
Autor: Phosphen
Übersetzung; Gans Gans, Bagel Prognosemarktbeobachtung
Dieser Mann hat alle Profispielergebnisse des Tennis der letzten 43 Jahre gesammelt, alles in ein Machine-Learning-Modell eingespeist und nur eine Frage gestellt: Kannst du vorhersagen, wer gewinnt?
Das Modell antwortete nur mit einem Wort: Ja.
Danach prognostizierte es bei den Australian Open dieses Jahres 116 Spiele korrekt, mit einer Genauigkeit von 85%!
Dies waren Spiele, die das Modell während des Trainings noch nie gesehen hatte, und es hat sogar jeden einzelnen Finalsieg vorhergesagt.

All dies wurde nur mit einem Laptop, kostenlosen Daten und Open-Source-Code erreicht, erstellt von @theGreenCoding.
Im Folgenden werde ich dieses goldene Projekt vollständig aufschlüsseln, vom Rohdaten bis zur erfolgreichen Vorhersage. Das wird der beeindruckendste AI + Prognose-Fall sein, den du je gesehen hast.
Ausgangspunkt: Ein Ordner mit 43 Jahren Tennisdaten
Die Geschichte beginnt mit einem Datensatz, der als „Sportdaten-Heiligtum“ gilt.
Dieser Datensatz umfasst alle professionellen ATP-Turniere von 1985 bis 2024.
Breakpoints, Doppelfehler, Vorhand, Rückhand, Spielergröße, Alter, Rang, historische Begegnungen, Spielplätze… ATP hat jede einzelne Punktstatistik verfolgt.
Vierzig Jahre CSV-Dateien, alles in einem Ordner.
Als er den vollständigen Datensatz öffnete, stürzte sein Computer ab.
Doch er gab nicht auf. Für die 95.491 Spiele im Datensatz berechnete er zusätzlich eine Vielzahl abgeleiteter Merkmale:
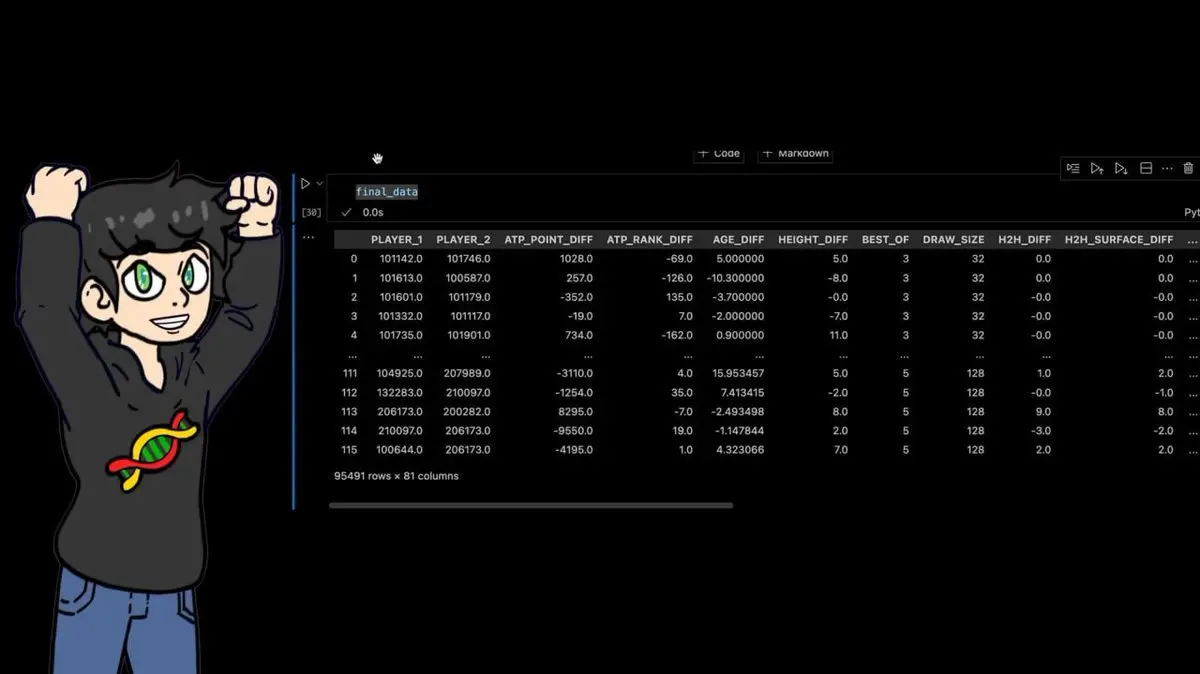
- Historische Begegnungen zwischen den beiden Spielern
- Altersunterschied, Größendifferenz
- Gewinnraten der letzten 10, 25, 50, 100 Spiele
- Differenz bei der ersten Aufschlagquote
- Differenz bei der Breakpoint-Rettungsrate
- Ein selbst entwickeltes ELO-Bewertungssystem, inspiriert vom Schach (Schlüsselpunkt)
Endgültiger Datensatz: 95.491 Zeilen × 81 Spalten.
