por ferramentas e fluxos de trabalho, e se tornando ferramentas para humanos. Empresas de software criavam ferramentas, integradores e consultores ajudavam a usar essas ferramentas.
Depois do OpenClaw, cada SaaS será uma empresa de AaaS (Agentic as a Service, agentes como serviço) — não apenas fornecendo ferramentas, mas oferecendo agentes especializados em cada domínio.
Porém, há um grande desafio: agentes internos podem acessar dados sensíveis, executar códigos, comunicar-se com o exterior. Isso precisa ser controlado com rigor.
Por isso, colaboramos com Peter para incorporar segurança ao sistema empresarial, lançando:
- NeMo Claw (referência): framework empresarial baseado no OpenClaw, com o pacote completo de ferramentas de IA de agentes da Nvidia
- Open Shield (camada de segurança): integrado ao NeMo Claw, fornece motor de estratégias, firewall de rede, roteador de privacidade, garantindo segurança dos dados
- NeMo Cloud: disponível para download, integrado às políticas de todas as SaaS
Essa é uma revolução na TI empresarial, que movimenta uma indústria de 2 trilhões de dólares, que crescerá para dezenas de trilhões, mudando de ferramentas para serviços de IA especializados.
Prevejo que, no futuro, cada engenheiro terá um orçamento anual de tokens. Seu salário pode ser de dezenas de milhares de dólares, e uma parte desse valor será reservada em tokens, multiplicando sua produtividade por 10x. “Quanto de tokens vem no pacote de contratação?” já virou uma nova questão de recrutamento no Vale do Silício.
Cada empresa será tanto usuária quanto produtora de tokens — fornecendo serviços de IA a seus clientes. O OpenClaw é tão importante quanto HTML ou Linux.
Iniciativa de modelos abertos da Nvidia
Para personalizar agentes, oferecemos modelos avançados próprios:
Nemotron — grande modelo de linguagem Cosmos — modelo de base universal GROOT — modelo de robô humanoide geral BioNeMo — biologia digital Phys-AI — física
Estamos na vanguarda de cada uma dessas áreas, com planos de evoluir continuamente — Nemotron 3, Nemotron 4; Cosmos 1, Cosmos 2; Groq de primeira para segunda geração.
Nemotron 3 é um dos três melhores modelos do mundo, de ponta. Nemotron 3 Ultra será o mais poderoso de todos, suportando a construção de IA soberana por países.
Hoje, anunciamos a criação da Aliança Nemotron, com investimento de bilhões de dólares, para avançar na pesquisa de modelos de base de IA. Os membros incluem: BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam (Índia), Thinking Machines (laboratório de Mira Murati), entre outros. Empresas de software estão se juntando, integrando o pacote de ferramentas de IA de agentes da Nvidia em seus produtos.
Física de IA e robótica
Agentes digitais atuam no mundo digital — escrevem códigos, analisam dados; enquanto IA física é um agente encarnado, ou seja, robô.
Nesta GTC, apresentamos 110 robôs, abrangendo quase todas as empresas de robótica do mundo. A Nvidia fornece três computadores (treinamento, simulação, embarcado) e toda a pilha de software e modelos de IA.
Na direção autônoma, o “momento ChatGPT” já chegou. Anunciamos quatro novos parceiros na plataforma RoboTaxi da Nvidia: BYD, Hyundai, Nissan e Geely, com produção anual total de 18 milhões de veículos. Com isso, o total de fabricantes como Mercedes-Benz, Toyota, GM, aumenta ainda mais. Também anunciamos uma parceria com Uber, para implantar e operar veículos RoboTaxi em várias cidades.
Na robótica industrial, empresas como ABB, Universal Robotics, KUKA, entre outras, colaboram conosco na integração de modelos físicos de IA com sistemas de simulação, impulsionando a adoção de robôs em linhas de produção globais.
Na telecomunicação, a Caterpillar e a T-Mobile também estão na lista. No futuro, as estações base deixarão de ser apenas pontos de comunicação, tornando-se plataformas de infraestrutura de IA — como a plataforma Aerial, com parcerias com Nokia, T-Mobile, entre outras.
Momento especial: Olaf, o robô da Disney
(Vídeo de demonstração do robô Olaf)
黄仁勋: Apresentamos o boneco de neve! Newton está funcionando bem! Omniverse também! Olaf, tudo bem?
Olaf: Estou muito feliz por te ver.
黄仁勋: Sim, porque fui eu quem te deu o computador — o Jetson!
Olaf: O que é isso?
黄仁勋: Está dentro da sua barriga.
Olaf: Uau, que incrível!
黄仁勋: Você aprendeu a andar no Omniverse.
Olaf: Eu gosto de andar. É muito melhor do que montar rena e olhar para o céu bonito.
黄仁勋: Isso é graças à simulação física — o solucionador Newton, baseado na plataforma NVIDIA Warp, desenvolvido em parceria com Disney e DeepMind, que permite que você se adapte ao mundo físico real.
Olaf: Eu ia dizer exatamente isso.
黄仁勋: Essa é a sua inteligência. Eu sou um boneco de neve, não uma bola de neve.
黄仁勋: Você consegue imaginar? O futuro parque da Disney — todos esses personagens robóticos passeando livremente. Mas, para ser honesto, achei que você fosse mais alto. Nunca vi um boneco de neve tão baixo.
Olaf: (sem responder)
黄仁勋: Venha me ajudar a encerrar a palestra de hoje?
Olaf: Com certeza!
Resumo do discurso principal
黄仁勋: Hoje, exploramos os seguintes temas centrais:
- A chegada do ponto de inflexão do raciocínio: raciocínio tornou-se a carga de trabalho mais importante na IA, tokens são a nova commodity, o desempenho de raciocínio determina a receita
- Era da fábrica de IA: data centers evoluíram de armazéns de arquivos para fábricas de tokens, no futuro, cada empresa medirá sua competitividade por “eficiência de fábrica de IA”
- Revolução dos agentes com OpenClaw: OpenClaw iniciou a era do cálculo de agentes, a TI empresarial está mudando de ferramentas para agentes, cada empresa precisa de uma estratégia de OpenClaw
- IA física e robótica: agentes encarnados estão se consolidando, com direção autônoma, robôs industriais e humanoides formando as maiores oportunidades de IA física
Obrigado a todos, boa GTC!

