Оскільки моделі ШІ еволюціонують у напрямку мультимодальності, вертикальних сценаріїв використання та інтелектуальних агентів (Agents), галузевий консенсус змінюється: замість «чим більше даних, тим краще» на перший план виходить те, що «високоточні, відстежувані та конфіденційні дані» — це дефіцитний ресурс. Традиційні централізовані платформи для розмітки даних стикаються з проблемами вартості, реагування на нішевий попит та розподілу капіталу серед учасників. Децентралізовані мережі даних для ШІ намагаються переосмислити відносини виробництва даних через колективний інтелект, координацію через токени та відкриті інтерфейси. Щоб зрозуміти, як працює Alaya AI, варто розібрати її технічні рівні, конвеєр автоматизованої розмітки, логіку вибірки даних та ончейн-економіку, а не зводити все до «аутсорсингу розмітки на блокчейні».
З точки зору промислової архітектури, Alaya AI — це конвергенція Web3 та ШІ на рівні даних: внески даних отримують стимули, дозволи на завдання стають NFT, а розробку моделей можна профінансувати через пул стейкінгу AGT. Відкрита платформа даних (ODP) виступає мостом між попитом і пропозицією. Далі розглянемо базову архітектуру мережі, механізми підвищення ефективності, інтеграцію з Web3, системи стейкінгу та внесків, відмінності від традиційних платформ, реальні виклики та перспективи — це дасть структуровану основу для оцінки технічної спроможності та цінності екосистеми.
Детальний розбір основної технічної архітектури Alaya AI
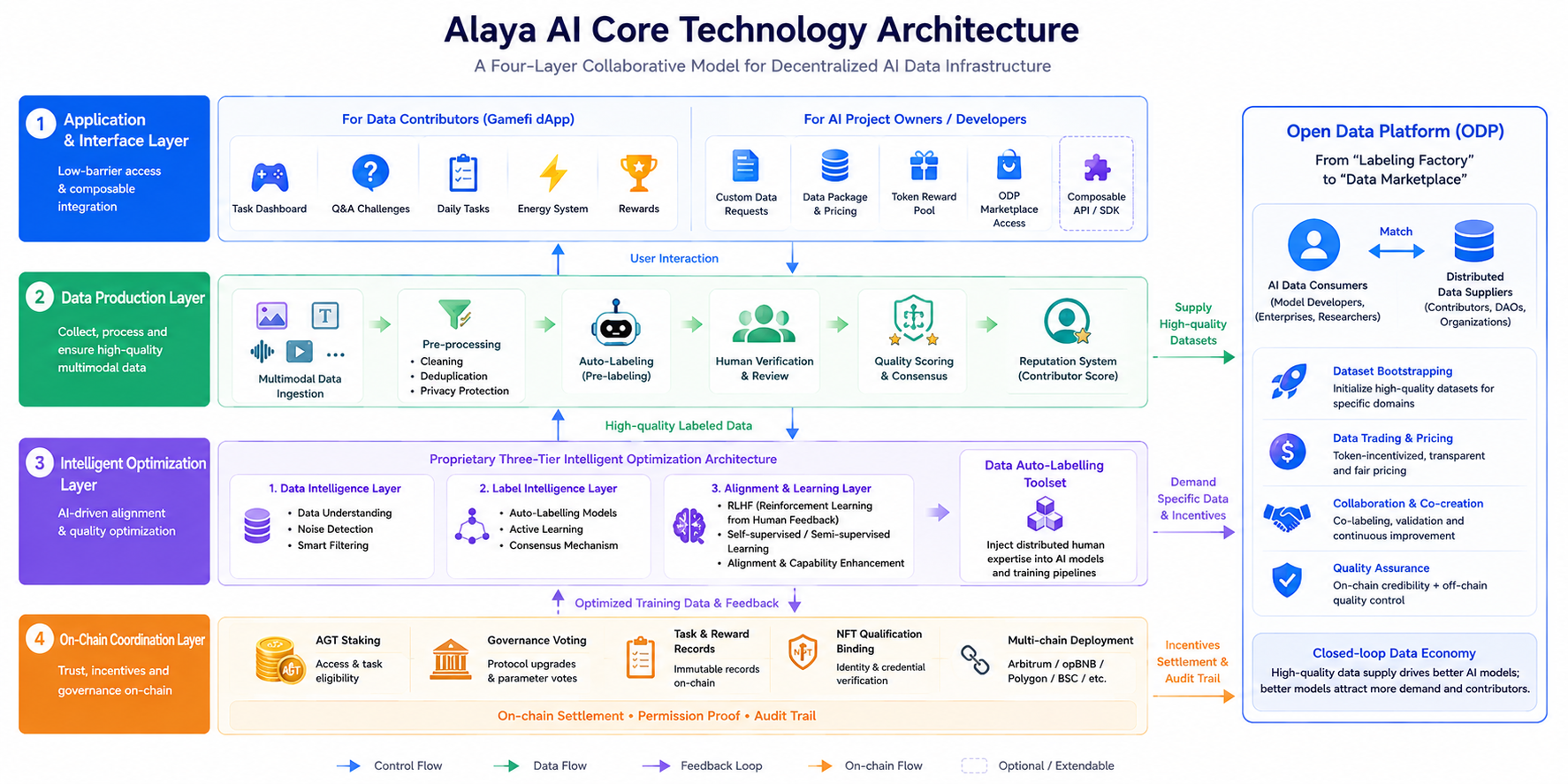
Загальну архітектуру Alaya AI можна подати як чотирирівневу модель співпраці. Кожен рівень має чітко розділені обов'язки з власними потоками даних і керування — це уникає втрати продуктивності, коли «все намагаються запхати в ончейн».
-
Рівень застосунків та інтерфейсів. Сюди входить гейміфікований dApp для постачальників даних (панелі завдань, вікторини, щоденні завдання), а також спеціальні запити даних, пропозиції пакетів даних і точка входу на маркетплейс ODP для команд ШІ-проєктів. Головна ідея — знизити поріг входу та забезпечити компонований доступ. Розробники можуть публікувати вузькоспеціалізовані запити на дані через власні пули токен-винагород.
