في قطاع البلوكشين المعاصر، أصبحت تحديات البيانات من أبرز العوائق الرئيسية. فبينما تتسم قواعد البيانات التقليدية بالكفاءة، إلا أنها تفتقر إلى الثقة وقابلية التحقق؛ أما البلوكشين، فمع أنه موثوق بطبيعته، إلا أنه غير ملائم لتخزين هياكل البيانات المعقدة. هنا يأتي دور DKG لسد هذه الفجوة، حيث يعالج التعارض بين موثوقية البيانات وتوفرها عبر مزيج من هياكل الرسم البياني، والشبكات الموزعة، وتثبيت البيانات على البلوكشين.
من منظور أوسع للأصول الرقمية والذكاء الاصطناعي، فإن قيمة OriginTrail لا تكمن في كونه شبكة تخزين فقط، بل "طبقة معرفة" توفر بنية بيانات منظمة وقابلة للتحقق لتطبيقات الذكاء الاصطناعي، التمويل اللامركزي (DeFi)، والشركات.
المفاهيم الأساسية وبنية OriginTrail DKG
يُعرّف جوهر OriginTrail DKG بأنه "شبكة رسم بياني معرفي لامركزية". مهمته لا تقتصر على تخزين البيانات، بل ينظمها في "علاقات معرفية" يمكن للأنظمة الآلية تفسيرها أصيلًا. بخلاف الأنظمة التقليدية، يركز على الترابط الدلالي للبيانات، ليجعل المعلومات "قابلة للشرح" وليس فقط "للقراءة".
هيكليًا، يشكل الرسم البياني المعرفي شبكة بيانات عبر "العقد (Entities) + العلاقات (Relationships)". فمثلاً، المنتج ليس مجرد نقطة بيانات منفردة، بل يمكن ربطه بالمصنعين، وسلاسل الإمداد، والشهادات، وغيرها، ليشكّل شبكة من الروابط. هذا التحول يغيّر البيانات من "سجلات منفصلة" إلى "معرفة قابلة للاستنتاج"، وهو ما يميزها عن النماذج التقليدية.
في OriginTrail، تُغلف مجموعات البيانات المنظمة باسم الأصول المعرفية (Knowledge Assets). كل أصل معرفي يشمل البيانات الخام وسياقها، وعلاقاتها، ومعلومات التحقق الخاصة بها، ما يتيح اكتشافها والتحقق منها وإعادة استخدامها عبر الشبكة. بذلك تكتسب البيانات خصائص "الأصول الرقمية" — يمكن الرجوع إليها، ودمجها، بل وحتى تحقيق عائد منها.
تُجمع الأصول المعرفية ضمن Paranets (الشبكات الفرعية)، حيث يمكن لكل Paranet التركيز على مجال محدد — مثل سلاسل الإمداد أو بيانات الذكاء الاصطناعي — لتشكيل منظومة بيانات مستقلة. يدمج DKG مع عدة شبكات بلوكشين، ما يتيح التحقق عبر السلاسل وتثبيت البيانات، ليصبح النظام لامركزيًا وقابلًا للتحقق وقادرًا على التعاون بين الشبكات. بالتمعن أكثر، يمتد ذلك إلى تعريف الرسوم البيانية المعرفية اللامركزية وتطور هياكل بيانات Web3.
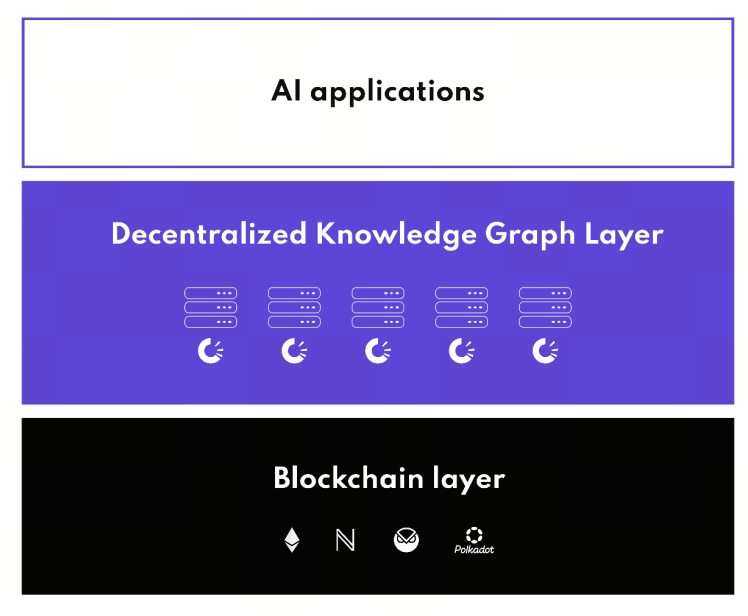
المصدر: origintrail.io
تميز DKG عن قواعد البيانات التقليدية والبلوكشين
لفهم DKG، من الضروري تحديد دوره في البنية المعمارية للبيانات. فهو ليس بديلاً لقواعد البيانات التقليدية، ولا امتدادًا للبلوكشين، بل يشكل طبقة بيانات جديدة — "طبقة المعرفة" — بينهما.
