Після стрімкого розвитку можливостей великих моделей підприємства вже не зосереджуються на питанні «чи доступна модель», а переймаються тим, «чи може вона надійно й стабільно працювати у реальних бізнес-середовищах». Хоча кластери для тренування можуть агрегувати хеш-потужність, виробничі системи мають забезпечувати обробку постійних запитів, затримки на хвості, ітерації версій, права доступу до даних і відповідальність за інциденти. Тобто, основна сфера конкуренції для корпоративного ШІ зміщується в напрямку інференсу та операційних фреймворків. Агенти ще більше ускладнюють завдання: від «одноразового Q&A» до «багатокрокових завдань, виклику інструментів і керування станом», значно підвищуючи вимоги до інфраструктури та управління.
Якщо розглядати ШІ-інфраструктуру як ланцюг від чипів до дата-центрів, сервісів і управління, ця стаття зосереджується на кінцевій ланці: сервісах інференсу, доступі до даних і організаційному управлінні. Теми на upstream, як-от HBM, енергоспоживання та дата-центри, доцільніше розглядати в контексті пропозиції; ця стаття передбачає, що читачі вже мають базове розуміння багаторівневих архітектур.
Чому «виробничий інференс» і «тренувальна хеш-потужність» — це різні виклики
Хоча тренування й інференс використовують спільні апаратні компоненти — GPU, мережі, сховище, — їх цілі оптимізації різні. Тренування орієнтується на пропускну здатність і тривалу паралельність; інференс — на одночасність, затримку на хвості, вартість одного запиту та частоту релізів і відкатів версій. Для підприємств ці відмінності безпосередньо впливають на архітектурні рішення й межі закупівель:
-
Структура витрат: Тренування — це, як правило, поетапні капітальні інвестиції, а витрати на інференс масштабуються лінійно разом із бізнес-обсягом і чутливі до кешування, пакетування, маршрутизації та вибору моделі.
-
Визначення доступності: Завдання тренування можна поставити в чергу й повторити; онлайн-інференс, як правило, підпорядкований SLA, що вимагає обмеження швидкості, деградації та стратегій із кількома репліками.
-
Частота змін: Оновлення моделі, підказок, політик інструментів і баз знань відбуваються частіше, що потребує аудитованих процесів релізу, а не одноразових впроваджень.
-
Межі даних: Тренувальні дані зазвичай зберігаються у контрольованих середовищах, а інференс часто працює з даними клієнтів, внутрішніми документами й інтерфейсами бізнес-систем, що вимагає суворіших дозволів і маскування даних.
Тому при оцінці корпоративної ШІ-інфраструктури ефективніше фокусуватися на можливостях сервісного шару — таких як шлюзи, маршрутизація, спостережуваність, реліз, права доступу й аудит — а не просто порівнювати масштаб тренувальних кластерів.
Виробничий стек інференсу: від входу до спостережуваності
Надійний стек інференсу зазвичай включає щонайменше такі модулі. Хоча постачальники можуть використовувати різні назви продуктів, основні функції залишаються незмінними.
API-шлюз і управління трафіком
Єдина точка входу для автентифікації, квот, обмеження швидкості та завершення TLS; при зовнішньому відкритті можливостей моделей шлюз слугує першим рівнем захисту для безпеки й бізнес-стратегії.
Маршрутизація моделей і керування версіями
Підприємства часто запускають кілька моделей одночасно (для різних завдань, витрат і рівнів відповідності). Маршрутизація має підтримувати розподіл за орендарями, сценаріями й рівнями ризику, а також «сірі» релізи й відкати, щоб уникати збоїв через одномоментну заміну всіх моделей.
Серіалізація, пакетування та кешування
За високої одночасності серіалізація/десеріалізація, стратегії пакетування та проєктування KV- чи семантичного кешу суттєво впливають на затримку на хвості й вартість. Кешування також створює ризики консистентності, тому потрібні чіткі політики інвалідації й роботи з чутливими даними.
Векторний пошук і інтеграція RAG (за потреби)
Retrieval-augmented generation тісно поєднує інференс із системами даних: оновлення індексу, фільтрація за дозволами, відображення фрагментів посилань і контроль ризику галюцинацій є невід’ємною частиною операційного фреймворку, а не «додатками» поза моделлю.
Спостережуваність, логування й облік витрат
Мінімум — це деталізація використання токенів, процентилів затримки й типів помилок за орендарем, версією моделі й політикою маршрутизації. Без цього складно планувати потужності й неможливо точно визначити, чи проблема виникла на рівні моделі, даних чи шлюзу.
