Source: Qubits
Réfléchir davantage aux étapes avant que ChatGPT ne donne une réponse peut améliorer la précision.
Alors, pouvez-vous ignorer l’invite et intérioriser directement cette capacité dans le grand modèle ?
La nouvelle étude de CMU et de l’équipe de Google ajoute un jeton de pause lors de l’entraînement de grands modèles pour y parvenir.
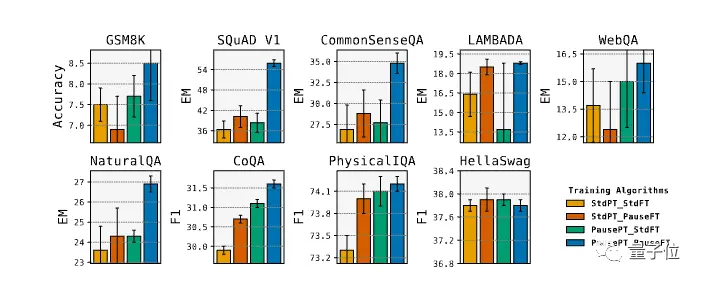
 Dans l’expérience, les scores de 8 évaluations se sont améliorés, parmi lesquels le score EM de SQuAD a augmenté de 18 %, le CommonSenseQA a augmenté de 8 % et la tâche d’inférence dans GSM8k a également augmenté de 1 %.
Dans l’expérience, les scores de 8 évaluations se sont améliorés, parmi lesquels le score EM de SQuAD a augmenté de 18 %, le CommonSenseQA a augmenté de 8 % et la tâche d’inférence dans GSM8k a également augmenté de 1 %.
 Le chercheur Jack Hack a déclaré qu’il avait émis une hypothèse similaire il n’y a pas si longtemps et qu’il était heureux de la voir testée.
Le chercheur Jack Hack a déclaré qu’il avait émis une hypothèse similaire il n’y a pas si longtemps et qu’il était heureux de la voir testée.
 L’ingénieur de Nvidia, Aaron Erickson, a déclaré que c’était une vérité d’ajouter « uh-huh-ah » lorsque l’on parle à des humains ?
L’ingénieur de Nvidia, Aaron Erickson, a déclaré que c’était une vérité d’ajouter « uh-huh-ah » lorsque l’on parle à des humains ?
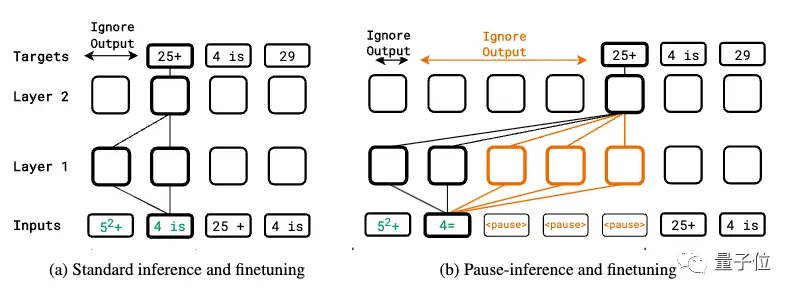
Le réglage fin du pré-entraînement est ajouté au jeton de pause
Toute l’étude est basée sur une idée simple :
Ajoutez une série (jeton de pause) à la séquence d’entrée, ce qui retarde la sortie du jeton suivant du modèle.
Cela peut donner au modèle un temps de calcul supplémentaire pour traiter des entrées plus complexes.
 Les auteurs l’introduisent non seulement lorsque la tâche en aval est affinée, mais l’insèrent également de manière aléatoire dans la séquence pendant le pré-entraînement, ce qui permet au modèle d’apprendre à tirer parti de ce délai de calcul dans les deux étapes.
Les auteurs l’introduisent non seulement lorsque la tâche en aval est affinée, mais l’insèrent également de manière aléatoire dans la séquence pendant le pré-entraînement, ce qui permet au modèle d’apprendre à tirer parti de ce délai de calcul dans les deux étapes.
