Fonte: Qubits
Pensar mais sobre as etapas antes do ChatGPT dar uma resposta pode melhorar a precisão.
Então, você pode pular o prompt e internalizar diretamente essa capacidade no modelo grande?
O novo estudo da CMU e da equipe do Google adiciona um token de pausa ao treinar modelos grandes para conseguir isso.
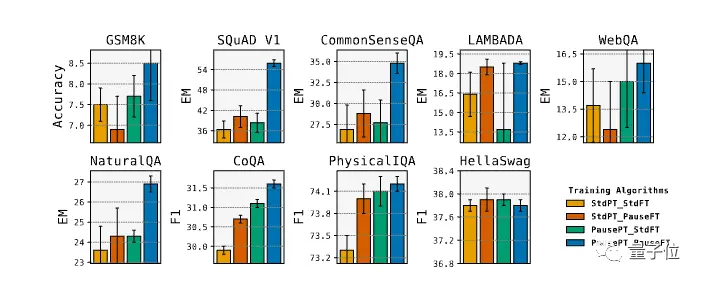
 No experimento, os escores de 8 avaliações melhoraram, entre os quais o escore EM do SQuAD aumentou em 18%, o CommonSenseQA aumentou em 8% e a tarefa de inferência no GSM8k também aumentou em 1%.
No experimento, os escores de 8 avaliações melhoraram, entre os quais o escore EM do SQuAD aumentou em 18%, o CommonSenseQA aumentou em 8% e a tarefa de inferência no GSM8k também aumentou em 1%.
 O pesquisador Jack Hack disse que havia apresentado uma hipótese semelhante há pouco tempo e ficou feliz em vê-la testada.
O pesquisador Jack Hack disse que havia apresentado uma hipótese semelhante há pouco tempo e ficou feliz em vê-la testada.
 O engenheiro da Nvidia, Aaron Erickson, disse que é uma verdade adicionar “uh-huh-ah” ao falar com humanos?
O engenheiro da Nvidia, Aaron Erickson, disse que é uma verdade adicionar “uh-huh-ah” ao falar com humanos?
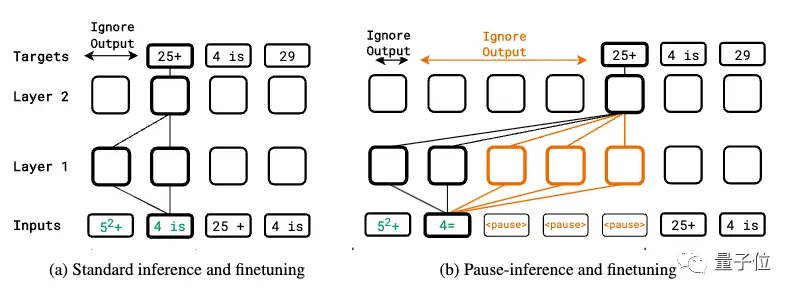
O ajuste fino pré-treinamento é adicionado ao token de pausa
Todo o estudo se baseia numa ideia simples:
Anexe uma série (token de pausa) à sequência de entrada, atrasando a saída do modelo para o próximo token.
Isso pode dar ao modelo tempo computacional adicional para processar entradas mais complexas.
 Os autores não só a introduzem quando a tarefa a jusante é ajustada, mas também a inserem aleatoriamente na sequência durante o pré-treino, permitindo que o modelo aprenda a tirar partido deste atraso computacional em ambas as fases.
Os autores não só a introduzem quando a tarefa a jusante é ajustada, mas também a inserem aleatoriamente na sequência durante o pré-treino, permitindo que o modelo aprenda a tirar partido deste atraso computacional em ambas as fases.
