一時停止トークンを使用して大規模なモデルを再トレーニングすると、AIは二度考えることを学習します
巴比特_
ソース: 量子ビット
ChatGPTが答えを出す前にステップについてもっと考えると、精度を向上させることができます。
では、プロンプトをスキップして、この機能を大きなモデルに直接内在化できますか?
CMUとGoogleチームによる新しい研究では、これを達成するために大規模なモデルをトレーニングするときに一時停止トークンが追加されます。
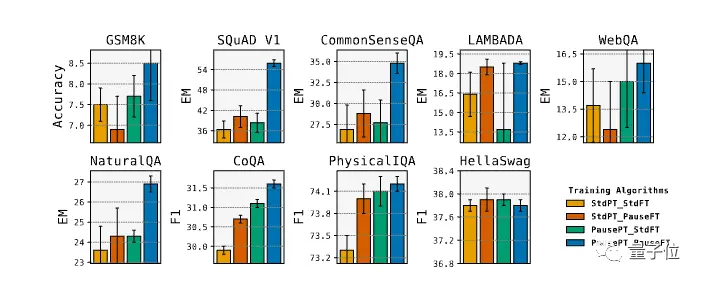
 実験では、8つの評価のスコアが向上し、そのうちSQuADのEMスコアは18%増加し、CommonSenseQAは8%増加し、GSM8kの推論タスクも1%増加しました。
実験では、8つの評価のスコアが向上し、そのうちSQuADのEMスコアは18%増加し、CommonSenseQAは8%増加し、GSM8kの推論タスクも1%増加しました。
 研究者のジャック・ハックは、少し前に同様の仮説を思いついたと言い、それがテストされたのを見てうれしいと言いました。
研究者のジャック・ハックは、少し前に同様の仮説を思いついたと言い、それがテストされたのを見てうれしいと言いました。
 Nvidiaのエンジニアであるアーロンエリクソンは、人間と話すときに「ええと」を追加するのは真実だと言いました。
Nvidiaのエンジニアであるアーロンエリクソンは、人間と話すときに「ええと」を追加するのは真実だと言いました。
事前トレーニングの微調整が一時停止トークンに追加されました
全体の研究は単純な考えに基づいています:
入力シーケンスに系列 (一時停止トークン) を追加し、モデルが次のトークンを出力するのを遅らせます。
これにより、より複雑な入力を処理するための計算時間をモデルに追加できます。
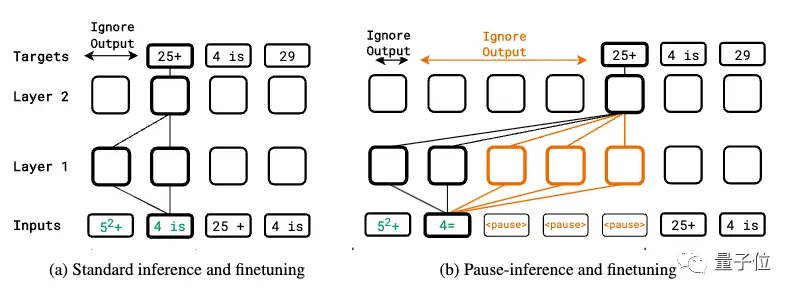 著者らは、下流のタスクが微調整されたときにそれを導入するだけでなく、事前トレーニング中にランダムにシーケンスに挿入して、モデルが両方の段階でこの計算遅延を利用する方法を学習できるようにします。
著者らは、下流のタスクが微調整されたときにそれを導入するだけでなく、事前トレーニング中にランダムにシーケンスに挿入して、モデルが両方の段階でこの計算遅延を利用する方法を学習できるようにします。
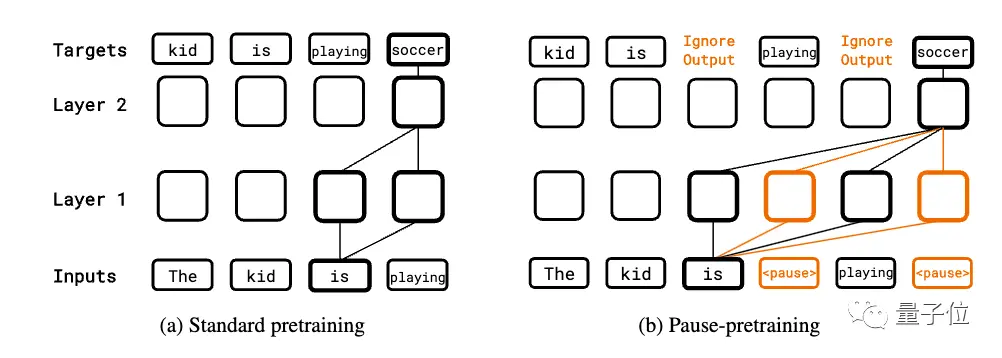 事前学習段階では、一定の割合の一時停止トークンが、標準的な自己回帰事前学習のためにコーパスの入力シーケンスにランダムに挿入されます。 ただし、中断されたトークンの予測は、損失の計算時にスキップされます。
事前学習段階では、一定の割合の一時停止トークンが、標準的な自己回帰事前学習のためにコーパスの入力シーケンスにランダムに挿入されます。 ただし、中断されたトークンの予測は、損失の計算時にスキップされます。
下流タスクが微調整されると、一定数の一時停止トークンが入力に追加され、モデルパラメータを微調整しながら、ターゲットシーケンスに対して自己回帰予測が行われます。
推論フェーズでも同じ数の一時停止トークンが追加されますが、最後の一時停止トークンまでモデル出力は無視され、回答の抽出が開始されます。
実験では、130Mパラメータと1Bパラメータの2つのバージョンに分かれている標準のトランスフォーマーピュアデコーダーモデルを使用します。
pause トークンは、独自の埋め込みサイズである 1024 個のパラメーターのみを追加します。
9つの異なるタスクの実験では、微調整フェーズ中にのみ一時停止トークンを導入した場合の効果は明らかではなく、一部のタスクは改善されなかったことが示されました。
ただし、事前トレーニングフェーズと微調整フェーズの両方で一時停止トークンを使用すると、ほとんどのタスクで大幅な改善が得られます。
このホワイトペーパーでは、一時停止されたトークンの数や場所などの主要なハイパーパラメーターについても説明します。 通常、さまざまなモデルに最適な量があることがわかりました。
最後に、著者はまた、この作業にもいくつかの制限があることを指摘しています。
*サスペンショントークンはモデルの計算量を増やすため、他の方法と比較して公平であるかどうかはまだ議論されていません *新しい方法は事前に再トレーニングする必要があり、実際に適用することはまだ困難です *特定の作業メカニズムの深い理解はまだ不足しています
- 推論中に一時停止トークンの数が 0 の場合、モデルのパフォーマンスは低下します
検索エンジン You.com のCEOは、次のステップは大規模なモデルで人間の認知能力を向上させるためのすべてのテクニックを試すことであると述べましたか?
 今、「一歩一歩考える」と「深呼吸する」があります。
今、「一歩一歩考える」と「深呼吸する」があります。
たぶん、次の大ヒット論文は、大きなモデルに問題を抱えて眠ること、またはより法外に健康的な食事と運動を教えることです。
論文住所:
参考リンク:
[1]
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし