當推理負載從測試集群擴展到實際業務時,「全部集中於超大規模數據中心」不再是預設的最佳方案。本文從延遲、頻寬、可用性與合規等角度,梳理邊緣節點、區域機房與中心集群的分層邏輯,說明混合拓撲下的任務切分、數據邊界及運維治理要點,並與 AI 基礎設施全鏈條進行對照分析。
在主流論述中,AI 算力常與「超大規模數據中心 + 高端 GPU」綁定。對於訓練及部分集中式推理而言,此定義大致成立。AI 基礎設施中,推理請求分布廣、時延敏感、數據不可離域,且網路中斷或峰值壅塞不可接受。此時,推理拓撲本身成為基礎設施問題:算力不僅要具備,還需出現在「正確的地理位置與正確的網路層級」。
若將 AI 基礎設施視為自晶片向上延伸至服務與治理的連續鏈條,本文聚焦拓撲與部署型態:如何於邊緣、區域與中心間分配運算與數據,使系統在延遲、成本、可用性與合規間取得平衡。更上游的電力、封裝與 HBM 等議題,適合於供給側專題深入;企業端多模型路由與 Agent 治理細節則與生產運行體系專題互補。
為何需要討論「分布式推理拓撲」
集中式推理具備運維統一、彈性擴縮及資源複用率高等優勢。但當業務出現下列特徵之一時,拓撲決策將顯著影響體驗與成本:
-
強時延約束:工業控制、即時互動、音視頻鏈路、線下門市等對尾延遲敏感,回源路徑過長將放大抖動。
-
數據主權與駐留:個人資訊、金融交易、政務與醫療等場景常要求數據不出域、不出境或不出指定區域。
-
回源頻寬與成本:大量終端持續上傳原始數據至中心推理,骨幹網與出口費用可能成為主要成本項。
-
可用性與韌性:廣域網故障、DNS 波動、跨區域壅塞時,純中心架構更易出現「全站不可用」的級聯風險。
-
離線或弱網:礦場、船舶、部分製造現場等環境需具備本地可運行能力,而非高度依賴即時在線。
這些問題無法僅靠「更強中心模型」解決,因為核心矛盾在於物理距離、網路路徑與政策邊界,而非單次推理的算力峰值。
分層部署:邊緣、區域與中心各自解決什麼
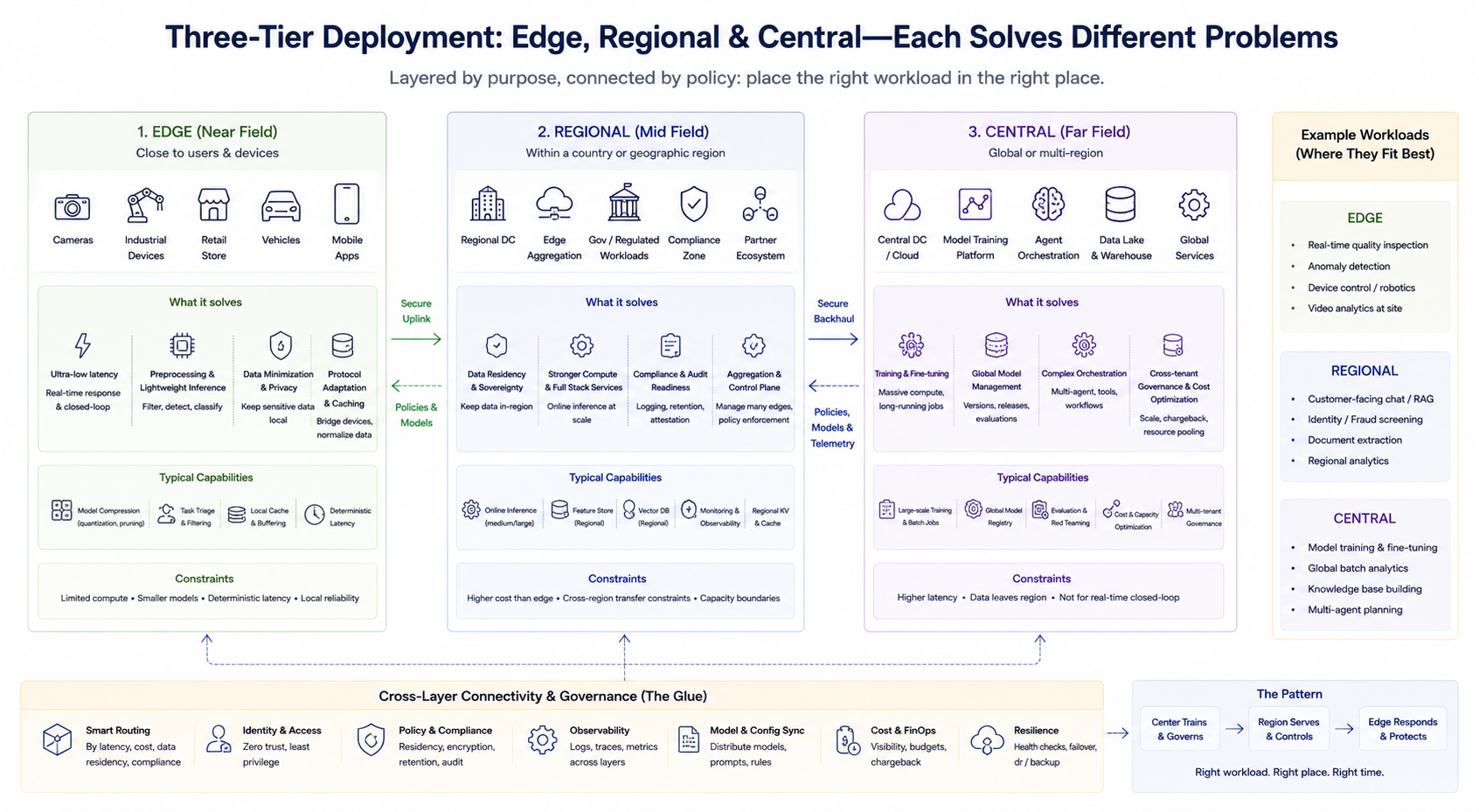
工程實踐中常見的並非二選一,而是分層組合。可用簡化框架理解各層職責(具體命名依廠商而異):
邊緣層(近場)