Jedes Profispiel der letzten vierzig Jahre, ergänzt durch Dutzende manuell berechneter Merkmale.
Zweiter Schritt: Vom Schach inspiriertes Algorithmus-Design

Bevor er die Daten in den Klassifikator einspeiste, wollte er die Funktionsweise des Algorithmus vollständig verstehen. Deshalb schrieb er eine Entscheidungsbaum-Implementierung von Grund auf mit numpy.
Der Entscheidungsbaum funktioniert ähnlich wie ein Rätselspiel – durch eine Reihe von Fragen nähert man sich der Antwort.
Um dieses Konzept zu verdeutlichen, wählte er einen ganz anderen Datensatz: die Titanic.
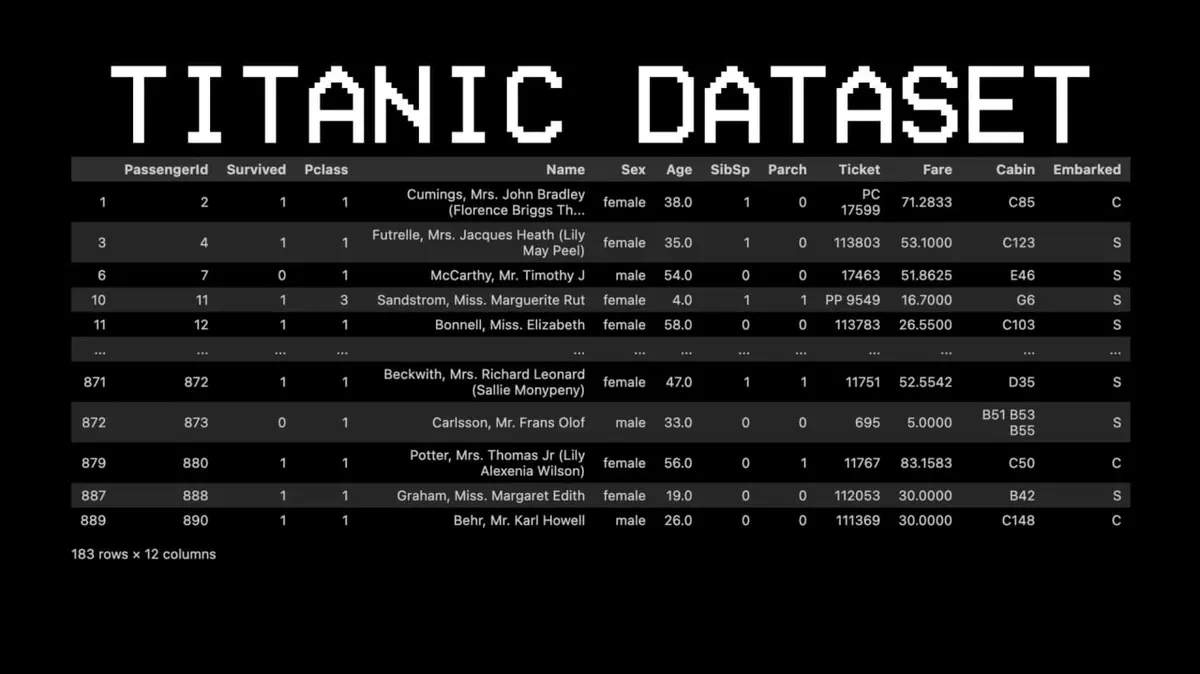
Beispiel: Überlebt Passagier Nr. 11?
