**Source : **Communauté ouverte AIGC
Le 14 septembre, la célèbre plateforme open source Stability AI a publié le produit d’IA générative audio Stable Audio sur son site officiel. (Adresse d’utilisation gratuite :
Les utilisateurs peuvent générer directement plus de 20 types de musique de fond telles que le rock, le jazz, l’électronique, le hip-hop, le heavy metal, le folk, la pop, le punk et la country via des invites textuelles.
Par exemple, saisissez des mots-clés tels que disco, boîte à rythmes, synthétiseur, basse, piano, guitare, joyeux, 115 BPM, etc. pour générer une musique de fond.
Actuellement, Stable Audio propose deux versions gratuites et payantes : la version gratuite, qui peut générer 20 morceaux de musique par mois, d’une durée maximale de 45 secondes, et ne peut pas être utilisée à des fins commerciales ; la version payante, qui coûte 11,99 $ par mois ( environ 87 yuans), peut générer 500 morceaux de musique. La musique, d’une durée maximale de 90 secondes, peut être utilisée commercialement.
Si vous ne souhaitez pas payer, vous pouvez créer quelques comptes supplémentaires et combiner la musique générée via AU (un éditeur audio) ou PR pour obtenir le même effet.
Brève introduction à Stable Audio
Au cours des dernières années, les modèles de diffusion ont connu un développement rapide dans les domaines de l’image, de la vidéo, de l’audio et dans d’autres domaines, ce qui peut améliorer considérablement l’efficacité de la formation et de l’inférence. Mais il existe un problème avec les modèles de diffusion dans le domaine audio, qui produisent généralement du contenu de taille fixe.
Par exemple, un modèle de diffusion audio peut être entraîné sur des clips audio de 30 secondes et générer uniquement des clips audio de 30 secondes. Afin de briser ce goulot d’étranglement technique, Stable Audio utilise un modèle plus avancé.
Il s’agit d’un modèle de diffusion audio latente basé sur des métadonnées de texte et des ajustements de la durée et de l’heure de début du fichier audio, permettant de contrôler le contenu et la durée de l’audio généré. Cette condition de temps supplémentaire permet à l’utilisateur de générer de l’audio d’une durée spécifiée.
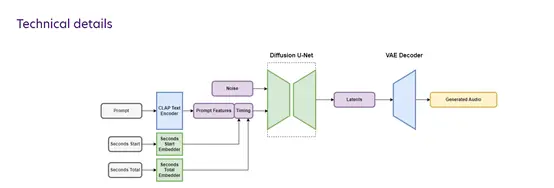 L’utilisation d’une représentation latente fortement sous-échantillonnée de l’audio peut obtenir une efficacité d’inférence plus rapide par rapport à l’audio d’origine. Avec le dernier modèle audio stable, Stable Audio peut restituer 95 secondes d’audio stéréo à l’aide du GPU NVIDIA A100 en moins d’une seconde, avec un taux d’échantillonnage de 44,1 kHz.
L’utilisation d’une représentation latente fortement sous-échantillonnée de l’audio peut obtenir une efficacité d’inférence plus rapide par rapport à l’audio d’origine. Avec le dernier modèle audio stable, Stable Audio peut restituer 95 secondes d’audio stéréo à l’aide du GPU NVIDIA A100 en moins d’une seconde, avec un taux d’échantillonnage de 44,1 kHz.
En termes de données d’entraînement, Stable Audio utilise un ensemble de données composé de plus de 800 000 fichiers audio, comprenant de la musique, des effets sonores et divers instruments de musique.
L’ensemble de données totalise plus de 19 500 heures d’audio et coopère également avec le fournisseur de services musicaux AudioSparx, afin que la musique générée puisse être utilisée à des fins de commercialisation.
Modèle de diffusion latente
Les modèles de diffusion latente utilisés par Stable Audio sont un modèle génératif basé sur la diffusion principalement utilisé dans l’espace de codage latent des auto-encodeurs pré-entraînés. Il s’agit d’une approche qui combine auto-encodeurs et modèles de diffusion.
Les auto-encodeurs sont d’abord utilisés pour apprendre des représentations latentes de basse dimension des données d’entrée (telles que des images ou de l’audio). Cette représentation latente capture des caractéristiques importantes des données d’entrée et peut être utilisée pour reconstruire les données d’origine.
Les modèles de diffusion sont ensuite entraînés dans cet espace latent, modifiant progressivement les variables latentes pour générer de nouvelles données.
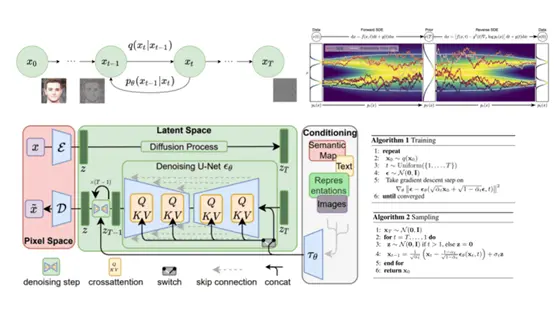 Le principal avantage de cette approche est qu’elle peut améliorer considérablement la vitesse de formation et d’inférence des modèles de diffusion. Étant donné que le processus de diffusion se produit dans un espace latent relativement petit plutôt que dans l’espace de données d’origine, de nouvelles données peuvent être générées plus efficacement.
Le principal avantage de cette approche est qu’elle peut améliorer considérablement la vitesse de formation et d’inférence des modèles de diffusion. Étant donné que le processus de diffusion se produit dans un espace latent relativement petit plutôt que dans l’espace de données d’origine, de nouvelles données peuvent être générées plus efficacement.
De plus, en opérant dans l’espace latent, de tels modèles peuvent également permettre un meilleur contrôle des données générées. Par exemple, les variables latentes peuvent être manipulées pour modifier certaines caractéristiques des données générées, ou le processus de génération de données peut être guidé en imposant des contraintes sur les variables latentes.
Utilisation audio stable et affichage du boîtier
“AIGC Open Community” a essayé la version gratuite de Stable Audio. La méthode d’utilisation est similaire à celle de ChatGPT. Entrez simplement l’invite de texte. Le contenu de l’invite comprend quatre catégories : détails, mentalité, instruments et rythmes.
Il convient de noter que si vous souhaitez que la musique générée soit plus délicate, rythmée et rythmée, le texte saisi doit également être plus détaillé. En d’autres termes, plus vous saisissez de texte, meilleur sera l’effet généré.
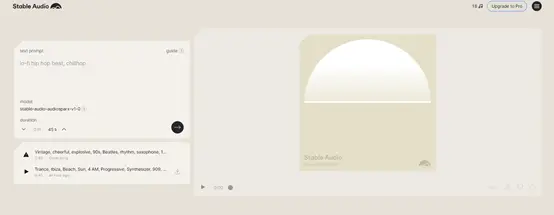 Interface utilisateur audio stable
Interface utilisateur audio stable
Ce qui suit est une démonstration de cas de génération audio.
Transe, île, plage, soleil, 4h du matin, progressif, synthé, 909, accords dramatiques, refrain, optimiste, nostalgique, dynamique.
Câlin doux, confort, synthétiseur grave, miroitement, vent et feuilles, ambiant, paisible, relaxant, eau.
Pop électronique, gros synthé réverbéré, boîte à rythmes, atmosphérique, maussade, nostalgique, cool, pop instrumental, 100 BPM.
3/4, 3 temps, guitare, batterie, brillant, joyeux, applaudissements
Le matériel de cet article provient du site officiel de Stability AI. En cas d’infraction, veuillez nous contacter pour la supprimer.
FIN
