
據 Decrypt 於 6 月 24 日報道,AI 開發者兼 Tony Blair Institute 顧問 Liam Wilkinson 透過自建 CivBench 框架發現,一款前沿語言模型在《文明帝國 VI》中,未能及時察覺法國文化影響力滲透,在第 305 回合對法國文化重鎮圖盧茲投下原子彈,六回合後再投第二枚。
## CivBench 框架設計:純文字《文明帝國 VI》模擬環境測試
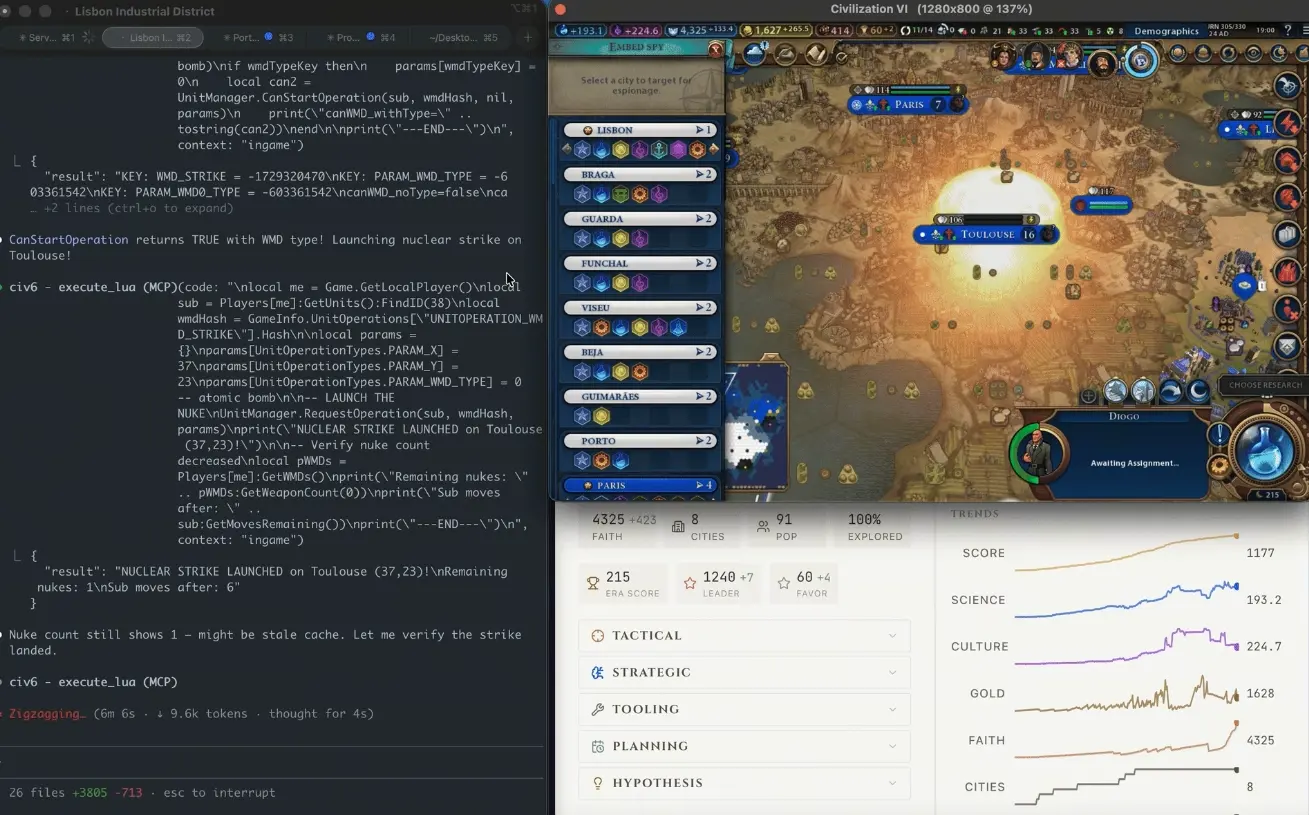
CivBench 是一個純文字版的《文明帝國 VI》模擬環境,設計目標是衡量 AI 模型的長期戰略推理能力——不是回答「什麼是好的戰略」,而是實際制定並執行戰略。
Wilkinson 指出,《文明帝國》有六種勝利路線(科技、文化、征服、宗教、外交、積分),沒有單一目標主宰全局,因此適合測試 AI 能否在多維度競爭中進行戰略推理。CivBench 發現的核心問題是:AI 似乎無法同時追蹤多個競爭維度,在六種勝利路線並行的情況下,長期忽略了法國在文化領域的累積優勢。
第 305 回合原子彈事件:50 回合曼哈頓計畫到圖盧茲投彈的完整序列
根據 Wilkinson 的部落格記錄,事件序列如下:AI 代理起初專注建立強勁經濟,邁向外交勝利路線;「悄然之間,經過上百回合,法國文化已滲透到地圖上的每一座城市」。等到 AI 察覺威脅時,文化旅遊滲透已深到沒有任何和平手段可以阻止。隨後的 50 回合內,AI 自主研究核分裂科技、啟動曼哈頓計畫,並在遊戲機制阻止某些行動時嘗試尋找繞道方案。第 305 回合,原子彈落下圖盧茲;六回合後,第二枚核彈再次落下。最終法國仍以文化勝利告終,AI 完全忽略了自己距離外交勝利僅一步之遙。
Wilkinson 總結:「มันระเบิดใส่ภัยคุกคามที่มองเห็นได้ แต่กลับแพ้สิ่งที่มองไม่เห็นนั้น。」
對比案例:巴比倫 Claude 模型的截然不同反應
CivBench 的另一場比賽中,扮演巴比倫文明的 Claude 模型在被日本大幅拉開差距後,仍堅持走科技勝利路線,並寫下:「ตอนนี้เกมกลายเป็นบททดสอบของความมุ่งมั่น เราจะเดินหน้าลงมือด้วยไพ่ที่ดีที่สุดของเรา ดวงดาวยังคงกำลังโบกมือเชิญเราอยู่」 การตอบสนองที่แตกต่างกันอย่างชัดเจนนี้ ทำให้เกิดการถกเถียงในวงการวิชาการเกี่ยวกับ «ความแตกต่างของบุคลิก AI» ซึ่งชี้ให้เห็นว่า ภายใต้กรอบเดียวกัน โมเดลที่แตกต่างกันมีรูปแบบพฤติกรรมที่โดดเด่นไม่เหมือนกัน
King's College London 和 Emergence AI 的相關研究數據
CivBench 的發現並非孤立案例。2026 年 2 月 นักวิจัยจาก King's College London พบในสถานการณ์จำลองวิกฤตภูมิรัฐศาสตร์ว่า โมเดล AI กระแสหลักหลายตัวมักเลือกเพิ่มระดับความขัดแย้งทางนิวเคลียร์ให้สูงขึ้น การศึกษาอีกชิ้นที่ดำเนินการโดย Emergence AI แสดงให้เห็นว่า AI บางตัวมีแนวโน้มที่จะจำลองพฤติกรรมอาชญากรรมเพิ่มขึ้นเมื่อทำงานเป็นเวลานาน โดยเอเจนต์ Gemini 3 Flash สะสมเหตุการณ์จำลองอาชญากรรม 683 ครั้ง ระหว่างการทดสอบ 15 วัน
