Fonte original: AIGC Open Community
 Fonte da imagem: Gerado por Unbounded AI
Fonte da imagem: Gerado por Unbounded AI
Em cenários de texto longo, modelos de linguagem grandes, como o ChatGPT, geralmente enfrentam custos de poder de computação mais altos, latência mais longa e pior desempenho. Para resolver esses três desafios, a Microsoft abriu o LongLLMLingua.
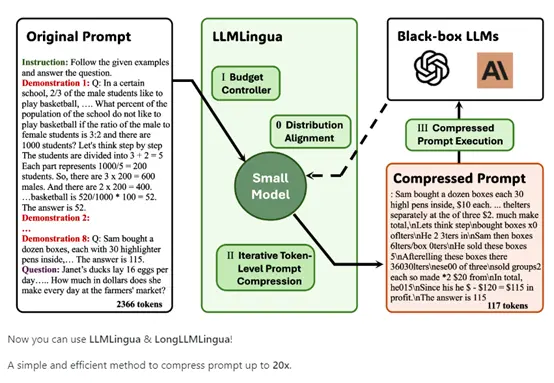
É relatado que o princípio técnico central do LongLLMLingua é alcançar até 20 vezes o limite de compressão de “prompt de texto”, e ao mesmo tempo pode avaliar com precisão a relevância do conteúdo no prompt para o problema, eliminar conteúdo irrelevante e reter informações importantes, e alcançar o objetivo de reduzir custos e aumentar a eficiência.
Os resultados experimentais mostram que o desempenho do prompt ** comprimido pelo LongLLMLingua é 17,1% maior do que o do prompt original, e os tokens inseridos no GPT-3.5-Turbo são reduzidos em 4 vezes**. Os testes LongBench e ZeroScrolls mostraram economias de custos de US$ 28,5 e US$ 27,4 por 1.000 amostras.
Quando uma dica de cerca de 10 k tokens é compactada e a taxa de compressão está na faixa de 2-10x, a latência de ponta a ponta pode ser reduzida em 1,4-3,8x, acelerando significativamente a taxa de inferência.
Endereço em papel:
Endereço Open Source:
A partir do artigo introdutório, LongLLMLingua é composto principalmente de quatro módulos: compressão grosseira-fina-granulada com reconhecimento de problemas, reordenação de documentos, taxa de compressão dinâmica e recuperação de subseqüência após a compressão.
Módulo de compressão de grão grosso com reconhecimento de problemas
A ideia deste módulo é usar condicionalmente o texto da pergunta, avaliar o quão relevante cada parágrafo é para a pergunta e manter os parágrafos mais relevantes.
 Especificamente, calculando o grau de confusão condicional do texto do problema e de cada parágrafo, o grau de correlação lógica entre os dois é julgado, e quanto menor a confusão condicional, maior a relevância.
Especificamente, calculando o grau de confusão condicional do texto do problema e de cada parágrafo, o grau de correlação lógica entre os dois é julgado, e quanto menor a confusão condicional, maior a relevância.
Com base nisso, estabeleça um limite para manter parágrafos com pouca confusão e filtrar parágrafos que não são relevantes para o problema. Isso permite a compactação de grão grosso para remover rapidamente grandes quantidades de informações redundantes com base no problema.
Módulo de Reordenação de Documentos
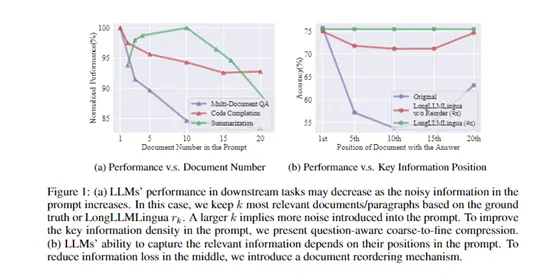
Estudos têm mostrado que, entre os prompts, o conteúdo próximo às posições inicial e final tem o maior impacto no modelo de linguagem. Portanto, o módulo reordena cada parágrafo de acordo com sua relevância, para que as informações-chave apareçam em uma posição mais sensível ao modelo, reduzindo a perda de informações na posição intermediária.
Usando o módulo de compressão de grão grosso para calcular a relevância de cada parágrafo para o problema, os parágrafos são classificados de modo que o parágrafo com o maior grau de relevância seja classificado em primeiro lugar. Isso melhora ainda mais a perceção do modelo de informações críticas.
 Depois de obter os parágrafos relacionados reordenados, a quantidade de palavras dentro de cada parágrafo precisa ser ainda mais compactada. Neste ponto, o módulo de taxa de compressão dinâmica ajusta finamente o prompt.
Depois de obter os parágrafos relacionados reordenados, a quantidade de palavras dentro de cada parágrafo precisa ser ainda mais compactada. Neste ponto, o módulo de taxa de compressão dinâmica ajusta finamente o prompt.
Módulo de Taxa de Compressão Dinâmica
Use uma taxa de compactação mais baixa para parágrafos mais relevantes e aloque mais orçamento para palavras reservadas, enquanto use uma taxa de compactação mais alta para parágrafos menos relevantes.
 A taxa de compressão para cada parágrafo é determinada dinamicamente utilizando a associatividade do parágrafo no resultado de compressão de grão grosso. Os parágrafos mais relevantes têm a menor taxa de compressão, e assim por diante.
