大模型能力快速提升之后,企业侧更常见的矛盾并不是「有没有模型可用」,而是「能不能在真实业务里长期跑下去」。训练集群可以集中堆算力,但生产系统面对的是持续请求、尾延迟、版本迭代、数据权限与事故追责。换句话说,企业 AI 的核心战场正在转向推理与运行体系;Agent 进基础设施一步把问题从「单次问答」扩展为「多步任务、工具调用与状态管理」,对基础设施与治理的要求显著提高。
若将 AI 基础设施理解为从芯片到机房、再到服务与治理的连续链条,本文聚焦链条末端:推理服务、数据接入与组织治理。更上游的 HBM、电力与数据中心等话题,更适合在供给侧专题中展开;本文默认读者已具备「分层阅读」的基本坐标。
为何「生产推理」与「训练算力」不是同一套问题
训练与推理共享 GPU、网络与存储等部件,但优化目标不同。训练更关注吞吐与长时间并行;推理更关注并发、尾延迟、单位请求成本,以及版本发布与回滚节奏。对企业而言,以下差异会直接影响架构选型与采购边界:
-
成本结构:训练多为阶段性资本支出;推理成本往往随业务量线性累积,对缓存、批处理、路由与模型选择更敏感。
-
可用性定义:训练任务可以排队重试;线上推理通常绑定 SLA,需要限流、降级与多副本策略。
-
变更频率:模型与提示词、工具策略、知识库更新更频繁,需要可审计的发布流程,而不是一次性上线。
-
数据边界:训练数据多在受控环境;推理往往触达客户数据、内部文档与业务系统接口,权限与脱敏要求更高。
因此,评估「企业 AI 基础设施」时,更适合从 服务层能力 出发:网关、路由、观测、发布、权限与审计是否齐备,而不是仅比较训练集群规模。
生产级推理栈:从入口到观测
一套可落地的推理栈,通常至少包含以下模块。不同厂商产品命名不同,但职能相对稳定。
API 网关与流量治理
统一入口用于鉴权、配额、限流与 TLS 终止;对外暴露模型能力时,网关是安全与商业策略的第一道闸。
模型路由与版本管理
企业往往同时运行多个模型(不同任务、不同成本、不同合规等级)。路由需要支持按租户、按场景、按风险等级分流,并支持灰度与回滚,避免「全量替换一次失败」。
序列化、批处理与缓存
高并发下,序列化与反序列化、批处理策略、以及 KV cache 或语义缓存设计,会显著影响尾延迟与成本。缓存同时引入一致性风险,需要明确失效策略与敏感数据策略。
向量检索与 RAG 接入(如采用)
检索增强生成把推理与数据系统绑定:索引更新、权限过滤、引用片段展示与幻觉风险控制,都属于运行体系的一部分,而不是模型之外的「附加功能」。
观测、日志与成本核算
至少应能按租户、按模型版本、按路由策略拆分 token 用量、延迟分位数与错误类型;否则很难做容量规划,也无法在事故后复盘「是模型、数据还是网关」导致的问题。
上述模块共同决定:线上体验是否稳定、成本是否可控、问题是否可定位。缺少其中一环,系统往往在低负载 demo 阶段表现良好,在峰值或变更时暴露缺陷。
多模型与混合部署:路由、成本与数据主权
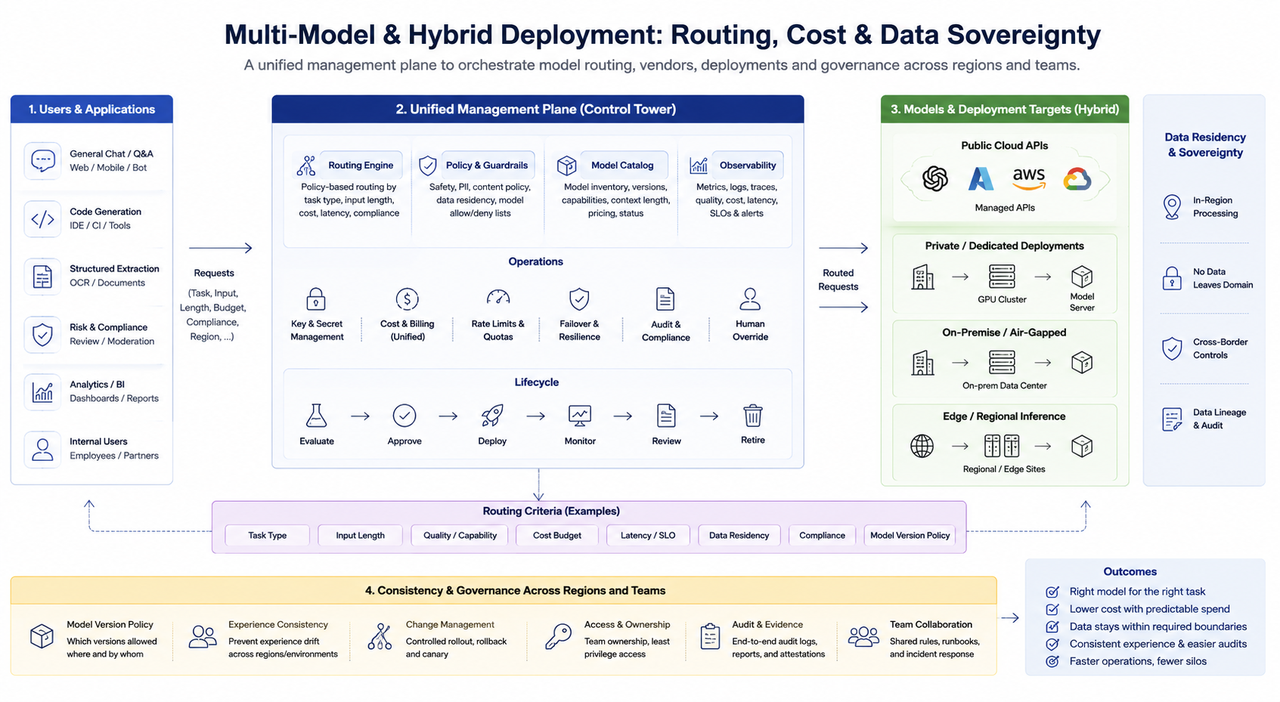
企业环境常见多模型并存:通用对话、代码、结构化抽取、风控审核等任务并不适合用同一模型与同一参数策略承担。多模型带来的主要工程问题包括:
-
路由策略:按任务类型、输入长度、成本预算与合规要求选择模型;需要可解释的默认策略与可运营的人工 override。
-
供应商组合:公有云 API、私有化部署、专属集群可能并存;需要统一的密钥管理、计费口径与故障切换,避免「多供应商等于多套孤岛」。
-
混合云与数据驻留:金融、政务、跨国业务常要求数据不出域或不出境;推理部署形态会倒推网络架构与缓存位置,并与第三层基础设施(机房、电力、区域网络)产生联动。
