Consejos básicos:
ChatGPT y otras IA de chat basadas en tecnología de procesamiento de lenguaje natural tienen tres problemas principales de cumplimiento legal que deben resolverse urgentemente a corto plazo:
En primer lugar, cuando se trata de los derechos de propiedad intelectual de las respuestas proporcionadas por chat AI, el principal problema de cumplimiento es si las respuestas producidas por chat AI generan los derechos de propiedad intelectual correspondientes y si se requiere la autorización de los derechos de propiedad intelectual.
En segundo lugar, ¿el proceso de minería de datos y el entrenamiento de la IA de chat en una gran cantidad de texto de procesamiento de lenguaje natural (comúnmente conocido como corpus) necesita obtener los derechos de propiedad intelectual correspondientes?
En tercer lugar, uno de los mecanismos para que ChatGPT y otras IA de chat respondan es obtener un modelo de lenguaje basado en estadísticas mediante el recuento matemáticamente estadístico de una gran cantidad de textos en lenguaje natural existentes, lo que lleva al hecho de que es probable que la IA de chat “diga tonterías graves”, lo que a su vez conduce al riesgo legal de la difusión de información falsa.
En general, en la actualidad, la legislación sobre inteligencia artificial de China aún se encuentra en la etapa previa a la investigación, y no existe un plan legislativo formal o un proyecto de moción relevante, y los departamentos pertinentes son particularmente cautelosos sobre la supervisión del campo de la inteligencia artificial.

1. ChatGPT no es una “tecnología de inteligencia artificial de diferentes épocas”
ChatGPT es esencialmente un producto del desarrollo de la tecnología de procesamiento del lenguaje natural, y sigue siendo esencialmente solo un modelo de lenguaje.
A principios de 2023, la enorme inversión del gigante tecnológico mundial Microsoft ha convertido a ChatGPT en la “corriente superior” en el campo de la tecnología y con éxito fuera del círculo. Con el fuerte aumento del concepto de ChatGPT en el mercado de capitales, muchas empresas tecnológicas nacionales también han comenzado a exponer este campo, mientras que el mercado de capitales está entusiasmado con el concepto de ChatGPT, como trabajadores legales, no podemos evitar evaluar qué riesgos de seguridad legal puede traer ChatGPT en sí mismo y cuál es su camino de cumplimiento legal.
Antes de discutir los riesgos legales y las vías de cumplimiento de ChatGPT, primero debemos examinar la lógica técnica de ChatGPT: ¿ChatGPT le da al interrogador las preguntas que desea, como sugiere la noticia?
A los ojos del equipo de la hermana Sa, ChatGPT parece estar lejos de ser tan “dios” como anunciaban algunas noticias: en una palabra, es solo una integración de tecnologías de procesamiento de lenguaje natural como Transformer y GPT, y sigue siendo esencialmente un modelo de lenguaje basado en redes neuronales, en lugar de un “progreso de IA entre eras”.
Como se mencionó anteriormente, ChatGPT es un producto del desarrollo de la tecnología de procesamiento del lenguaje natural y, en términos de la historia del desarrollo de la tecnología, ha pasado aproximadamente por tres etapas: modelo de lenguaje basado en gramática, modelo de lenguaje basado en estadísticas y modelo de lenguaje basado en redes neuronales En primer lugar, el principio de funcionamiento y los riesgos jurídicos que pueden derivarse de este principio deben aclararse como principio de funcionamiento del modelo de lenguaje basado en estadísticas, predecesor del modelo de lenguaje basado en redes neuronales.
En la etapa del modelo de lenguaje basado en estadísticas, los ingenieros de IA determinan la probabilidad de conexiones sucesivas entre palabras contando una gran cantidad de texto en lenguaje natural, y cuando las personas hacen una pregunta, la IA comienza a analizar qué palabras son altamente probables en el entorno lingüístico donde se componen las palabras constituyentes del problema, y luego empalma estas palabras de alta probabilidad para devolver una respuesta basada en estadísticas. Se puede decir que este principio ha estado presente en el desarrollo de la tecnología de procesamiento del lenguaje natural desde su aparición, e incluso en cierto sentido, la posterior aparición de modelos de lenguaje basados en redes neuronales es también una modificación de los modelos de lenguaje basados en estadísticas.