- Frage 1: War er in der First Class? → Ja.
- Frage 2: War er weiblich? → Ja.
- Vorhersage: Überlebt.
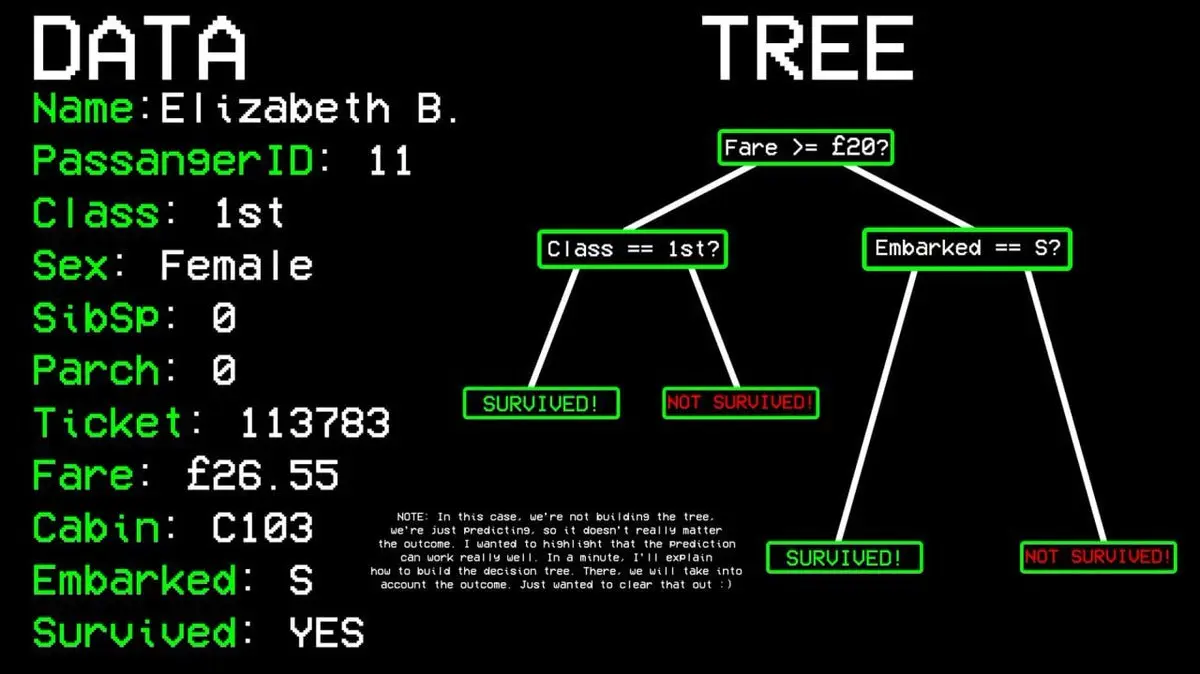
Wie entscheidet der Algorithmus, welche Fragen er stellt?
Er sucht aus allen Daten die Variable, die am besten zwischen „Überlebt“ und „Nicht Überlebt“ trennt. Bei der Titanic ist das die Kabinenklasse. First-Class-Passagiere auf der einen Seite, alle anderen auf der anderen.
Doch auch in der First Class gibt es Opfer, es ist also nicht perfekt. Der Algorithmus sucht weiter nach dem besten Split-Punkt, z.B. Geschlecht. Alle weiblichen First-Class-Passagiere überlebten, was einen „reinen Knoten“ bildet, und die Verzweigung endet hier.
