Оскільки масштабування блокчейн-застосунків триває, ончейн-дані стали фундаментальним ресурсом для DeFi, ончейн-аналітики, AI Agents та мультичейн-застосунків. Необроблені блокчейн-дані зазвичай мають вигляд блоків, транзакцій і журналів подій, що змушує розробників проходити складні етапи вилучення та обробки, перш ніж вони зможуть їх використати. Тому ефективний доступ до ончейн-даних став ключовим викликом у розбудові інфраструктури Web3.
Subsquid (SQD) постає як децентралізована мережа даних, покликана вирішити цю проблему. На відміну від традиційних RPC-вузлів, які безпосередньо зчитують стан блокчейну, SQD пропонує архітектуру сервісу даних на основі озера даних, робочих вузлів і шару запитів Portal, що надає розробникам змогу отримувати структуровані індексовані ончейн-дані через єдиний інтерфейс.
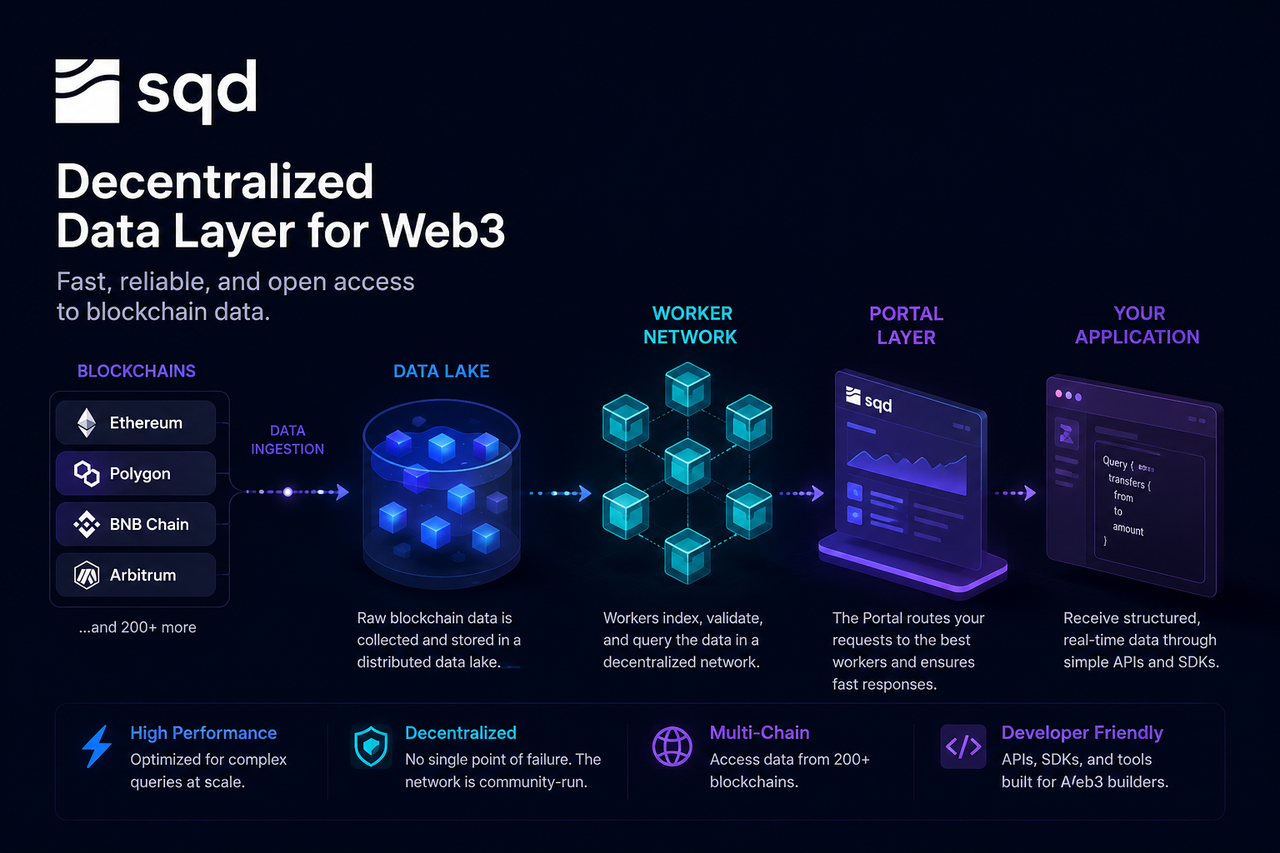
Що таке запит даних SQD?
