AI Request Routing — это инфраструктурная функция для управления вычислительными ресурсами при работе с несколькими моделями. С развитием больших языковых моделей, таких как GPT, Claude, Gemini и DeepSeek, всё больше приложений ИИ одновременно используют сразу несколько моделей. Вопрос интеллектуального выбора между ними становится ключевым в проектировании систем ИИ.
Gate.AI располагается между приложениями и сервисами моделей, выступая в роли ИИ-шлюза и слоя маршрутизации. Поскольку многомодельные архитектуры становятся отраслевым стандартом, маршрутизация влияет не только на производительность системы, но и на контроль затрат, стабильность сервиса и автономность ИИ-агентов.
Что такое маршрутизация запросов ИИ?
Это механизм планирования, который автоматически выбирает целевую модель исходя из характеристик задачи. В традиционных архитектурах приложение вызывает одну фиксированную модель для выполнения логического вывода. В многомодельной архитектуре разные модели имеют свои преимущества: способность к рассуждению, генерация кода, обработка длинных текстов или экономическая эффективность.
Слой маршрутизации анализирует содержимое запроса и направляет его наиболее подходящей модели, повышая общую эффективность использования ресурсов.
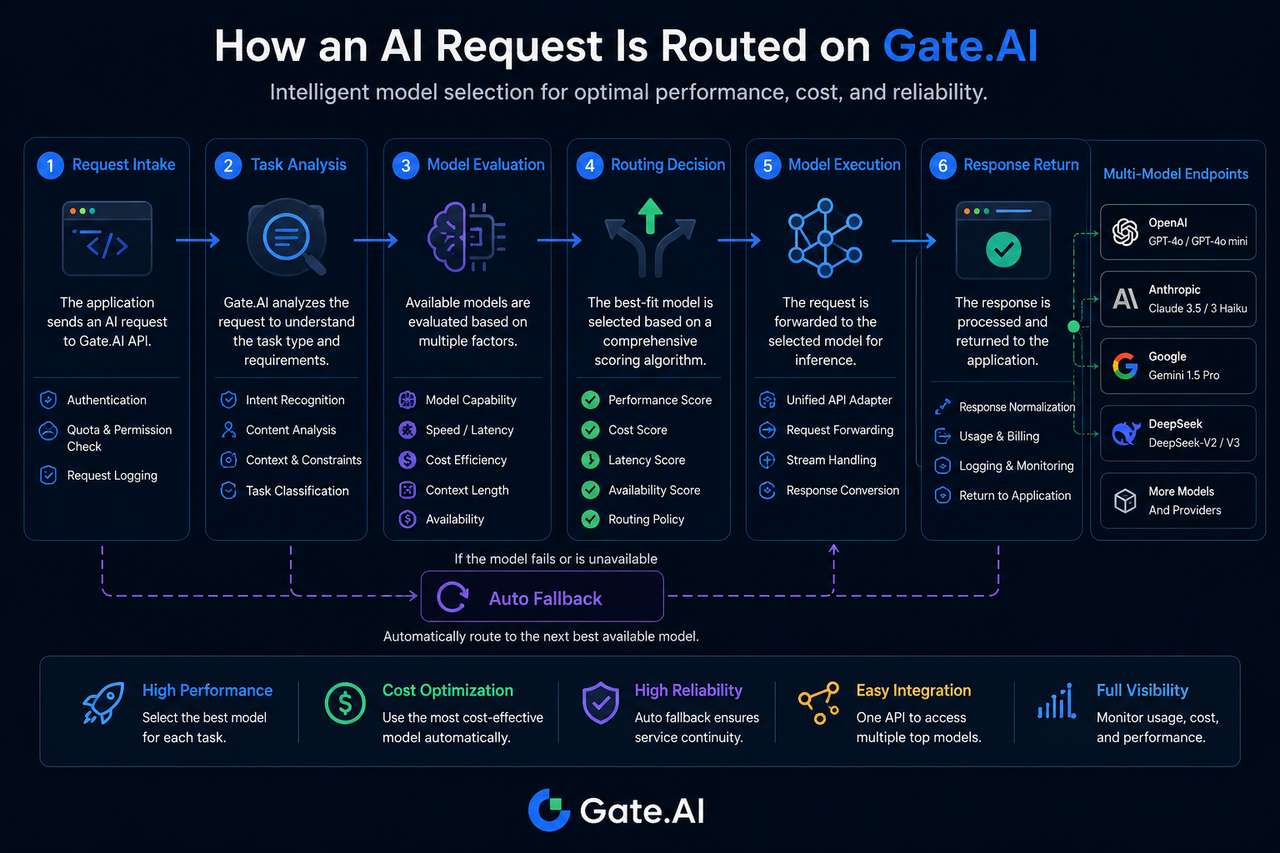
Шаг 1: Запрос ИИ поступает в Gate.AI
Процесс маршрутизации начинается с этапа поступления запроса.
Когда приложение отправляет запрос, он сначала попадает на уровень шлюза Gate.AI. Система проверяет идентификационные данные, разрешения на доступ и фиксирует параметры запроса.
Содержимое запроса обычно включает:
- Ввод пользователя
- Конфигурацию модели
- Лимиты токенов
- Требования к формату ответа
- Стратегию вызова
После проверки запрос переходит к следующему этапу анализа.
Шаг 2: Система анализирует тип задачи
Идентификация задачи — ключевой элемент маршрутизации.