-
Рівень виробництва даних. Відповідає за прийом мультимодальних даних (текст, зображення, відео, аудіо), їхню попередню обробку (очищення, дедуплікація, захист конфіденційності), автоматичну розмітку, ручну верифікацію та оцінку якості. Alaya AI використовує принципи колективного інтелекту: одне завдання можуть розмічати кілька учасників, а консенсус або механізм більшості підвищує узгодженість міток. Крім того, історична точність формує репутацію учасника, яка впливає на майбутні завдання.
-
Рівень інтелектуальної оптимізації. Його ядро — набір інструментів для автоматичної розмітки даних (Data Auto-Labelling Toolset), який працює на базі власної трирівневої архітектури інтелектуальної оптимізації. Разом із налаштуванням RLHF (навчання з підкріпленням на основі людського зворотного зв'язку) це дозволяє інтегрувати розподілений людський досвід у процеси самонавчання та напівнавчання, покращуючи вирівнювання та можливості моделі.
-
Ончейн-рівень координації. Ключова координаційна інформація — стейкінг AGT, голосування за управління, записи про статус завдань та винагород, прив'язка NFT-кваліфікацій — зберігається в блокчейні (екосистема розгорнута на кількох ланцюгах, зокрема Arbitrum, opBNB, Polygon та BSC; актуальну інформацію варто уточнювати в офіційних оголошеннях). Блокчейн не зберігає великі обсяги сирих даних, але обробляє розрахунки стимулів, підтвердження дозволів та фіксацію аудиторських слідів. Це відповідає поширеній парадигмі Web3 ШІ: «офчейн-обчислення, ончейн-довіра».
Відкрита платформа даних (ODP), запущена в листопаді 2024 року, перетворює мережу з «фабрики розмітки» на «маркетплейс даних». Споживачі ШІ-даних та розподілені постачальники з'єднуються напряму через настроювані токен-стимули. Платформа підтримує створення, торгівлю наборами даних та співпрацю, формуючи замкнений цикл попиту та пропозиції.