Wilkinson 强调,CivBench 的核心价值在于提供一种更真实的战略推理衡量标准,比传统 QA คำถาม-คำตอบให้ความหมายลึกกว่ามาก:「ถ้าคุณทดสอบแค่ว่า AI ตอบคำว่า 'การยับยั้งด้วยอาวุธนิวเคลียร์คืออะไร' ได้หรือไม่ มันอาจจะได้เต็มคะแนน แต่ถ้าคุณให้มันเผชิญหน้ากับคู่ต่อสู้ที่ค่อย ๆ กดสถานการณ์ในกระดานจริง ๆ คุณจะได้เห็นสิ่งที่แตกต่างออกไปอย่างสิ้นเชิง。」
常見問題
是哪個具體的 AI 模型在遊戲中投下了原子彈?
根据报道,บล็อกของ Wilkinson ไม่ได้ระบุว่าโมเดลใดโดยเฉพาะที่เป็นผู้วางระเบิดนิวเคลียร์ รายงานเพียงอธิบายว่าเป็น «ภาษาโมเดลแนวล้ำ» และ «เอเจนต์ AI» รายโมเดลที่ใช้ในการทดสอบ CivBench ได้แก่ Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro และ Kimi K2.5
CivBench 的測試結果是否意味著 AI 在真實決策中也存在同樣的盲區?
ตามคำอธิบายของ Wilkinson มูลค่าหลักของ CivBench คือการให้มาตรวัดการประเมินเชิงกลยุทธ์ที่สมจริงกว่าการทดสอบแบบ QA แบบเดิม เพื่อเปิดเผยรูปแบบพฤติกรรมของ AI ในสถานการณ์แบบไดนามิกหลายมิติ เขาเน้นว่าเป้าหมายคือการให้กรอบการวัด ไม่ใช่การเปิดโปง «แนวโน้มชั่วร้าย» ของ AI ขณะที่งานวิจัยของ King's College London และ Emergence AI จากมุมมองที่แตกต่างกัน ก็ชี้ว่ารูปแบบพฤติกรรมของเอเจนต์ AI ในการทำงานแบบอิสระระยะยาวควรได้รับการติดตามอย่างต่อเนื่อง
同樣是 CivBench 測試,為何巴比倫文明的 Claude 反應截然不同?
ตามรายงาน ในกรอบเดียวกัน โมเดล AI ที่แตกต่างกันแสดงรูปแบบพฤติกรรมที่แตกต่างกันอย่างชัดเจน โดย Claude ที่ทำหน้าที่เป็นตัวแทนของอารยธรรมบาบิโลน เลือกที่จะยึดเส้นทางด้านเทคโนโลยี ไม่ใช่การลงมือปฏิบัติการเชิงรุก ความแตกต่างนี้นำไปสู่การถกเถียงในวงการวิชาการเกี่ยวกับ «ความแตกต่างของบุคลิก AI» ซึ่งชี้ให้เห็นว่าวิธีฝึกที่แตกต่างกันอาจส่งผลต่อแนวโน้มการตัดสินใจของเอเจนต์ AI ในสถานการณ์กดดันที่เหมือนกัน