Para dar un ejemplo fácil de entender, el equipo de la hermana Sa escribió la pregunta “¿Cuáles son las atracciones turísticas de Dalian?” en el cuadro de chat de ChatGPT, como se muestra en la siguiente figura:
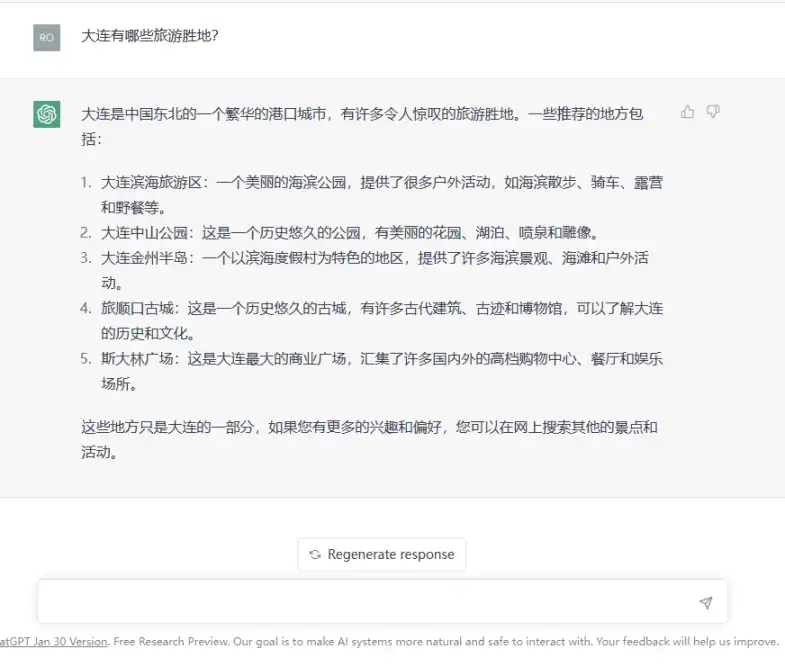
En el primer paso, la IA analizará los morfemas básicos en la pregunta “Dalian, que, turismo y lugares pintorescos”, y luego encontrará el conjunto de texto en lenguaje natural donde se encuentran estos morfemas en el corpus existente, encontrará las colocaciones con la mayor probabilidad de ocurrencia en este conjunto y luego combinará estas colocaciones para formar la respuesta final. Por ejemplo, la IA encontrará que existe la palabra “Zhongshan Park” en el corpus con una alta probabilidad de que aparezcan las tres palabras “Dalian, turismo y resort”, por lo que volverá a “Zhongshan Park”, y la palabra “parque” tiene la mayor probabilidad de colocación con palabras como jardín, lago, fuente, estatua, etc., por lo que devolverá además "Este es un parque histórico con hermosos jardines, lagos, fuentes y estatuas. 」
En otras palabras, todo el proceso se basa en la estadística de probabilidad de la información de texto en lenguaje natural (corpus) que ya existe detrás de la IA, por lo que las respuestas devueltas también son “resultados estadísticos”, lo que lleva al “grave sinsentido” de ChatGPT en muchas preguntas. Como respuesta a la pregunta “¿Cuáles son las atracciones turísticas en Dalian?”, aunque Dalian tiene el Parque Zhongshan, no hay lagos, fuentes y estatuas en el Parque Zhongshan. Dalian tuvo la “Plaza Stalin” en la historia, pero la Plaza Stalin nunca fue una plaza comercial, ni tuvo centros comerciales, restaurantes o lugares de entretenimiento. Aparentemente, la información devuelta por ChatGPT es falsa.

En segundo lugar, ChatGPT es actualmente el escenario de aplicación más adecuado como modelo de lenguaje
Aunque explicamos sin rodeos las desventajas de los modelos de lenguaje basados en estadísticas en la parte anterior, ChatGPT ya es un modelo de lenguaje basado en redes neuronales que mejora en gran medida el modelo de lenguaje basado en estadísticas, y su base técnica Transformer y GPT son la última generación de modelos de lenguaje El modelo se combina para modelar el lenguaje natural de una manera muy profunda, y las frases devueltas a veces son “tonterías”, pero a primera vista siguen pareciendo “respuestas humanas”, por lo que esta tecnología tiene una amplia gama de escenarios de aplicación en escenarios que requieren una interacción masiva humano-ordenador.