-
一致性治理:同一业务在不同区域、不同环境是否允许使用不同模型版本,需要明确策略,否则会出现体验漂移与审计困难。
从组织视角看,多模型系统的难点往往不在「模型数量」,而在 缺少单一管理面:路由规则、密钥、监控与发布流程分散在多个团队时,故障排查与合规举证成本会快速上升。
Agent:编排、工具边界与可审计性
Agent 将推理扩展为多步任务:规划、调用工具、读写记忆、再生成下一步动作。对企业系统而言,这意味着风险面从「文本输出」扩展到 对外部系统的可执行影响。
实践中建议重点关注:
-
工具白名单与最小权限:每个工具绑定明确权限范围(只读数据库、限定 API、限定文件路径等),避免泛化「万能工具调用」。
-
人机协同与确认点:对资金划转、权限变更、批量数据导出等高风险动作,设置强制确认或审批流,而不是完全自动化。
-
会话状态与记忆边界:长期记忆涉及隐私与留存周期;短期上下文涉及成本与截断策略。需要数据分级与清理策略,并与合规要求对齐。
-
可审计轨迹:记录「模型在何时、基于何种上下文、调用了哪些工具、返回了什么」;事故复盘与监管问询往往依赖这一层,而不是仅保存最终回答。
-
沙箱与隔离:代码执行、插件加载等能力需要隔离运行环境,防止提示注入升级为执行面攻击。
Agent 的价值在于自动化,但 自动化的前提是边界清晰。边界不清时,系统复杂度会指数上升,运维与法务成本往往先于业务收益失控。
安全与合规:上线前与运行中的「最小集合」
不同行业合规要求不同,但企业生产系统通常至少应覆盖以下「最小集合」,再按监管要求扩展。
-
身份与访问:服务账号、人员账号、API Key 轮换、最小权限原则;区分「开发调试」与「生产调用」凭证。
-
数据与隐私:敏感字段脱敏、日志脱敏、训练 / 推理数据隔离;对第三方模型服务商的数据处理条款进行明确约定与留存证据。
-
模型供应链:模型来源、版本哈希、依赖库与容器镜像的可追溯;防止「未知权重」直接进入生产路径。
-
内容安全与滥用防护
-
对输入输出进行策略过滤(视业务而定);对自动化批量调用进行速率限制与异常检测。
-
事件响应:模型回滚、路由切换、密钥吊销、客户通知流程;明确责任人与升级路径。
这些能力并不替代安全团队的纵深防御,但决定 AI 服务能否被纳入企业现有的风险管理框架,而不是长期游离在「创新例外」之外。
结语
企业 AI 的竞争点,正在从「能否接入最新模型」转向「能否以可控成本与安全边界运行多模型与 Agent」。这要求同时补齐工程栈与治理栈:路由与发布、观测与成本、工具权限与审计轨迹,应被视为与模型同等重要的生产要素。
分享
摩根士丹利将 KOSPI 目标维持在 9,000;7 月 21 日临近底部之际,指数接近触底
Hyperliquid 鲸鱼在 11 月休眠后恢复质押价值 61.16M 美元的 1.006M HYPE
特朗普宣布仿制药关税将在两年内上调至 100%,随后上调至 200%,并自 8 月 1 日起生效
大信证券维持对三星电子的“买入”评级,并在 7 月 22 日设定 560,000 韩元目标价
摩根士丹利比特币信托 ETF 于 7 月 21 日从 Coinbase Prime 提取 106.04 BTC


相关文章

GateClaw 与 AI Skills:Web3 AI Agent 的能力体系解析

GateClaw 的核心功能:Web3 AI Agent 工作站能力解析

一文盘点 Top 10 AI Agents

解读 Vana 的野心:实现数据货币化,构建由用户主导的 AI 开发生态

什么是 TAO?Bittensor 代币经济学、供应模型与激励机制详解