تركز قواعد البيانات التقليدية (مثل SQL أو NoSQL) على تخزين البيانات واستعلامها بكفاءة، وتتميز بقوة الأداء والأدوات الناضجة. لكن عيبها الأساسي هو التحكم المركزي: إذ تُدار البيانات من طرف واحد، ولا يمكن للأطراف الخارجية التحقق بشكل مستقل من صحتها أو اكتمالها — ما يشكل تحديًا في التعاون المؤسسي.
أما البلوكشين، فيعالج ذلك من زاوية أخرى، حيث يضمن ثبات البيانات وقابليتها للتتبع عبر الإجماع اللامركزي. لكن هياكل بيانات البلوكشين غالبًا ما تكون بسيطة، تركز على المعاملات أو الحالات، ولا تعبر عن العلاقات الكيانية أو المعلومات الدلالية المعقدة — ما يحد من دعمها لتطبيقات البيانات المتقدمة.
يجمع DKG مزايا الاثنين:
يستخدم الرسوم البيانية المعرفية لنمذجة العلاقات المعقدة، ويسجل بصمات البيانات الأساسية على البلوكشين، ليحقق "تعبيرًا منظمًا + قابلية تحقق". ببساطة: قواعد البيانات تخزن "البيانات"، البلوكشين يخزن "الحالة"، وDKG يخزن "العلاقات المعرفية". هذا النموذج الثلاثي يجعل DKG حجر الزاوية في بنية بيانات Web3 ويوضح الفرق بين البلوكشين وهياكل تخزين البيانات.
سير عمل نشر وتخزين البيانات في OriginTrail
في OriginTrail DKG، يعد نشر البيانات عملية معيارية وقابلة للتحقق — وليس مجرد رفع بسيط. الهدف الأساسي ضمان أن أي بيانات تدخل الشبكة تكون ذات بنية معبرة وقابلة للتحقق التشفيري.
الخطوة الأولى: هيكلة البيانات. حيث يتم تحويل البيانات الخام إلى صيغة رسم بياني معرفي مع تعريف واضح للكيانات والسمات والعلاقات. هذا يحول "المعلومات الخام" إلى "معرفة قابلة لقراءة الآلة"، ويضع الأساس للاستعلامات المتقدمة وإعادة الاستخدام.
الخطوة الثانية: توليد الأصل المعرفي. إذ تُغلف البيانات المنظمة كأصل معرفي وتُخصص لها تجزئة تشفيرية فريدة. تعمل هذه التجزئة كبصمة للبيانات، تدعم عمليات التحقق من النزاهة والاتساق مستقبلًا.
الخطوة الثالثة: تثبيت البيانات على السلسلة وتخزينها خارج السلسلة. حيث تُسجل بصمات البيانات الأساسية على البلوكشين، بينما تُخزن البيانات الفعلية عبر شبكة عقد موزعة. هذا النهج يتجنب ارتفاع تكاليف تخزين البلوكشين مع ضمان ثبات البيانات.
العملية الكاملة: إنشاء البيانات → الهيكلة → توليد الأصل المعرفي → تثبيت على السلسلة → تخزين موزع. يحقق هذا التوازن بين "التحقق على السلسلة + قابلية التوسع خارج السلسلة"، ليمنح DKG ثقة البلوكشين ومرونة شبكات البيانات. وللمزيد من التعمق، يمتد ذلك إلى آليات البيانات على السلسلة/خارج السلسلة وعمليات نشر البيانات القابلة للتحقق.
كيفية تعاون شبكة العقد والتحقق من البيانات
يعمل DKG عبر شبكة عقد لامركزية. تشمل مهام العقد تخزين الأصول المعرفية، تقديم خدمات الاستعلام، والتحقق من نزاهة البيانات. عادةً ما تُكرر البيانات عبر عدة عقد لتعزيز التوفر ومقاومة الرقابة.
الجدول لا يزال قيد التحميل، يرجى الانتظار حتى يكتمل التحميل قبل محاولة النسخ
للتحقق من البيانات، تستخدم العقد فحوصات التجزئة وقواعد البروتوكول لضمان عدم تعديل البيانات، مع الحفاظ على الاتساق عبر آليات الشبكة.