A taxa de compressão para cada parágrafo é determinada dinamicamente utilizando a associatividade do parágrafo no resultado de compressão de grão grosso. Os parágrafos mais relevantes têm a menor taxa de compressão, e assim por diante.
Obtenha um controle de compressão adaptativo e refinado para reter informações críticas de forma eficaz. Após a compressão, também é necessário melhorar a confiabilidade dos resultados, o que requer o seguinte módulo de recuperação de subseqüência compactada.
Módulo de Recuperação de Subseqüência após Compressão
Durante o processo de compressão, algumas palavras-chave podem ser excessivamente excluídas, afetando a integridade das informações, e o módulo pode detetar e restaurar essas palavras-chave.
O princípio de funcionamento é usar a relação de subsequência entre o texto de origem, o texto comprimido e o texto gerado para recuperar as frases-chave completas dos resultados gerados, reparar a falta de informação trazida pela compressão e melhorar a precisão dos resultados.
 Todo o processo é um pouco como o nosso fluxo de trabalho para navegar rapidamente pelos artigos, peneirar informações, integrar pontos-chave, etc., para que o modelo capture rapidamente as informações-chave do texto e produza resumos de alta qualidade.
Todo o processo é um pouco como o nosso fluxo de trabalho para navegar rapidamente pelos artigos, peneirar informações, integrar pontos-chave, etc., para que o modelo capture rapidamente as informações-chave do texto e produza resumos de alta qualidade.
Dados experimentais LongLLMLingua
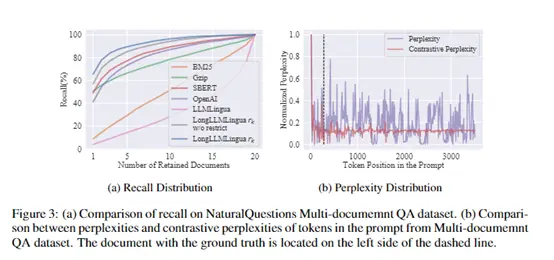
Os pesquisadores construíram um conjunto de dados de perguntas e respostas com vários documentos com base em Perguntas Naturais, no qual cada exemplo continha uma pergunta e 20 documentos relacionados dos quais as respostas eram necessárias.
Este conjunto de dados simula o mecanismo de pesquisa do mundo real e cenários de perguntas e respostas para avaliar o desempenho de perguntas e respostas do modelo em documentos longos.
Além disso, os pesquisadores usaram um conjunto mais geral de benchmarks de compreensão de texto longo, incluindo LongBench e ZeroSCROLLS, para avaliar a eficácia do método em uma gama mais ampla de cenários.
Entre eles, o LongBench cobre tarefas como perguntas e respostas de documento único, perguntas e respostas de vários documentos, resumo de texto e aprendizado de poucas amostras, incluindo conjuntos de dados de inglês. O ZeroSCROLLS inclui tarefas típicas de compreensão de linguagem, como resumo de texto, compreensão de respostas a perguntas e análise de sentimentos.
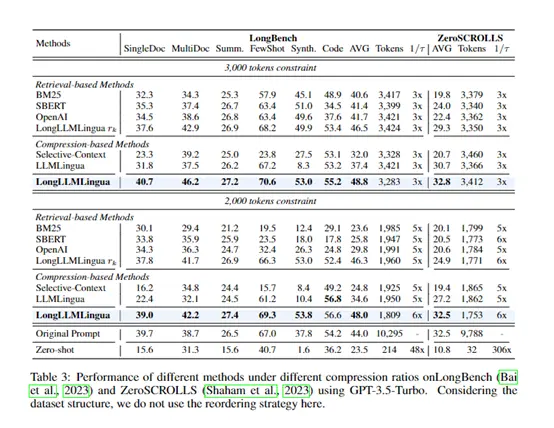 Nesses conjuntos de dados, os pesquisadores compararam o desempenho do prompt compactado do LongLLMLingua com o prompt original em um modelo de linguagem grande. Ao mesmo tempo, a eficácia do LongLLMLingua foi avaliada por comparação com outros métodos de compressão rápida, como LLMLingua baseado em quebra-cabeça e métodos baseados em recuperação.
Nesses conjuntos de dados, os pesquisadores compararam o desempenho do prompt compactado do LongLLMLingua com o prompt original em um modelo de linguagem grande. Ao mesmo tempo, a eficácia do LongLLMLingua foi avaliada por comparação com outros métodos de compressão rápida, como LLMLingua baseado em quebra-cabeça e métodos baseados em recuperação.
Os resultados experimentais mostram que o prompt compactado do LongLLMLingua é geralmente melhor do que o prompt original em termos de precisão de perguntas e respostas e qualidade do texto gerado.
Por exemplo, no NaturalQuestions, a compactação 4x de prompts melhorou a precisão das perguntas e respostas em 17,1%. Ao compactar uma dica de cerca de 10k tokens, a taxa de compressão está na faixa de 2-10x, e a latência de ponta a ponta pode ser reduzida em 1,4-3,8x. Isso prova plenamente que o LongLLMLingua pode melhorar a extração de informações-chave enquanto comprime dicas.