Як автоматична розмітка підвищує ефективність даних для ШІ
Автоматична розмітка — ключовий модуль для зниження граничних витрат та скорочення циклів постачання в Alaya AI. Проєкт позиціонує це як наступний етап еволюції самонавчання ШІ: машини спочатку генерують попередні мітки, а люди зосереджуються лише на неоднозначних зразках та вузькоспеціалізованих судженнях. Це дозволяє не розмічати вручну кожен фрагмент даних.
Технічний процес зазвичай складається з таких етапів:
-
Прийом мультимодальних даних: Інструментарій приймає статичні та динамічні візуальні дані, текст, дані сенсорів — усе потрапляє до уніфікованого конвеєра попередньої обробки.
-
Алгоритмічна попередня обробка: Виконується автоматичне очищення та дедуплікація. Для конфіденційних даних застосовується zero-knowledge шифрування (ZK-шифрування), що дозволяє проводити обчислення з мінімальним використанням відкритого тексту. Це враховує вимоги корпоративних клієнтів до конфіденційності та відповідності нормативам.
-
Попереднє маркування моделлю: Власна модель автоматичної розмітки створює початкові мітки. Для поширених категорій даних ШІ проєкт заявляє про рівень верифікації понад 80 %, з обробкою динамічних візуальних потоків у реальному часі. Це критично для таких сценаріїв, як розмітка кадрів для автономного водіння або відео з промислового контролю якості.
-
Цикл оптимізації RLHF: Результати верифікації учасників повертаються до моделі, що постійно зменшує частку ручного перегляду. Галузева практика показує: у циклі RLHF втручання людини можна зосередити приблизно на 20% складних зразків, значно знижуючи загальні витрати та терміни (точні пропорції залежать від типу завдання).
-
Рівень експертної істини: Для корпоративних замовлень високої точності платформа може залучити внутрішню команду експертів (інженерів, лінгвістів, фахівців з візуальних даних тощо) як останню арбітражну інстанцію. Це створює дворівневу структуру: «автоматизована пропускна здатність + експертна точність» — разом із результатами краудсорсингу. Матеріали 2026 року також наголошують, що величезні масиви зашумлених даних стають операційним вузьким місцем, а високоточні вертикальні дані — необхідне паливо для моделей та агентів наступного покоління.
Цінність такої гібридної архітектури в тому, що публічна мережа забезпечує масштаб і швидкість, а закритий експертний конвеєр підтримує базові стандарти якості в чутливих до ризиків галузях. Це запобігає тому, щоб децентралізацію сприймали як «низькоякісний краудсорсинг».
Як працює механізм розподіленої вибірки даних
На відміну від «повного випадкового збору даних», Alaya AI робить акцент на інтелектуальній оптимізації та цільовій вибірці: обираються зразки з високою інформаційною щільністю, виходячи з цілей моделі. Це пом'якшує проблему «великий набір даних, але низький вміст корисного сигналу».
Механізм вибірки можна розглянути в трьох вимірах:
-
Керований попитом: Клієнти ШІ подають спеціалізовані запити (наприклад, окремі діалекти, медичні зображення певного типу, дані про дорожню ситуацію в конкретному регіоні). Платформа спрямовує робочі блоки до пулів учасників, які відповідають необхідному рівню NFT, мові чи професійному досвіду. Таким чином досягається приблизне узгодження робочої сили та завдань.
-
Групова надлишкова вибірка: Кілька людей незалежно розмічають один і той самий набір даних. Перевірка узгодженості виявляє мітки-викиди; зразки з низькою узгодженістю автоматично потрапляють до черги на перегляд або на експертний рівень. Це замінює повний нагляд одного інспектора якості на розподілену надмірність.
-
Динамічне та статичне розведення: Для завдань зі статичними зображеннями та динамічними відеопотоками використовуються різні стратегії пропускної здатності. Динамічне бачення може інтегрувати автоматичну сегментацію та покадрову розмітку, що знижує вартість ручної обробки кожного кадру.
-
Часова та сценарна вибірка: Офіційні сценарії передбачають використання фрагментованого часу (наприклад, поїздка на роботу) для виконання легких завдань. Це перетворює резервну робочу силу на потужність для виробництва даних. Гейміфікований інтерфейс (бали досвіду, енергія) підтримує довгострокову залученість, роблячи пул вибірки безперервним, а не одноразовим краудсорсингом.