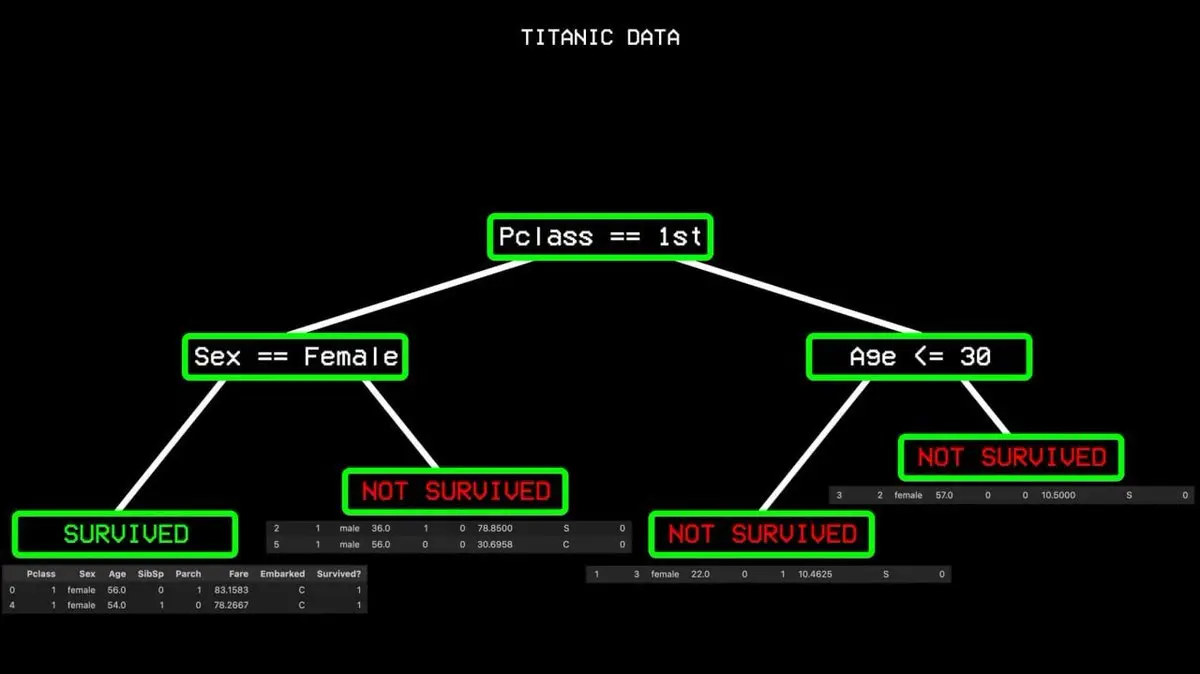
Dieser Vorgang wird wiederholt, bis eine vollständige Entscheidungsbaum-Struktur entsteht, die alle Fälle abdeckt.
Seine numpy-Implementierung funktionierte gut bei kleinen Datensätzen, aber bei 95.000 Tennisspielen wurde sie extrem langsam. Deshalb wechselte er im Trainingsprozess zu sklearns optimierter Version, die denselben Algorithmus nutzt, aber viel schneller ist.
Dritter Schritt: Die Schlüsselfaktoren für Sieg und Niederlage finden
Vor dem Trainieren des Modells zeichnete er alle Variablen paarweise in eine große Streudiagrammmatrix (SNS pairplot), um Muster zu erkennen, die Sieger von Verlierern unterscheiden.

Die meisten Merkmale waren Rauschen. Spieler-ID war offensichtlich nutzlos. Die Differenz bei der Gewinnrate zeigte einige Muster, war aber nicht eindeutig genug für eine zuverlässige Klassifikation.
Nur eine Variable stach deutlich hervor: die ELO-Differenz (ELO_DIFF).
Das Streudiagramm von ELO_DIFF und ELO_SURFACE_DIFF zeigte eine klare Trennung zwischen den beiden Klassen, keine andere Variable kam auch nur annähernd heran.
Diese Erkenntnis führte zur Kernkomponente des Projekts.
Vierter Schritt: Das Schach-Bewertungssystem auf Tennis anwenden
ELO ist eine Methode zur Bewertung der Spielstärke, ursprünglich für Schach entwickelt. Der aktuelle Weltmeister Magnus Carlsen hat 2833 Punkte.

Er beschloss, dieses System auf Tennis zu übertragen:
- Jeder Spieler startet mit 1500 Punkten
- Sieg: Punkte steigen; Niederlage: Punkte fallen
- Kernmechanismus: Der Gewinn oder Verlust hängt vom Unterschied der ELO-Punkte ab. Gegen einen höher bewerteten Gegner gibt es mehr Punkte, gegen einen niedriger bewerteten weniger.
Er demonstrierte dieses System anhand des Wimbledon-Finals 2023: Carlos Alcaraz (2063 Punkte) gegen Novak Djokovic (2120 Punkte). Alcaraz gewann nach Rückstand.