У сукупності ці модулі визначають, чи є онлайн-досвід стабільним, витрати контрольованими, а інциденти — відслідковуваними. Відсутність бодай одного компонента часто призводить до того, що система працює добре лише на демо з низьким навантаженням, але виявляє дефекти під час пікових навантажень або змін.
Мультимодельне й гібридне розгортання: маршрутизація, вартість і суверенітет даних
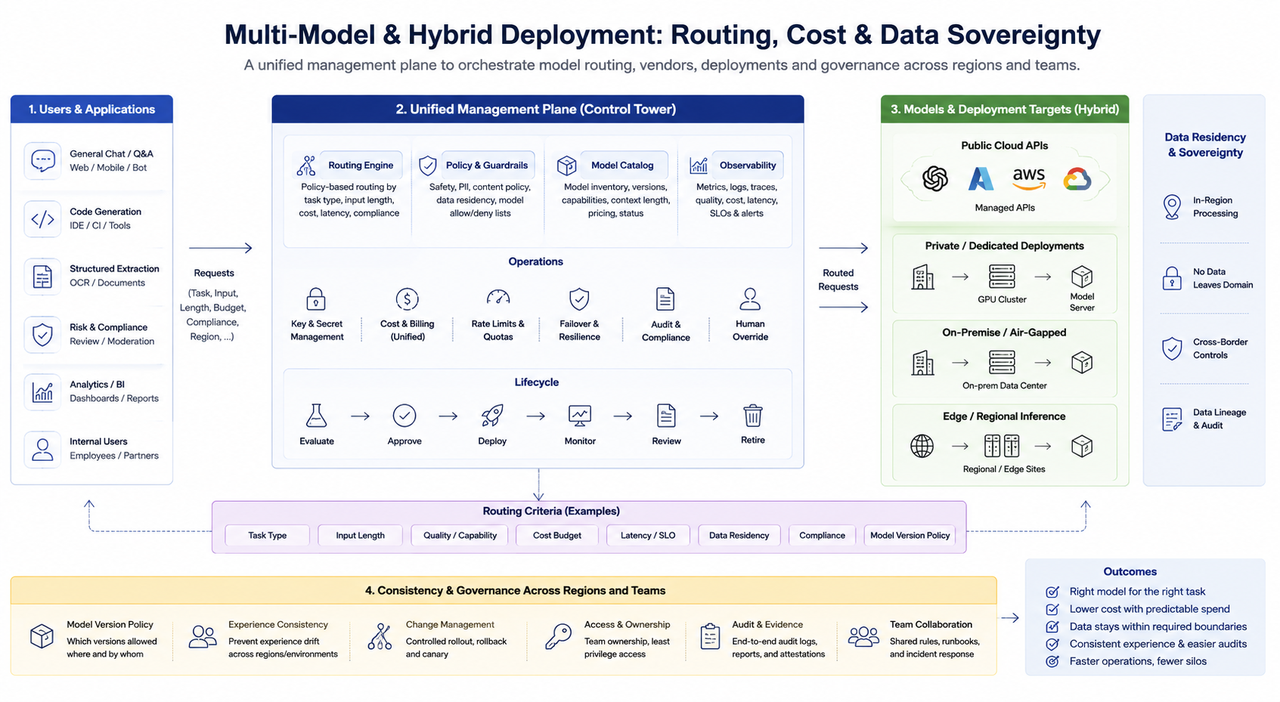
У корпоративних середовищах часто співіснують кілька моделей: завдання на зразок загальних діалогів, коду, структурованого вилучення й перевірки контролю ризиків не підходять для однієї моделі чи стратегії параметрів. Основні інженерні виклики мультимодельних рішень охоплюють:
-
Стратегію маршрутизації: Вибір моделей залежно від типу завдання, довжини вводу, обмежень за вартістю та вимог до відповідності; потрібні інтерпретовані стратегії за замовчуванням і можливість ручного втручання.
-
Мікс постачальників: Публічні хмарні API, локальні розгортання й виділені кластери можуть співіснувати; необхідно уніфікувати керування ключами, стандарти білінгу та механізми відмовостійкості, щоб уникнути «ізольованих силосів» між різними постачальниками.
-
Гібридна хмара й місце зберігання даних: Фінансові, державні та транскордонні операції часто вимагають, щоб дані залишалися в межах певної доменної області чи юрисдикції; розгортання інференсу формує архітектуру мережі та розміщення кешу, взаємодіючи з інфраструктурою третього шару — дата-центрами, енергетикою, регіональними мережами.