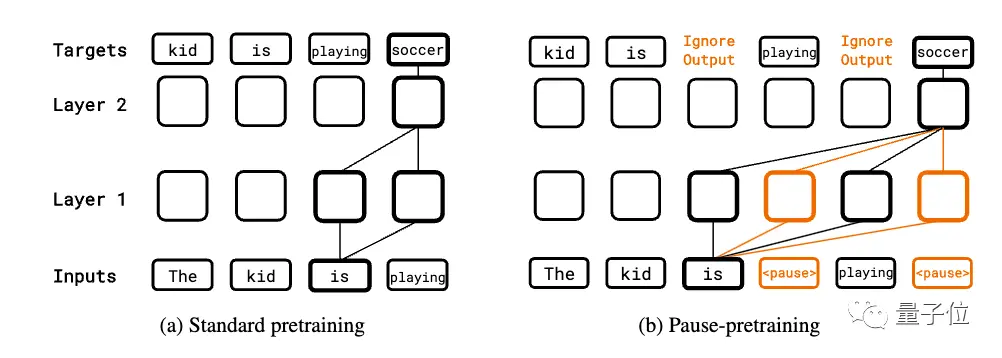 Dans la phase de pré-entraînement, un certain pourcentage de jetons de pause sont insérés de manière aléatoire dans le corpus dans la séquence d’entrée pour le pré-entraînement autorégressif standard. Cependant, la prédiction du jeton suspendu est ignorée lors du calcul de la perte.
Dans la phase de pré-entraînement, un certain pourcentage de jetons de pause sont insérés de manière aléatoire dans le corpus dans la séquence d’entrée pour le pré-entraînement autorégressif standard. Cependant, la prédiction du jeton suspendu est ignorée lors du calcul de la perte.
Lorsque la tâche en aval est affinée, un certain nombre de jetons de pause sont ajoutés à l’entrée, puis une prédiction autorégressive est effectuée sur la séquence cible, tout en affinant les paramètres du modèle.
La phase d’inférence ajoute également le même nombre de jetons de pause, mais ignore la sortie du modèle jusqu’au dernier jeton de pause, puis commence à extraire la réponse.
L’expérience utilise le modèle standard de décodeur pur Transformer, qui est divisé en deux versions : paramètre 130M et paramètre 1B.
Le jeton de pause n’ajoute que 1024 paramètres, ce qui correspond à sa propre taille d’incorporation.
Des expériences sur 9 tâches différentes ont montré que l’effet de l’introduction de jetons de pause uniquement pendant la phase de réglage fin n’était pas évident, et que certaines tâches ne s’amélioraient pas.
Mais si vous utilisez des jetons de pause à la fois dans les phases de pré-entraînement et de mise au point, vous obtenez une amélioration significative sur la plupart des tâches.
L’article explore également des hyperparamètres clés tels que le nombre et l’emplacement des jetons suspendus. Il a été constaté qu’il existe généralement une quantité optimale pour différents modèles.
Enfin, les auteurs soulignent également que ce travail présente également un certain nombre de limites.
- Étant donné que le jeton de suspension augmente la quantité de calcul du modèle, il reste à discuter de la question de savoir s’il est juste de comparer avec d’autres méthodes
- La nouvelle méthode doit être ré-entraînée, et il est encore difficile de l’appliquer dans la pratique
- Il y a encore un manque de compréhension approfondie des mécanismes de fonctionnement spécifiques
- Si le nombre de jetons de pause est égal à 0 pendant l’inférence, le modèle fonctionne toujours mal
Le PDG du moteur de recherche You.com déclaré que la prochaine étape consiste à essayer toutes les techniques permettant d’améliorer les performances cognitives humaines sur de grands modèles.
 Maintenant, il y a « penser étape par étape » et « respirer profondément ».
Maintenant, il y a « penser étape par étape » et « respirer profondément ».
Peut-être que le prochain article à succès est d’apprendre aux grands mannequins à dormir avec des problèmes, ou plus outrageusement à manger sainement et à faire de l’exercice.
Adresse papier :
Liens de référence :
[1]
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.