接近用戶或設備,負責低延遲預處理、輕量推理、快取及協定適配;適合實時閉環與敏感數據最小化上傳。邊緣算力通常有限,更重視模型壓縮、任務裁剪與確定性時延。
區域層(中場)
於特定國家或地理區域提供較強算力與完整服務棧,用於數據駐留、合規稽核及中等規模聚合推理;亦常作為多邊緣節點的匯聚與控制面。
中心層(遠場)
負責訓練、大規模批次處理、全域模型管理、複雜 Agent 編排、跨租戶統一治理與成本優化;適合對延遲不敏感但對算力與數據聚合要求高的工作負載。
三層間並非固定等級關係,而是按業務切分任務。企業可同時存在:中心訓練 + 區域線上推理 + 邊緣即時偵測,並透過路由策略將請求送至適合層級。
任務切分:哪些留在邊緣,哪些回到中心
切分原則通常圍繞數據最小化、延遲預算、模型複雜度與更新頻率四軸展開。
適合傾向邊緣的任務(在滿足算力前提下)
-
即時特徵提取、目標偵測、品質抽檢等低延遲閉環
-
本地去識別化後的輕量推理(如僅上傳特徵向量而非原始媒體)
-
弱網環境下的備援推理及快取命中策略
適合傾向中心或區域的任務
-
需大上下文、強模型、複雜工具鏈或多系統編排的 Agent 流程
-
需跨部門數據聚合的分析型推理
-
需集中稽核與統一密鑰管理的敏感調用
切分錯誤的典型表現包括:將大模型長上下文強行塞入邊緣導致 OOM,或將必須低延遲的閉環完全回源導致產線節拍失控。拓撲設計目標不是「邊緣越多越好」,而是在約束條件下將正確工作放在正確位置。
數據主權與合規:拓撲倒推架構
數據主權要求將直接改變推理部署型態:模型可下載至本地,但日誌、快取、向量索引與調用軌跡仍可能構成合規風險。實務中需同時回答:
-
哪些數據必須留在邊緣或區域內存儲與運算
-
哪些元數據可出境或上雲,是否需匿名化及留存週期
-
跨區域是否允許使用不同模型版本與不同供應商(避免「合規漂移」)
-
稽核取證時能否還原「於某地、某時、基於何種數據片段」產生輸出
這些問題的答案往往比「模型是否開源」更決定系統能否上線。換言之,合規不是邊緣推理的附加項,而是拓撲設計的前提條件。
網路、電力與運維:分布式帶來的真實成本
分布式推理的效益伴隨系統性成本,規劃階段需明確評估:
-
網路:邊緣與區域節點增加後,憑證管理、專線 / SD‑WAN、DNS及流量調度複雜度提升;多路徑下尾延遲更難治理。