-
Управління консистентністю: Потрібні чіткі політики, які визначають, чи може той самий бізнес у різних регіонах чи середовищах використовувати різні версії моделей; інакше виникнуть дрейф досвіду та складності аудиту.
З організаційної точки зору складність мультимодельних систем часто полягає не в «кількості моделей», а у відсутності єдиної площини керування. Якщо правила маршрутизації, ключі, моніторинг і процеси релізу розпорошені по різних командах, витрати на усунення несправностей і дотримання вимог стрімко зростають.
Агент: оркестрація, межі інструментів і аудитованість
Агенти розширюють інференс на багатокрокові завдання: планування, виклик інструментів, операції з пам’яттю й генерування наступних дій. Для корпоративних систем це означає, що поверхня ризиків виходить за межі «текстового виводу» та охоплює виконання дій у зовнішніх системах.
Основні сфери уваги на практиці:
-
Внесення інструментів у білий список і принцип мінімальних прав: Кожен інструмент повинен мати чітко визначені межі дозволів (бази даних лише для читання, обмежені API, обмежені файлові шляхи тощо), щоб уникнути надмірно широкого «всемогутнього виклику інструментів».
-
Співпраця людини й машини та точки підтвердження: Для дій із підвищеним ризиком — таких як переказ коштів, зміна дозволів чи масовий експорт даних — обов’язково впроваджуйте процедури підтвердження або погодження, а не повну автоматизацію.
-
Сесійний стан і межі пам’яті: Довготривала пам’ять стосується приватності й циклів зберігання; короткостроковий контекст впливає на вартість і стратегії обрізання. Політики багаторівневого зберігання й очищення даних мають відповідати вимогам комплаєнсу.
-
Аудитовані логи: Фіксуйте «коли модель, на основі якого контексту, викликала які інструменти і що було повернуто»; під час аналізу інцидентів і регуляторних перевірок це часто важливіше за фінальний результат.
-
Sandbox і ізоляція: Виконання коду та завантаження плагінів вимагають ізольованих середовищ виконання, щоб запобігти ескалації атак через ін’єкцію підказок.
Агенти приносять цінність через автоматизацію, але лише за чітко визначених меж. Якщо межі розмиті, складність системи може зростати експоненційно, а операційні та юридичні витрати — виходити з-під контролю ще до появи будь-якої бізнес-користі.
Безпека й комплаєнс: «мінімальний набір» для запуску та експлуатації
Вимоги до комплаєнсу відрізняються залежно від галузі, однак виробничі системи підприємств мають щонайменше відповідати такому «мінімальному набору», розширюючи його для виконання вимог регуляторів.
-
Ідентифікація й доступ: Службові облікові записи, облікові записи користувачів, ротація API-ключів і принцип мінімальних прав; розрізняйте облікові дані для «розробки/тестування» та «виробничого виклику».
-
Дані й приватність: Маскування чутливих полів, маскування логів, розділення тренувальних і інференс-даних; чітко визначайте й зберігайте угоди про обробку даних із сторонніми постачальниками моделей.
-
Ланцюжок постачання моделей: Відстежуваність джерел моделей, хешів версій, залежностей і образів контейнерів; запобігайте потраплянню «невідомих ваг» у виробничий контур.
-
Безпека контенту й запобігання зловживанням
-
Застосовуйте політики фільтрації до вхідних/вихідних даних за потреби; впроваджуйте обмеження швидкості й детектування аномалій для автоматизованих пакетних викликів.
-
Реагування на інциденти: Відкат моделі, перемикання маршрутів, відкликання ключів, процедури інформування клієнтів; чітко визначайте відповідальних осіб і шляхи ескалації.
Ці можливості не замінюють багаторівневий захист відділу безпеки, але є критично важливими для інтеграції ШІ-сервісів у чинну систему менеджменту ризиків підприємства, а не залишення їх як довгострокових «інноваційних винятків».
Висновок
Конкурентна перевага в корпоративному ШІ зміщується з «можливості інтегрувати найновішу модель» до «здатності керувати кількома моделями й агентами з контрольованими витратами та безпечними межами». Це вимагає посилення як інженерного, так і управлінського стеку: маршрутизацію й реліз, спостережуваність і керування витратами, права на інструменти й аудитованість слід розглядати як виробничі essentials нарівні з власне моделями.