Einsetzen in die Formel: Alcaraz +14 Punkte, Djokovic -14 Punkte.
Obwohl die Berechnung einfach ist, zeigt sie bei den 43 Jahren historischen Daten eine erstaunliche Kraft.
Fünfter Schritt: Visualisierung der Dominanz der „Big Three“
Er zeichnete die ELO-Entwicklung von Federer über seine gesamte Karriere auf, von Debüt bis Rücktritt, mit jedem Match.
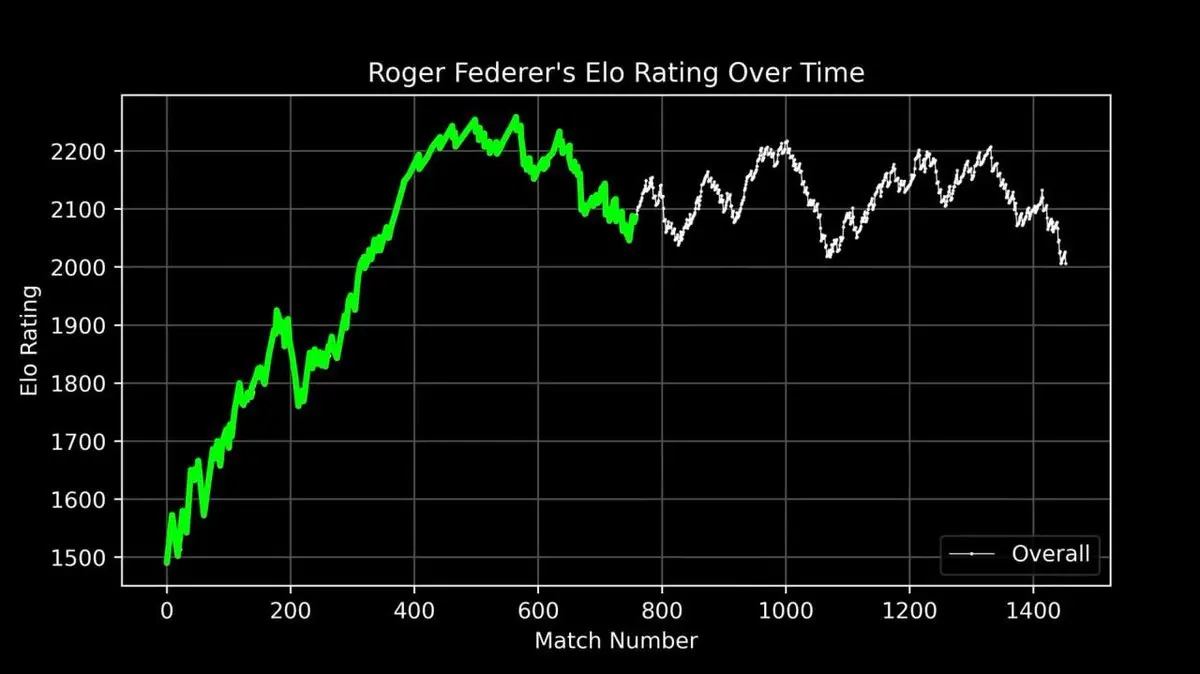
Diese Kurve zeigt eine legendäre Karriere: den schnellen Aufstieg, die absolute Dominanz um die 400. Matchphase, und die Schwankungen im späteren Verlauf.