Запит даних SQD — це процес, за допомогою якого розробники отримують ончейн-дані через мережу SQD. Замість безпосереднього звернення до блокчейн-вузлів запити SQD повертають уже попередньо оброблені та проіндексовані дані, що дає змогу швидко відповідати на складні запити.
Наприклад, панелі DeFi може знадобитися агрегувати обсяги торгів за останні кілька місяців, AI Agent — зчитувати зміни активів на кількох адресах, а аналітична платформа — запитувати всю історію подій конкретного смарт-контракту. Усі ці сценарії є типовими прикладами запитів даних.
Основна ідея SQD — перенести важку обробку даних на попередній етап, щоб застосунки могли безпосередньо отримувати структуровані дані, не обробляючи самостійно величезні обсяги необроблених блокових даних.
Як ончейн-дані потрапляють до мережі SQD
Точка відліку запиту насправді знаходиться до того, як розробник надсилає запит.
Оскільки блокчейн-мережі постійно генерують нові блоки, мережа SQD у реальному часі збирає необроблені дані — блоки, транзакції, журнали подій та зміни стану смарт-контрактів — через свою систему збору даних. Потім ці дані стандартизуються для подальшої обробки та зберігання.
Оскільки SQD підтримує кілька блокчейнів, його рівень збору даних повинен постійно синхронізувати потоки даних з різних екосистем, забезпечуючи цілісність і узгодженість даних. Після стандартизації дані записуються до шару зберігання мережі.
Як озеро даних зберігає ончейн-інформацію
Озеро даних — це основна інфраструктура зберігання в мережі SQD.
На відміну від традиційних баз даних, призначених для структурованих даних, озеро даних може обробляти великі обсяги необроблених і напівструктурованих даних. Історія блокчейну, дані транзакцій, журнали подій і знімки стану зберігаються в цьому шарі.
Перевага озера даних — збереження повної історичної інформації з можливістю гнучкої подальшої обробки та аналізу. Для застосунків, які мають відстежувати мільйони транзакцій, цей метод зберігання набагато ефективніший, ніж безпосереднє звернення до блокчейн-вузлів.
Озеро даних виконує роль довгострокової пам'яті мережі SQD, надаючи дані для подальшої індексації та запитів.
Як робочі вузли обробляють запити
Робочі вузли є виконавчим рівнем у мережі SQD.
Коли дані надходять до мережі, робочі вузли індексують, класифікують і оптимізують їх для швидкого пошуку. Процес індексації схожий на створення змісту великої енциклопедії — немає потреби сканувати все з нуля для кожного запиту.
Окрім створення індексів, робочі вузли виконують завдання запитів. Коли розробник запитує певні дані, робочий вузол швидко знаходить відповідні записи за допомогою індексу, а потім фільтрує, агрегує та обчислює результати.
Оскільки кілька робочих вузлів можуть працювати паралельно, мережа здатна обробляти багато запитів одночасно, підвищуючи загальну продуктивність і масштабованість.
Як Portal отримує запити розробників
Portal — це єдина точка входу для розробників до мережі SQD.
Розробники зазвичай надсилають запити через API або SDK, не підключаючись безпосередньо до базових вузлів. Коли запит надходить до Portal, система аналізує його та визначає, які робочі вузли найкраще підходять для його обробки.
Portal виконує роль балансувальника навантаження в інтернеті. Розробники взаємодіють лише з одним інтерфейсом, а складне планування ресурсів і вибір вузлів відбуваються автоматично на фоні.
Така конструкція спрощує розробку та підвищує загальну ефективність використання ресурсів мережі.
Як результати запитів повертаються до застосунків
Після завершення обробки робочими вузлами результати надсилаються назад до шару Portal.
Portal форматує результати відповідно до потреб і надсилає остаточні дані до застосунку. Розробники отримують вже структуровані дані — наприклад, об'єкти JSON або результати аналізу — готові до використання у фронтенді, бізнес-логіці або для висновків ШІ.
Весь процес зазвичай непомітний для кінцевих користувачів. Вони просто бачать, як завантажується сторінка або з'являються результати аналізу, тоді як на фоні вже відбулися численні етапи від збору даних до виконання запиту.
Як Hotblocks підтримує запити даних у реальному часі
Окрім історичних запитів, багатьом застосункам потрібна ончейн-інформація в реальному часі.
Наприклад, системи ончейн-моніторингу повинні виявляти аномальні транзакції, автоматизовані стратегії потребують прослуховування подій смарт-контрактів, а AI Agents мають бути в курсі останніх ринкових умов. Такі сценарії вимагають, щоб дані були доступні одразу після створення нового блоку.
Hotblocks — це шар даних реального часу, який надає SQD, спеціально розроблений для нових блоків і живих подій. Порівняно з історичними даними в озері даних, Hotblocks орієнтований на низьку затримку та швидку відповідь, що дозволяє розробникам створювати застосунки реального часу.