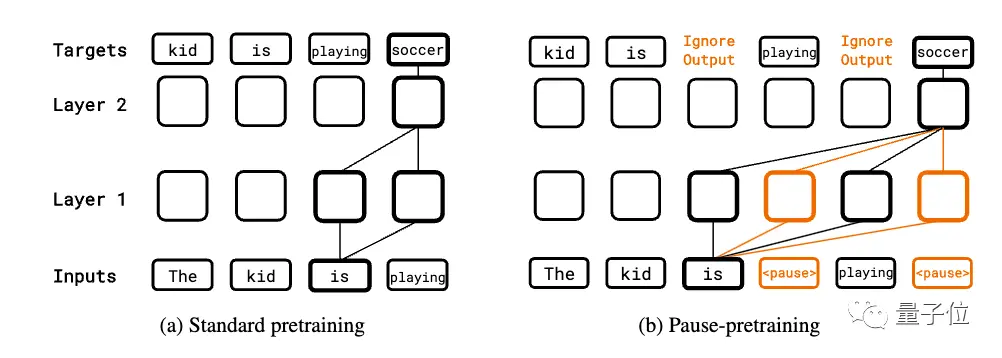 No estágio de pré-treinamento, uma certa porcentagem de tokens de pausa são inseridos aleatoriamente no corpus na sequência de entrada para pré-treinamento autorregressivo padrão. No entanto, a previsão do token suspenso é ignorada ao calcular a perda.
No estágio de pré-treinamento, uma certa porcentagem de tokens de pausa são inseridos aleatoriamente no corpus na sequência de entrada para pré-treinamento autorregressivo padrão. No entanto, a previsão do token suspenso é ignorada ao calcular a perda.
Quando a tarefa downstream é ajustada, um certo número de tokens de pausa é anexado à entrada e, em seguida, a previsão autorregressiva é feita na sequência de destino, enquanto ajusta os parâmetros do modelo.
A fase de inferência também acrescenta o mesmo número de tokens de pausa, mas ignora a saída do modelo até o último token de pausa e, em seguida, começa a extrair a resposta.
O experimento usa o modelo padrão Transformer pure Decoder, que é dividido em duas versões: 130M parâmetro e 1B parâmetro.
O token de pausa adiciona apenas 1024 parâmetros, que é seu próprio tamanho de incorporação.
Experimentos em 9 tarefas diferentes mostraram que o efeito da introdução de tokens de pausa apenas durante a fase de ajuste fino não era óbvio, e algumas tarefas não melhoraram.
Mas se você usar tokens de pausa nas fases de pré-treinamento e ajuste fino, obterá uma melhoria significativa na maioria das tarefas.
O documento também explora os principais hiperparâmetros, como o número e a localização dos tokens suspensos. Verificou-se que geralmente existe uma quantidade ideal para diferentes modelos.
Por fim, os autores também apontam que este trabalho também tem uma série de limitações.
- Uma vez que o token de suspensão aumenta a quantidade de cálculo do modelo, ainda não se discute se é justo comparar com outros métodos
- O novo método necessita de ser requalificado e continua a ser difícil aplicá-lo na prática
- Continua a verificar-se uma falta de compreensão aprofundada dos mecanismos de trabalho específicos
- Se o número de tokens de pausa for 0 durante a inferência, o modelo ainda terá um desempenho ruim
O CEO do motor de busca You.com disse que o próximo passo é experimentar todas as técnicas para melhorar o desempenho cognitivo humano em grandes modelos ?
 Agora há “pensar passo a passo” e “respirar fundo”.
Agora há “pensar passo a passo” e “respirar fundo”.
Talvez o próximo artigo de sucesso seja ensinar grandes modelos a dormir com problemas, ou uma alimentação e exercício mais escandalosamente saudáveis.
Endereço em papel:
Links de referência:
[1]
Isenção de responsabilidade: As informações contidas nesta página podem ser provenientes de terceiros e não representam os pontos de vista ou opiniões da Gate. O conteúdo apresentado nesta página é apenas para referência e não constitui qualquer aconselhamento financeiro, de investimento ou jurídico. A Gate não garante a exatidão ou o carácter exaustivo das informações e não poderá ser responsabilizada por quaisquer perdas resultantes da utilização destas informações. Os investimentos em ativos virtuais implicam riscos elevados e estão sujeitos a uma volatilidade de preços significativa. Pode perder todo o seu capital investido. Compreenda plenamente os riscos relevantes e tome decisões prudentes com base na sua própria situação financeira e tolerância ao risco. Para mais informações, consulte a
Isenção de responsabilidade.