Doch noch beeindruckender ist die Visualisierung von Federer, Nadal und Djokovic zusammen:
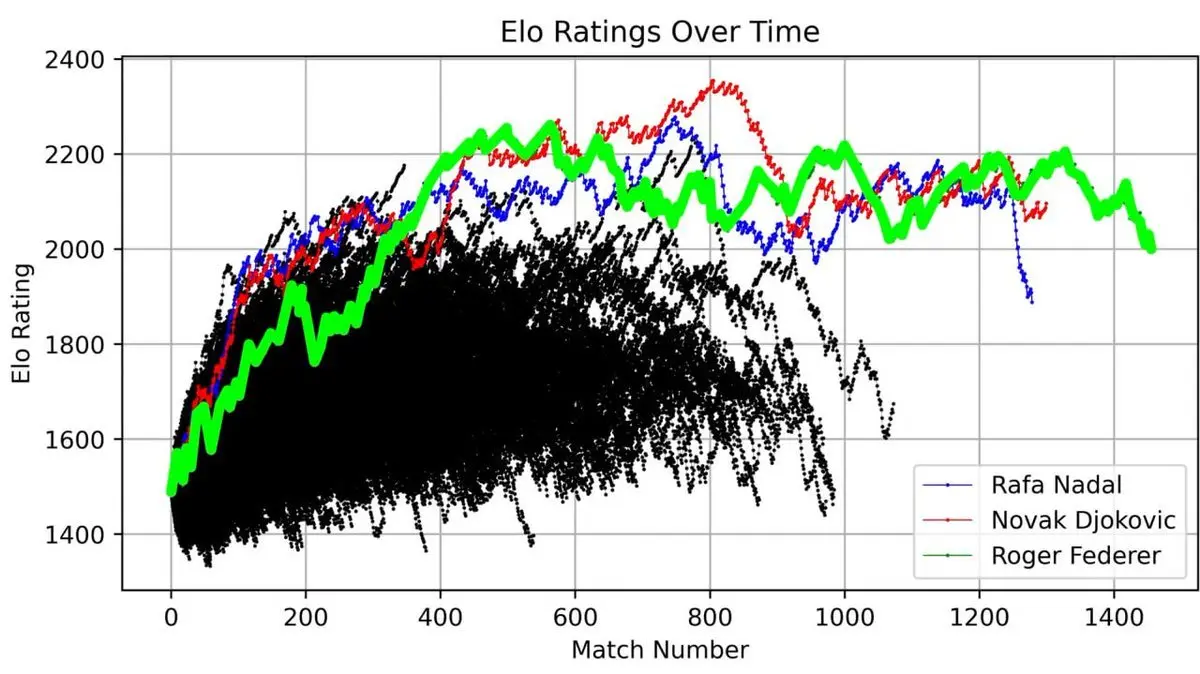
Drei Linien, die weit über alle anderen hinausragen – Federer (grün), Nadal (blau), Djokovic (rot).
„Die Big Three“ sind nicht nur ein Titel. Wenn man 40 Jahre Daten visualisiert, wird diese Dominanz mathematisch sichtbar.
Nach seinem eigenen ELO-System ist der aktuelle Weltranglistenerste Jannik Sinner mit 2176 Punkten, gefolgt von Djokovic (2096) und Alcaraz (2003).

Merke: Sinner ist auf Platz eins – das wird später noch wichtig.
Sechster Schritt: Der Spielplatz ist die Variable, die alles verändert
Der Spielplatztyp beeinflusst das Spiel grundlegend:
- Rote Erde: langsam, hoher Bounce
- Gras: schnell, niedriger Bounce
- Hartplatz: mittleres Tempo
Ein Spieler, der auf einem Platz dominieren kann, kann auf einem anderen komplett scheitern.
Deshalb hat er für jeden Belag eine eigene ELO-Bewertung entwickelt: Rote Erde, Gras, Hartplatz.