Gate.AI определяет тип задачи по характеристикам запроса, например:
- Общий диалог
- Суммаризация длинных текстов
- Создание контента
- Генерация кода
- Анализ данных
- Вызовы инструментов агента
Разные задачи предъявляют разные требования к возможностям модели.
Точная идентификация задачи делает последующий подбор модели более эффективным.
Шаг 3: Оценка и сопоставление возможностей моделей
На этапе оценки определяется круг моделей-кандидатов.
Система обращается к базе возможностей моделей, чтобы отфильтровать доступные в данный момент модели.
Критерии оценки обычно включают:
- Способность к рассуждению
- Длину контекста
- Скорость ответа
- Возможность вызова инструментов
- Мультимодальную поддержку
- Уровень затрат
Например, для сложных задач рассуждения приоритет отдаётся моделям с более сильными аналитическими способностями, а для обработки длинных документов — моделям с поддержкой сверхдлинного контекста.
Шаг 4: Формирование решения о маршрутизации
На этом этапе определяется финальная модель для выполнения.
После идентификации кандидатов система оценивает их по нескольким метрикам.
Основные факторы сравнения:
Производительность модели
Производительность определяет качество выполнения задачи.
Сложные задачи обычно требуют более мощного логического рассуждения, а для простых задач необязательно использовать самую производительную модель.
Задержка ответа
Скорость ответа напрямую влияет на пользовательский опыт.
В сценариях реального времени модели с низкой задержкой получают более высокий приоритет.
Стоимость вызова
Затраты на логический вывод у разных моделей различаются.
Если несколько моделей могут выполнить одну задачу, система может выбрать ту, что эффективнее использует ресурсы.
Доступность сервиса
Статус модели также важен при принятии решения.
Если модель имеет ограничение по скорости, испытывает сбои или перегружена, система автоматически снижает её приоритет.
Шаг 5: Запрос отправляется целевой модели
После принятия решения запрос пересылается целевой модели.
Gate.AI на этом этапе единообразно обрабатывает различия в интерфейсах разных поставщиков моделей.
Разработчикам приложений не нужно создавать отдельные интерфейсы для каждой модели.
Единый уровень доступа снижает сложность разработки и повышает масштабируемость системы.
Шаг 6: Модель генерирует результат и возвращает его
После завершения логического вывода результат возвращается в Gate.AI.
Gate.AI стандартизирует ответ, чтобы данные от разных моделей имели единую структуру.
Единый формат вывода сокращает работу по адаптации на уровне приложения и упрощает интеграцию.
Конечный результат возвращается приложению или ИИ-агенту.
Что происходит, когда целевая модель недоступна?
Недоступность модели — обычная ситуация в многомодельной среде.
Если целевая модель превышает тайм-аут, имеет ограничение по скорости или испытывает сбои, Gate.AI может запустить автоматический процесс отката.
Система по заданным правилам выбирает резервную модель для продолжения выполнения задачи.
Этот механизм снижает риск единичных точек отказа и повышает общую непрерывность сервиса.
Подробнее об этом процессе см. «Что происходит при сбое модели ИИ? Полный анализ автоматического механизма отката Gate.AI».
Пример процесса маршрутизации запросов ИИ
Ниже показан типичный поток для задачи генерации контента:
| Этап |
Действие системы |
| Поступление запроса |
Приложение отправляет запрос на генерацию |
| Анализ задачи |
Определено как создание длинного текстового контента |
| Фильтрация моделей |
Выбор моделей-кандидатов, поддерживающих длинный контекст |
| Решение о маршрутизации |
Оценка по производительности, затратам и задержке |
| Выполнение модели |
Запрос отправлен целевой модели |
| Обработка результатов |
Возврат стандартизированного вывода |
| Восстановление после сбоя |
Автоматическое переключение на резервную модель при необходимости |
Этот процесс обычно занимает очень мало времени, и пользователи часто не замечают, что за кулисами произошёл выбор модели.
Резюме
Маршрутизация запросов ИИ — ключевая функция AI-шлюза, которая динамически выбирает наиболее подходящую модель для выполнения задачи среди множества больших языковых моделей. В отличие от фиксированного вызова одной модели, маршрутизация позволяет полностью использовать сильные стороны разных моделей, повышая гибкость, стабильность и эффективность использования ресурсов системы.
В архитектуре Gate.AI запрос ИИ проходит несколько этапов: поступление, идентификация задачи, оценка модели, решение о маршрутизации, выполнение модели и возврат результата.
Часто задаваемые вопросы
Зачем Gate.AI нужна маршрутизация моделей?
Gate.AI объединяет несколько экосистем моделей ИИ, каждая из которых сильна в своей области: рассуждение, генерация кода, обработка длинных текстов и т.д. Маршрутизация автоматически выбирает наиболее подходящую модель исходя из требований задачи.
Может ли один запрос ИИ вызывать несколько моделей одновременно?
Обычно один запрос ИИ выполняется одной целевой моделью. Однако в сложных сценариях может использоваться многомодельная коллаборация, когда разные модели обрабатывают разные части задачи.
Какие факторы в первую очередь учитываются при принятии решений о маршрутизации?
Учитываются несколько факторов: производительность модели, скорость ответа, стоимость логического вывода, длина контекста, возможность вызова инструментов и доступность сервиса.
В чем разница между маршрутизацией моделей и балансировкой нагрузки?
Балансировка нагрузки в первую очередь распределяет трафик, а маршрутизация моделей фокусируется на подборе модели по возможностям. Маршрутизация выбирает наиболее подходящую модель исходя из характеристик задачи, а не просто распределяет запросы.