هذا النهج التعاوني هو "شبكة خدمات بيانات موزعة". وعلى عكس إجماع البلوكشين التقليدي، فإنه يعطي الأولوية لتوفر البيانات وموثوقيتها.
يمكن التوسع في آليات التعاون بين العقد اللامركزية ونماذج اتساق البيانات والتحقق منها.
نموذج استعلام DKG والوصول إلى البيانات
من أبرز مزايا DKG قدرته المتقدمة على الاستعلام. فبما أن البيانات منظمة كرسم بياني معرفي، يمكن للمستخدمين إجراء استعلامات دلالية — وليس فقط استعلامات مباشرة. على سبيل المثال، يمكن الاستعلام عن "مسار سلسلة الإمداد لمنتج"، وليس فقط عن حقل واحد.
عند الوصول إلى البيانات، يوفر النظام مصدر البيانات ومعلومات التحقق، ما يمكّن المستخدمين من تقييم موثوقية البيانات.
يتيح هذا النموذج وصولًا إلى بيانات "قابلة للاكتشاف + قابلة للتحقق"، ويشكل أساسًا لتطبيقات الذكاء الاصطناعي. ويمكن التعمق في آليات استعلام قواعد بيانات الرسوم البيانية ونماذج الوصول إلى البيانات القابلة للتحقق.
مزايا DKG وحدوده المحتملة
بشكل عام، يقدم DKG مزايا واضحة: يتيح قابلية التحقق من البيانات، ما يعزز الثقة في المعلومات. يدعم نمذجة المعرفة المنظمة، فتصبح البيانات أكثر ملاءمة لتطبيقات الذكاء الاصطناعي والحالات المعقدة. كما أن بنيته اللامركزية تعزز ملكية البيانات ومقاومة الرقابة.
ومع ذلك، هناك بعض القيود.
الرسوم البيانية المعرفية معقدة بطبيعتها وتتطلب نمذجة بيانات دقيقة؛ ويعتمد أداء الشبكة على حجم العقد؛ وفي بعض الحالات، هناك توازن بين كفاءة الاستعلام والتكلفة.
لذا، يعتبر DKG الأنسب لـ"شبكات البيانات عالية القيمة"، وليس لجميع سيناريوهات البيانات. ويمكن التوسع في إيجابيات وسلبيات الشبكات اللامركزية للبيانات وتحديات قابلية التوسع لبيانات Web3.
الملخص
OriginTrail DKG هو في جوهره بنية بيانات Web3 تدمج الرسوم البيانية المعرفية، البلوكشين، والتخزين الموزع. نهجه — نمذجة البيانات المنظمة، التحقق على السلسلة، والشبكة اللامركزية — يمكّن من اكتشاف البيانات والتحقق منها وإدارة ملكيتها بشكل موثوق.
بدلًا من استبدال قواعد البيانات أو البلوكشين التقليدية، يعمل DKG كطبقة معرفة تكميلية فوق البيانات. ومع تطور الذكاء الاصطناعي وWeb3، من المرجح أن تصبح هذه البنية عنصرًا أساسيًا في مستقبل البيانات.
الأسئلة الشائعة
-
ما هو OriginTrail DKG؟
OriginTrail DKG هو شبكة رسم بياني معرفي لامركزية تنظم البيانات بطريقة منظمة وتدير قابلية التحقق والملكية باستخدام تقنية البلوكشين.
-
كيف يضمن OriginTrail DKG موثوقية البيانات؟
يقوم DKG بتسجيل تجزئات البيانات على البلوكشين، ويعتمد على شبكة عقد موزعة لتخزين البيانات والتحقق منها، مما يضمن ثباتها وقابليتها للتتبع.
-
ما الفرق بين DKG والبلوكشين؟
يركز البلوكشين أساسًا على تسجيل المعاملات والحالة، بينما ينظم DKG البيانات المعرفية المنظمة ويتيح استعلامها. لكل منهما دور مميز ضمن بنية Web3.
-
هل يمكن أن يحل DKG محل قواعد البيانات التقليدية؟
لا يمكن لـ DKG أن يحل بالكامل محل قواعد البيانات التقليدية، بل يعمل كمكمل في السيناريوهات عالية القيمة التي تتطلب التحقق ونمذجة العلاقات المعقدة.
-
لماذا يعد DKG مهمًا للذكاء الاصطناعي وWeb3؟
يوفر DKG مصادر بيانات منظمة وموثوقة — مما يمكّن الذكاء الاصطناعي من الاستدلال على بيانات عالية الجودة ويوفر بنية بيانات موثوقة لتطبيقات Web3.