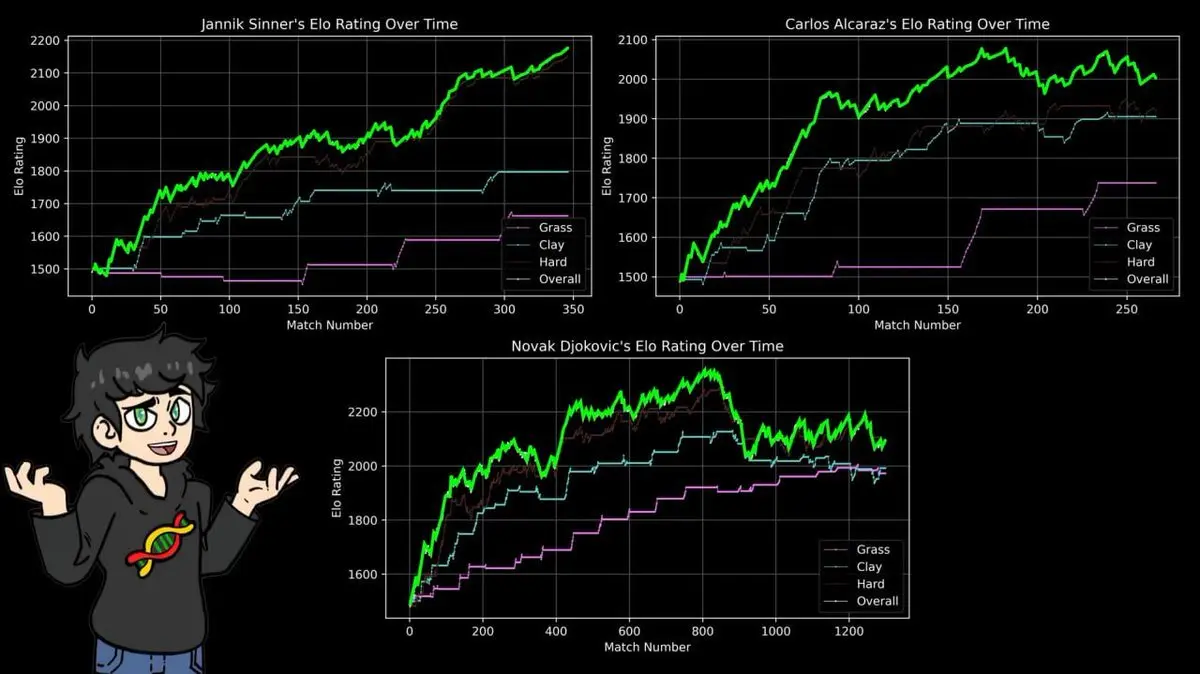
Das bestätigt die bekannte Tennisweisheit und stützt sich auf 43 Jahre Daten:
Nadal auf Roter Erde mit der höchsten Bewertung, Federer auf Gras, Djokovic auf Hartplatz – jeder hat seine Spezialdisziplin.
14 French Open-Titel, 112 Siege, 4 Niederlagen bei Roland Garros.
Das ELO-System ist narrativ-unabhängig, es bewertet nur Sieg und Niederlage. Seine Ergebnisse stimmen exakt mit den Sportberichten der letzten 40 Jahre überein.
Siebter Schritt: Die Grenzen des Systems
Daten vorbereitet, ELO-System aufgebaut, nun das Training des Klassifikators. Das zeigt deutlich, wie wichtig die Wahl des Algorithmus ist.
Entscheidungsbaum: 74% Genauigkeit
Ein einzelner Entscheidungsbaum erreichte auf dem vollständigen Datensatz 74%. Klingt gut – bis man merkt, dass allein die ELO-Differenz 72% erreicht.
Der Baum auf Basis des manuell entwickelten ELO-Systems brachte kaum Verbesserung.
Random Forest: 76%
Das Problem des einzelnen Baumes ist die „hohe Varianz“ – er ist zu empfindlich gegenüber den Trainingsdaten. Die Lösung: Random Forests, bei denen viele Bäume (z.B. 94) mit unterschiedlichen Daten- und Merkmals-Sets trainiert werden, und die Mehrheitsentscheidung fällt.

94 verschiedene Bäume stimmen ab.

Das Ergebnis: 76%. Eine Steigerung, aber eine Grenze ist erreicht. Egal, wie man die Hyperparameter anpasst oder die Merkmale verändert – die Genauigkeit bleibt bei maximal 77%.
Achter Schritt: Über die Grenze hinaus
Er probierte XGBoost, das er „die Steroid-Version des Random Forest“ nennt.
Der Unterschied: Random Forest baut parallel viele Bäume, XGBoost baut sie seriell, wobei jeder neue Baum die Fehler der vorherigen korrigiert. Es nutzt Regularisierung, um Overfitting zu vermeiden, und hält die Bäume klein.
Ergebnis: 85% Genauigkeit.
Das ist ein riesiger Sprung gegenüber den 76% des Random Forests. Mit denselben Daten, denselben Merkmalen, nur der Algorithmus wurde geändert.
XGBoost bestätigt, dass die wichtigsten Merkmale ELO-Differenz, spezifische Platz-ELO-Differenz und Gesamt-ELO sind. Das Schach-Bewertungssystem ist die stärkste Vorhersagebasis in den 81 Merkmalen.