Чим запити SQD відрізняються від традиційних запитів RPC
Обидва методи можуть отримувати ончейн-дані, але основна логіка дуже різна.
Традиційні RPC-вузли схожі на безпосереднє звернення до бази даних блокчейну. Кожен запит повинен знайти відповідні дані з ончейн-стану або історичних записів. Зі зростанням обсягу запиту збільшуються продуктивність і витрати.
SQD, навпаки, використовує попередньо індексовану архітектуру. Дані вже організовані та проіндексовані під час надходження до мережі, тому запити не потребують повторного сканування всієї історії. Для складного аналізу, агрегації даних з кількох ланцюжків та довгострокової історичної статистики SQD зазвичай забезпечує набагато вищу ефективність.
| Вимір |
SQD |
Традиційний RPC |
| Джерело даних |
Попередньо індексовані дані |
Зчитування ончейн у реальному часі |
| Ефективність запитів |
Висока |
Середня |
| Аналіз історичних даних |
Значна перевага |
Складніше |
| Підтримка мультичейн |
Сильна |
Залежить від кількох вузлів |
| Вартість інфраструктури |
Нижча |
Вища |
| Зчитування стану в реальному часі |
Підтримується |
Підтримується |
Як процес запитів SQD важливий для AI Agents
AI Agents стають ключовим застосунком в інфраструктурі Web3, і доступ до даних є основою їхньої роботи.
Якщо AI Agent потребує аналізу поведінки гаманців, відстеження стану протоколів або виконання ончейн-дій, він повинен постійно отримувати точні структуровані дані. Традиційні RPC-запити можуть надавати необроблені дані, але зазвичай вимагають додаткової обробки та перетворення.
Уніфікований інтерфейс даних, який надає SQD, зменшує складність отримання ончейн-інформації для AI Agents. Завдяки стандартизованим результатам запитів системи ШІ можуть виділяти більше обчислювальних потужностей на аналіз і прийняття рішень, а не на роботу з даними.
У міру подальшого зближення ШІ та Web3 важливість децентралізованих шарів даних лише зростатиме.
Підсумок
Запит даних SQD — це не просто зчитування даних, а повний робочий процес, у якому беруть участь рівень збору даних, озеро даних, робочі вузли та шар Portal, що працюють разом. Необроблені блокчейн-дані спочатку збираються та зберігаються, потім індексуються та оптимізуються, і нарешті доставляються розробникам через єдиний інтерфейс.
Ця попередньо індексована розподілена модель обробки дозволяє SQD досягати високої ефективності для складних запитів, мультичейн-аналізу та доступу до даних у реальному часі. Оскільки DeFi, ончейн-аналітичні платформи та AI Agents потребуватимуть дедалі більше даних, шар даних, представлений SQD, стає невід'ємною частиною інфраструктури Web3.
Поширені запитання
Яка різниця між запитом даних SQD і звичайним запитом API?
Звичайний API зазвичай підтримується централізованим провайдером, тоді як запит SQD виконується в децентралізованій мережі даних. Дані SQD надходять із систем збору та індексації ончейн, що забезпечує більш відкритий і перевірний доступ до даних.
Чому швидкість запитів SQD вища, ніж у деяких запитів RPC?
SQD виконує індексацію та організацію заздалегідь, тому запити не потребують повторного сканування великих обсягів історії блоків. Для складного аналізу та історичних даних SQD зазвичай набагато швидший.
Яку роль відіграють робочі вузли в процесі запиту?
Робочі вузли виконують індексацію, фільтрацію, агрегацію та обчислення. Коли Portal отримує запит, відповідні робочі вузли виконують фактичну обробку даних.
Яка різниця між озером даних і базою даних?
База даних зазвичай зберігає структуровані дані, тоді як озеро даних може зберігати величезні обсяги необроблених і напівструктурованих даних. SQD використовує озеро даних для зберігання повної ончейн-історії, підтримуючи гнучкі запити та аналіз.
Чи може Hotblocks замінити запити історичних даних?
Ні. Hotblocks призначений для доступу до даних у реальному часі; історичні запити все ще покладаються на озеро даних та систему індексації. Разом вони формують повний спектр послуг даних SQD.
Які застосунки найкраще підходять для сервісів запитів SQD?
Панелі DeFi, блокчейн-експлорери, ончейн-аналітичні платформи, системи моніторингу в реальному часі, мультичейн-застосунки та AI Agents — будь-які сценарії, що потребують частого доступу до ончейн-даних, є ідеальними для сервісів запитів SQD.