Очищення та дедуплікація під час попередньої обробки зменшують зміщення вибірки в самому джерелі. Якщо дублікати, пошкоджені файли або неправильні метадані потрапляють у навчальний набір, це посилює галюцинації та зміщення моделі. Тому вибірка даних — це не просто «скільки зразків взяти», а системна інженерна задача: «що саме зразкувати, хто це робитиме і як перевіряти».
Як поєднуються мережі Web3 та ШІ
Атрибути Web3 в Alaya AI не зводяться лише до «оплати токенами». Вони включають токенізацію, NFT-ізацію та управління ключовими координаційними елементами мережі даних.
-
Координація через токени: Нативний токен AGT виконує роль порогу для стейкінгу, голосування за управління, розблокування просунутих завдань, оновлення NFT та входу до пулів стейкінгу моделей. Дизайн стейкінгу наголошує на безповоротних витратах та безпеці. Проєкт прямо заявляє, що стейкінг AGT сам по собі не дає пасивного прибутку — це запобігає спотворенню стимулів якості розмітки спекулятивним капіталом.
-
Дозволи через NFT: Alaya NFT та Medallion NFT створюють дворівневу систему ідентифікації. Вони визначають, які завдання доступні учаснику, ліміти рівнів та систему досягнень. Оновлення до вищих рівнів потребує витрат AGT у певних точках, що пов'язує ончейн-ідентичність з офчейн-результатами праці.
-
Відкриті комбінації стимулів: Проєкти можуть використовувати AGT або власні токени для створення спеціалізованих пулів даних. Це враховує уподобання команд ШІ, нативних для Web3. Малі та середні розробники можуть запускати набори даних з меншими грошовими витратами через ODP.
-
Ончейн-аудит та походження: Для корпоративних клієнтів платформа наголошує на наскрізній криптографічній цілісності та незмінних аудиторських слідах. Походження даних можна відстежити, що підтримує перевірки відповідності.
-
Гейміфікація та соціальне зростання: Щоденні завдання, реферальні комісії, щомісячний Викуп AGT (користувачі обмінюють кредити AIA, зароблені за завдання, на AGT у пулі викупу з фіксованим часом) — ці механізми періодично конвертують офчейн-активність в ончейн-розподіл цінності.
-
Багаточейн-розгортання: Знижує бар'єри для користувачів різних екосистем. Одна мережа даних може охоплювати групи користувачів на Arbitrum, opBNB тощо. Дорожня карта також згадує розширення на BNB Chain, Optimism тощо для адаптації до різних комісій та швидкості.
Наратив екосистеми 2026 року позиціонує Alaya AI як інфраструктуру даних для AI Agents. Агентам потрібен постійний зворотний зв'язок від людини та нішеві знання. Краудсорсинг Web3 у поєднанні з автоматичною розміткою забезпечує масштабований конвеєр зворотного зв'язку. Синергія з фреймворками інтерактивних агентів реального часу (наприклад, з обговорюваними зовні можливостями OpenClaw) вказує на майбутнє з двома циклами: «навчання на льоту + великомасштабні верифіковані набори даних».
Аналіз систем стейкінгу моделей ШІ та внесків даних
Токенізація моделей ШІ — ключовий механізм, який відрізняє Alaya AI від звичайних платформ розмітки. Спільнота може фінансувати та надавати дані для розробки та тонкого налаштування конкретних моделей через пул стейкінгу AGT. Це дозволяє краще узгодити інтереси: «ті, хто надають дані, отримують вигоду від покращення моделі».
-
Шлях учасника: Зареєструватися в dApp → Виконати базові завдання для формування репутації → Внести AGT у стейкінг, щоб розблокувати завдання вищого рівня (верифікація, калібрування, співпраця з автоматичною розміткою) → Отримати вищі множники винагороди. Паралельно заробляти кредити AIA для участі в щомісячному Викупі AGT.
-
Шлях проєкту: Опублікувати спеціальні запити даних на платформі → Налаштувати пули винагород в AGT або токенах третіх сторін → Платформа призначає завдання відповідним учасникам → Після автоматичної розмітки та ручного контролю якості сформувати набір даних → За бажанням залістити або продати на ODP.