Por ahora, hay tres escenarios de este tipo:
En primer lugar, los motores de búsqueda;
En segundo lugar, el mecanismo de interacción persona-computadora en bancos, bufetes de abogados, diversos intermediarios, centros comerciales, hospitales y plataformas de servicios gubernamentales gubernamentales, como el sistema de quejas de clientes, la navegación de orientación y el sistema de consulta de asuntos gubernamentales en los lugares mencionados;
En tercer lugar, el mecanismo de interacción de los coches inteligentes y los hogares inteligentes (como los altavoces inteligentes y las luces inteligentes).
Es probable que los motores de búsqueda que combinan tecnologías de chat de IA como ChatGPT presenten un enfoque tradicional basado en motores de búsqueda + modelos de lenguaje basados en redes neuronales. En la actualidad, los gigantes de las búsquedas tradicionales como Google y Baidu tienen una profunda acumulación de tecnología de modelos de lenguaje basados en redes neuronales, por ejemplo, Google tiene Sparrow y Lamda, que son comparables a ChatGPT.
La aplicación de la tecnología de chat de IA, como ChatGPT, en el sistema de quejas de los clientes, la orientación y navegación de hospitales y centros comerciales, y el sistema de consulta de asuntos gubernamentales de las agencias gubernamentales reducirá en gran medida el costo de los recursos humanos de las unidades relevantes y ahorrará tiempo de comunicación, pero el problema es que las respuestas basadas en estadísticas pueden producir respuestas de contenido completamente incorrectas, y es posible que sea necesario evaluar más a fondo los riesgos de control de riesgos que esto conlleva.
En comparación con los dos escenarios de aplicación anteriores, el riesgo legal de que la aplicación ChatGPT se convierta en el mecanismo de interacción humano-computadora de los dispositivos mencionados anteriormente en los campos de los automóviles inteligentes y los hogares inteligentes es mucho menor, porque el entorno de aplicación en este campo es relativamente privado y el contenido incorrecto retroalimentado por la IA no causará grandes riesgos legales y, al mismo tiempo, dichos escenarios no tienen altos requisitos de precisión de contenido y el modelo de negocio es más maduro.

III. Un estudio preliminar sobre los riesgos legales y la ruta de cumplimiento de ChatGPT
En primer lugar, el panorama regulatorio general de la inteligencia artificial en China
Al igual que muchas tecnologías emergentes, la tecnología de procesamiento del lenguaje natural representada por ChatGPT se enfrenta a un “dilema de Collingridge” Este dilema incluye el dilema de la información, es decir, las consecuencias sociales de una tecnología emergente no se pueden predecir en la etapa inicial de la tecnología, y el llamado dilema de control, es decir, cuando se descubren las consecuencias sociales adversas de una tecnología emergente, la tecnología a menudo se ha convertido en parte de toda la estructura social y económica, de modo que las consecuencias sociales adversas no se pueden controlar de manera efectiva.
En un momento en que el campo de la inteligencia artificial, especialmente la tecnología de procesamiento del lenguaje natural, se encuentra en una etapa de rápido desarrollo, es probable que la tecnología caiga en el llamado “dilema de Collingridge”, y la regulación legal correspondiente no parece haber “seguido el ritmo”. En la actualidad, no existe una legislación nacional sobre la industria de la inteligencia artificial en China, pero ha habido intentos legislativos relevantes a nivel local. En septiembre del año pasado, Shenzhen anunció las “Regulaciones sobre la Promoción de la Industria de la Inteligencia Artificial en la Zona Económica Especial de Shenzhen”, que es una legislación especial para la industria nacional no relacionada con la inteligencia artificial, y luego Shanghai también aprobó las “Regulaciones sobre la Promoción del Desarrollo de la Industria de la Inteligencia Artificial en Shanghai”.
En cuanto a la regulación ética de la inteligencia artificial, el Comité Profesional Nacional para la Gobernanza de la Nueva Generación de Inteligencia Artificial también emitió el “Código de Ética de la Nueva Generación de Inteligencia Artificial” en 2021, proponiendo integrar la ética en todo el ciclo de vida de la investigación y el desarrollo y la aplicación de la inteligencia artificial.
En segundo lugar, el riesgo legal de desinformación provocado por ChatGPT
Cambiando el enfoque de lo macro a lo micro, aparte del panorama regulatorio general de la industria de la IA y la regulación ética de la IA, los problemas prácticos de cumplimiento existentes en la base de los chats de IA como ChatGPT también necesitan atención urgente.