-
電力與機房:邊緣站點分散,單位算力的能源效率與散熱條件可能弱於大型數據中心;區域機房則介於兩者之間。上游電力與機櫃交付節奏仍會約束擴張速度,只是約束點由「單一園區」轉為「多點並行」。
-
運維與版本一致性:模型、提示詞、路由策略與索引於多點發布時,易出現版本漂移;需統一發布管道、回滾策略與健康檢查,否則排障成本將迅速吞噬邊緣帶來的延遲效益。
-
安全面擴大:更多節點意味著更多憑證、更多入口、更多本地儲存介質;邊緣環境物理安全與修補節奏常弱於中心機房,需針對性最小權限及遠端管控策略。
因此,分布式拓撲不是「將算力推遠」這麼簡單,而是將部分運維與治理複雜度外推至更貼近業務現場的位置;若組織能力與平台工具未同步,拓撲優勢難以兌現。
與中心推理的關係:混合架構如何落地
多數成熟方案採用混合架構:中心負責訓練、全域策略及重任務;區域負責合規區域內的線上服務;邊緣負責低延遲及本地韌性。落地時常見工程模式包括:
-
分層快取與結果複用:邊緣命中高頻請求,未命中再回源;需定義快取鍵、TTL及敏感數據策略。
-
模型拆分與小模型前置:邊緣運行偵測或分類小模型,中心運行大模型融合及解釋生成(依場景評估)。
-
非同步回傳與聚合:邊緣先做即時決策,再將去識別化樣本或指標非同步回傳用於模型迭代及監控。
-
統一控制面:路由、配額、觀測及密鑰管理盡量集中,執行面分散,以降低「每個邊緣一套孤島」的風險。
混合架構的關鍵成功因素,通常是控制面統一、執行面分層,而非單純增加節點數量。
結語
邊緣與分布式推理討論的核心,不是「去中心化口號」,而是於延遲、頻寬、合規及運維成本間做工程取捨。當業務從 demo 走向規模化,拓撲選擇將反過來影響模型型態、網路架構與組織流程;忽略這一層,易出現中心算力很強、現場體驗仍不穩定的錯位。
分享
目錄


相關文章

USD.AI 效益來源解析:AI 基礎設施貸款如何創造收益

USD.AI 代幣經濟學:深入解析 CHIP 代幣的應用場景與激勵機制

Arweave:用AO電腦捕捉市場機會

即將到來的AO代幣:可能是鏈上AI代理的終極解決方案

Theta Network 的節點體系是什麼?Validator、Guardian 與 Edge Node 全解析