Im Vergleich dazu trainierte er ein neuronales Netz mit denselben Daten, das 83% erreichte. Zwar gut, aber hinter XGBoost zurückbleibend. Bei diesem Datensatz gewinnt die Baum-basierte Methode.
Neunter Schritt: Das große Finale – Australian Open 2025
Alle vorherigen Analysen basierten auf Daten bis Dezember 2024.
Das Australian Open 2025 war komplett außerhalb des Trainingsdatensatzes – der perfekte Test: Versteht das Modell die echten Tennisregeln oder nur das historische Muster?

Er gab das komplette Turnier in das Modell ein, ließ es jede Partie vorhersagen.
Ergebnis: 116 Spiele, 99 richtig, nur 17 Fehler. Genauigkeit 85,3%.
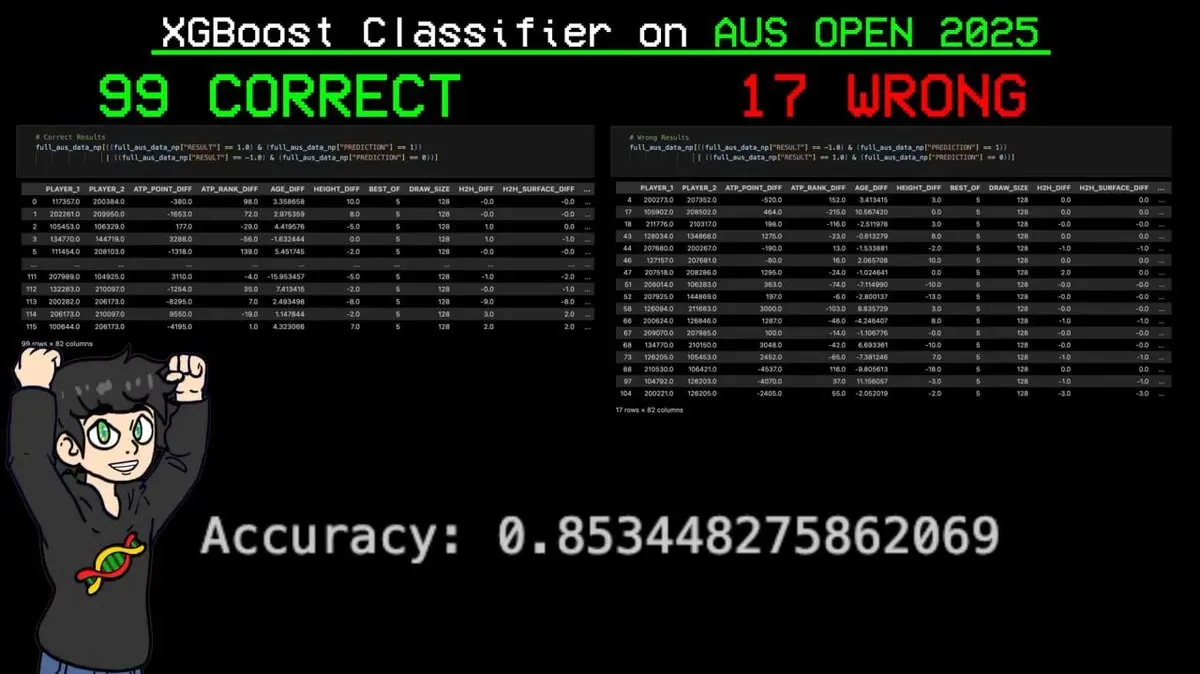
Die wichtigste Vorhersage: Das Modell prognostizierte den Gesamtsieg von Sinner, dem aktuellen Weltranglistenersten, vor Beginn des Turniers.
Noch bevor der erste Ball gespielt wurde, hatte die KI den Grand-Slam-Sieger vorhergesagt.
Schlusswort
Ein Mensch, ein Laptop, keine exklusiven Daten, keine teure Infrastruktur, kein Forschungsteam – und doch entstand ein Profistennis-Vorhersagemodell mit 85% Genauigkeit, das den Grand-Slam-Sieger vor Turnierbeginn richtig vorhersagte.
Die Tennis-Daten sind auf GitHub frei zugänglich und vollständig reproduzierbar.
Wunder zu schaffen war noch nie so greifbar wie heute.
Der wahre Unterschied liegt nicht in Ressourcen, sondern darin, ob du bereit bist, es zu tun.