Como se mencionó en la Parte 2 de este artículo, el mecanismo de trabajo de ChatGPT hace posible que sus respuestas sean completamente “tonterías serias”, lo cual es extremadamente engañoso. Por supuesto, las respuestas falsas a preguntas como “¿cuáles son las atracciones turísticas de Dalian?” pueden no tener consecuencias graves, pero si ChatGPT se aplica a los motores de búsqueda, los sistemas de quejas de los clientes y otros campos, la información falsa que responde puede plantear riesgos legales extremadamente graves.
De hecho, ese riesgo legal ya ha surgido, y Galactica, un modelo de lenguaje en el campo de la investigación científica de servicios de Meta que se lanzó casi al mismo tiempo que ChatGPT en noviembre de 2022, se desconectó después de solo 3 días de pruebas debido a las preguntas mixtas de respuestas verdaderas y falsas. Bajo la premisa de que los principios técnicos no se pueden romper en un corto período de tiempo, si ChatGPT y modelos de lenguaje similares se aplican a los motores de búsqueda, los sistemas de quejas de los clientes y otros campos, deben transformarse para su cumplimiento. Cuando se detecta que un usuario puede hacer una pregunta profesional, se le debe indicar que consulte al profesional adecuado en lugar de buscar la respuesta de la IA, y se le debe recordar significativamente que es posible que sea necesario verificar más la autenticidad de las preguntas devueltas por la IA del chat para minimizar los riesgos de cumplimiento correspondientes.
En tercer lugar, los problemas de cumplimiento de la propiedad intelectual provocados por ChatGPT
Al cambiar el enfoque de lo macro a lo micro, además de la autenticidad de los mensajes de respuesta de la IA, los problemas de propiedad intelectual de la IA de chat, especialmente los grandes modelos de lenguaje como ChatGPT, también deberían atraer la atención de los responsables de cumplimiento.
El primer problema de cumplimiento es si la “minería de datos de texto” requiere la correspondiente licencia de propiedad intelectual. Como se señaló anteriormente, ChatGPT se basa en una gran cantidad de textos en lenguaje natural (o bases de datos de voz), ChatGPT necesita extraer y entrenar los datos en el corpus, y ChatGPT necesita copiar el contenido del corpus en su propia base de datos, y el comportamiento correspondiente a menudo se denomina “minería de datos de texto” en el campo del procesamiento del lenguaje natural. Partiendo de la premisa de que los datos textuales correspondientes pueden constituir una obra, sigue existiendo controversia en cuanto a si la minería de datos textuales infringe el derecho de reproducción.
En el ámbito del derecho comparado, tanto Japón como la Unión Europea han ampliado el alcance del uso leal en su legislación sobre derechos de autor, añadiendo la “minería de datos de texto” en la IA como un nuevo caso de uso leal. Aunque algunos académicos abogaron por cambiar el sistema de uso justo de China de “cerrado” a “abierto” en el proceso de revisión de la ley de derechos de autor de China en 2020, esta propuesta no se adoptó finalmente y, en la actualidad, la ley de derechos de autor de China aún mantiene las disposiciones cerradas del sistema de uso justo, y solo las trece circunstancias estipuladas en el artículo 24 de la Ley de Derechos de Autor pueden reconocerse como uso justo, en otras palabras, en la actualidad, la ley de derechos de autor de China no incluye la “minería de datos de texto” en la IA Incluida en el ámbito de aplicación razonable, la minería de datos de texto sigue requiriendo la correspondiente autorización de propiedad intelectual en China.
En cuanto a la cuestión de si las obras generadas por IA son originales, el equipo de Sister Sa cree que los criterios de juicio no deberían ser diferentes de los estándares de juicio existentes, en otras palabras, ya sea que una respuesta sea completada por IA o por un humano, debe juzgarse de acuerdo con los estándares de originalidad existentes. Obviamente, según las leyes de propiedad intelectual de la mayoría de los países, incluida China, el autor de una obra solo puede ser una persona física, y la IA no puede convertirse en el autor de una obra.
Por último, si ChatGPT empalma una obra de terceros en su respuesta, ¿cómo deben gestionarse sus derechos de propiedad intelectual? El equipo de la hermana Sa cree que si la respuesta de ChatGPT empalma una obra protegida por derechos de autor en el corpus (aunque es menos probable que esto ocurra de acuerdo con el principio de funcionamiento de ChatGPT), entonces, de acuerdo con la ley de derechos de autor actual de China, a menos que constituya un uso justo, debe copiarse sin la autorización del propietario de los derechos de autor.