-
Логіка безпеки стейкінгу: AGT слугує інструментом координації за принципом Proof-of-Stake, підвищуючи економічну вартість зловмисної розмітки та фармінгу обсягу. Разом із Medallion NFT це додатково обмежує доступ до завдань високого рівня, захищаючи цінні замовлення даних.
-
Зворотний потік цінності: Офіційний план — використовувати дохід від послуг даних платформи для викупу AGT та внесення його до пулу винагород користувачів. Це має замкнути бізнес-маховик: «попит клієнтів → дохід → повторний стимул → більше високоякісних даних». Фактичний ефект залежить від обсягу корпоративних замовлень та прозорості викупу.
Ця система перетворює внесок даних з одноразової праці на мережеву співпрацю з участю. Учасники, стейкери та проєкти конкурують і співпрацюють за однаковими правилами — це структура Web3, яку традиційні платформи розмітки SaaS нативно підтримувати не можуть.
Відмінності між Alaya AI та традиційними платформами даних ШІ
| Вимір |
Alaya AI |
Традиційні платформи (Scale AI, Labelbox тощо) |
| Організаційна форма |
Розподілена спільнота + Відкрита платформа |
Централізована діяльність та корпоративні контракти |
| Стимули |
AGT, AIA, NFT, гейміфікація |
Переважно фіатна компенсація |
| Кастомізація даних |
Спеціальні пули токенів, P2P-запити |
Стандартні SLA та закупівельні процеси |
| Вираження власності |
NFT та ончейн-записи наголошують на капіталі внесків |
Визначається контрактними умовами |
| Автоматизація |
Трирівнева автоматична розмітка + RLHF + Експертний перегляд |
Зрілі конвеєри, багато глибоких вертикальних кейсів (наприклад, автомобільна промисловість) |
| Тип клієнта |
Нативні Web3 та малі/середні ШІ-команди, корпоративна експансія триває |
Великі технологічні компанії, державні проєкти переважають |
Переваги Alaya AI — у роботі з довгохвостовим попитом, транскордонною аудиторією, швидкому формуванні пулів та прозорих стимулах. Традиційні платформи сильні у визначеності постачання, юридичній зрілості, галузевих сертифікаціях та досвіді роботи з масштабними проєктами. Децентралізовані мережі не замінюють централізованих постачальників у всіх сценаріях, але створюють диференціацію на перетині «чутливий до бюджету, вузька вертикаль, крипто-нативний користувач».
Крім того, Alaya наголошує на високоточних вертикальних даних, а не на нескінченному накопиченні обсягу. Це відрізняється від традиційної логіки «великого набору даних». Такий підхід більше підходить для малих моделей з ефективними параметрами та агентів, але вимагає від клієнтів прийняття моделі ціноутворення та постачання гібридного конвеєра (автоматичний + експертний).
Виклики, що стоять перед децентралізованими мережами даних ШІ
Попри повноту архітектури, децентралізовані мережі даних ШІ стикаються з реальними обмеженнями.
-
Баланс якості та масштабу: Серед мільйонів зареєстрованих користувачів частку стабільно високоякісних розмітників важко перевірити ззовні. Якщо стимули заохочуватимуть фармінг обсягу, це зашкодить поновленням клієнтів ШІ та репутації мережі.
-
Бар'єри для корпоративного впровадження: Юридичні вимоги, сертифікація SOC2, виділені менеджери проєктів, страхування тощо — це стандарт для корпоративних закупівель. Самої ончейн-прозорості недостатньо для підписання великих контрактів; потрібне постійне накопичення перевірених кейсів.
-
Складність користувацького досвіду: Гаманці, NFT, подвійні токени (AGT/AIA), правила стейкінгу та викупу підвищують поріг входження для нових користувачів. Це може обмежити приплив учасників, не знайомих з Web3.
-
Регуляторна невизначеність: Транскордонні дані, токен-стимульована праця, відповідність для чутливих даних (наприклад, медичних) — усе це регулюється по-різному в різних країнах. Зміни політики можуть вплинути на регіони роботи та дизайн токена.
-
Ліквідність та стійкість стимулів: Ринкова капіталізація та обсяг торгів AGT досі невеликі порівняно з ширшим ринком. Якщо дохід платформи та викупи не встигатимуть за пропозицією від розблокувань та викупу, стимули можуть залежати від нових користувачів, а не від внутрішнього грошового потоку.
-
Технічні ризики: Вразливості смарт-контрактів, помилки прив'язки гаманця, що заважають отримати викуп, посилення помилок моделі автоматичної розмітки в довгохвостових категоріях — усе це потребує постійних інженерних інвестицій.
-
Конкурентний тиск: Централізовані гіганти мають значні ресурси та високу прихильність клієнтів. Інші Web3-проєкти даних також конкурують за той самий наратив, тому диференціацію потрібно підтверджувати реальними поставленими даними.
Майбутні напрямки розвитку технології Alaya AI
З огляду на офіційну дорожню карту та динаміку 2025–2026 років, технічна еволюція, ймовірно, зосередиться на таких напрямках:
-
Глибока інтеграція автоматичної розмітки та RLHF: Покращення можливостей обробки в реальному часі для динамічного відео, багатомовних даних та даних зворотного зв'язку від агентів. Скорочення циклу «збір → розмітка → повернення до моделі».
-
ODP та соціалізована співпраця з даними: Розширення від запуску наборів даних до активнішої торгівлі, обміну та спільних функцій, посилення мережевих ефектів.
-
DAO та посилення управління: Передача більшої кількості рішень (наприклад, пріоритети функцій автоматичної розмітки, економічні параметри) на голосування стейкерів AGT. Це підвищить довіру до наративу суверенітету спільноти.
-
Багаточейн та синергія з обчислювальною екосистемою: Інтеграція з DePIN, децентралізованими обчисленнями (Akash, Golem) та протоколами ринку моделей (Bittensor). Дослідження відкритого стеку «дані → навчання → логічний висновок» для зменшення залежності від однієї платформи.
-
Позиціонування в епоху агентів: Постійне посилення високоточних даних з участю людини як основи для логічного висновку агентів. Співпраця з фреймворками навчання агентів у реальному часі для формування швидких та повільних подвійних циклів.
-
Посилення корпоративної відповідності: Розширення ZK-шифрування, аудиту походження даних та покриття експертним переглядом для отримання замовлень у високорегульованих галузях, таких як охорона здоров'я та фінанси.
Такі механізми, як щомісячний Викуп AGT у 2026 році, показують, що операційна сторона використовує фіксований ритм для підтримки очікувань учасників. Чи встигатиме технічна сторона за операційним ритмом, залежить від стійких інвестицій у точність автоматичної розмітки, алгоритми маршрутизації завдань та рівень експертів.
Підсумок
Децентралізована мережа даних ШІ Alaya AI — це по суті багаторівнева система співпраці. Рівень застосунків знижує бар'єри участі. Рівень виробництва даних підвищує ефективність за допомогою автоматичної розмітки та розподіленої вибірки. Рівень інтелектуальної оптимізації поглинає людські знання через RLHF. Ончейн-рівень координації узгоджує стимули та безпеку за допомогою AGT, NFT та правил управління. Відкрита платформа даних (ODP) перетворює мережу з платформи завдань на компонований маркетплейс даних. Пул стейкінгу моделей вводить капітал спільноти та працю в цикл тонкого налаштування моделей.
Значення цієї операційної логіки для індустрії ШІ полягає в наступному: коли високоякісні вертикальні дані стають вузьким місцем, лише централізованих закупівель недостатньо для покриття довгохвостового та глобально фрагментованого попиту на робочу силу. Архітектура Web3 пропонує альтернативну криву пропозиції. Водночас виклики реальні: верифікація якості, корпоративні SLA, регулювання та стійкість стимулів визначатимуть, чи зможе ця технічна архітектура перейти від «демонстрації концепції» до «масштабованого комерційного рішення».
Для технічних спостерігачів оцінка Alaya AI не повинна обмежуватися ончейн-обсягами транзакцій або кількістю реєстрацій. Варто відстежувати жорсткі показники: рівень верифікації автоматичної розмітки, транзакції на ODP, поновлення корпоративних клієнтів та виконання викупу. Ці показники разом дадуть відповідь на одне питання: чи здатна децентралізована мережа даних ШІ одночасно перевершити ключові переваги традиційних платформ в ефективності та надійності?









