Source: Heart of the Machine
Após anunciar abruptamente o fim da colaboração com a OpenAI em fevereiro, a conhecida startup de robótica Figure AI revelou na quinta-feira à noite as razões por trás disso: eles desenvolveram com sucesso o seu próprio modelo de inteligência corporal geral, o Helix.

O Helix é um modelo VLA (Visual-Language-Action) genérico que unifica a percepção, a compreensão da linguagem e o controle da aprendizagem para superar vários desafios de longa data na tecnologia de robôs.
A Helix criou vários primeiros:
- Controlo total do corpo: é o primeiro modelo VLA de controlo contínuo de alta velocidade do tronco superior de um robô semelhante ao humano na história, cobrindo pulsos, tronco, cabeça e dedo individual;
- Cooperação de Múltiplos Robôs: Dois robôs podem ser controlados em conjunto por um modelo, realizando tarefas nunca antes vistas;
- Pegue qualquer item: pode pegar qualquer objeto pequeno, incluindo milhares de itens que nunca encontrou antes, apenas seguindo instruções em linguagem natural;
- Rede Neural Única: Helix usa um conjunto de pesos de rede neural para aprender todas as ações — pegar e colocar itens, usar gavetas e geladeiras, e interagir entre robôs — sem a necessidade de ajustes finos específicos da tarefa;
- Localização: O Helix é o primeiro modelo de VLA de robô a ser executado em GPU localmente na história e já possui capacidade de implantação comercial.
No campo da condução autónoma, este ano todas as fábricas de automóveis estão a avançar com a implementação em grande escala da tecnologia de ponta a ponta, e agora os robôs acionados por VLA estão a entrar na contagem decrescente para a comercialização, o que faz com que o Helix seja um avanço significativo na inteligência corporificada.
Um conjunto de pesos da rede neural Helix é executado simultaneamente em dois robôs, trabalhando juntos para armazenar itens de mercearia nunca antes vistos.
Nova expansão da tecnologia de robôs humanoides
A Figura indica que o ambiente doméstico é o maior desafio enfrentado pela tecnologia de robôs. Ao contrário do ambiente industrial controlado, a casa está cheia de inúmeros objetos irregulares, como utensílios de vidro frágeis, roupas amarrotadas e brinquedos espalhados, cujas formas, tamanhos, cores e texturas são imprevisíveis. Para que os robôs possam desempenhar um papel na casa, eles precisam ser capazes de gerar novos comportamentos inteligentes conforme necessário.
A tecnologia atual de robótica não consegue ser expandida para o ambiente doméstico — atualmente, mesmo ensinar a um robô um único novo comportamento requer um grande investimento de recursos humanos. Ou leva horas de programação manual por um especialista de doutorado, ou milhares de demonstrações, ambos os métodos têm custos proibitivos.
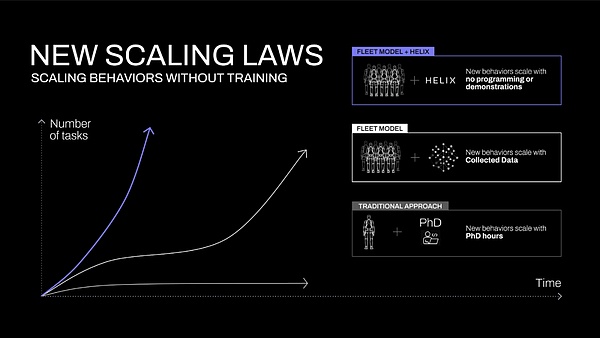
Figura 1: Curva de expansão de novas habilidades de robôs obtidas por diferentes métodos. No funcionamento heurístico tradicional, o crescimento das habilidades depende da escrita manual de scripts por especialistas. Na aprendizagem por imitação de robôs tradicional, a expansão das habilidades depende dos dados coletados. Com o Helix, novas habilidades podem ser especificadas instantaneamente por meio da linguagem.
Atualmente, outras áreas de inteligência artificial já dominaram essa capacidade de generalização instantânea. Talvez seja possível alcançar um avanço tecnológico simplesmente transformando diretamente o rico conhecimento semântico capturado pelo modelo visual-linguístico (VLM) em ações de robôs.
Esta nova capacidade vai mudar fundamentalmente a trajetória de expansão da tecnologia de robôs (Figura 1). Assim, a questão-chave torna-se: como extrair todo esse conhecimento comum do VLM e transformá-lo em controlo de robôs generalizável? Figure construiu Helix para colmatar esta lacuna.
Helix: o primeiro modelo de sistema de robôs 1 + sistema 2 VLA
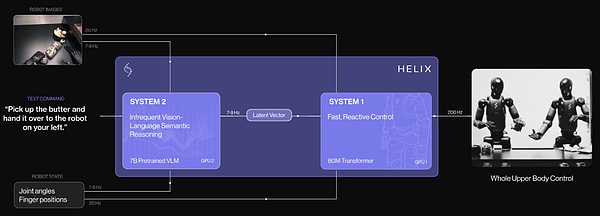
Helix é o primeiro modelo VLA “sistema 1 + sistema 2” no campo da robótica, usado para controlar rapidamente e habilmente a parte superior de um robô humanoide inteiro.
A Figure indica que os métodos anteriores enfrentavam um dilema fundamental: a espinha dorsal do VLM é genérica, mas não é rápida, enquanto a estratégia de movimento visual do robô é rápida, mas não é suficientemente genérica. O Helix resolve esse dilema através de dois sistemas complementares, ambos treinados de ponta a ponta e capazes de comunicar entre si:
- Sistema 1 (S1): uma estratégia de movimento visual de reação rápida que converte representações semânticas latentes geradas por S2 em ações contínuas precisas de robô a 200 Hz;
- Sistema 2 (S2): um VLM pré-treinado para Internet a bordo, operando a 7-9 Hz, para compreensão de cenários e linguagem, alcançando uma generalização ampla entre objetos e contextos.
Esta arquitetura desacoplada permite que cada sistema funcione na sua escala de tempo ideal. O S2 pode ‘pensar devagar’ nos objetivos de alto nível, enquanto o S1 pode ‘pensar rapidamente’ nas ações de execução e ajuste em tempo real do robô. Por exemplo, em comportamentos colaborativos (ver figura abaixo), o S1 pode se adaptar rapidamente às ações em constante mudança do robô parceiro, ao mesmo tempo mantendo os objetivos semânticos do S2.
 Helix pode permitir que os robôs façam ajustes de movimento fino rapidamente, o que é necessário para que eles reajam aos parceiros quando executam novos objetivos semânticos.
Helix pode permitir que os robôs façam ajustes de movimento fino rapidamente, o que é necessário para que eles reajam aos parceiros quando executam novos objetivos semânticos.
O design do Helix tem várias vantagens-chave em comparação com os métodos existentes:
- Velocidade e capacidade de generalização: Helix é comparável em velocidade às estratégias de clonagem de comportamento especializadas em tarefas únicas, ao mesmo tempo que consegue generalizar para milhares de novos objetos de teste sem amostras;
- Escalabilidade: O Helix produz diretamente um controlo contínuo do espaço de ação de alta dimensão, evitando o esquema de marcação de ação complexa utilizado anteriormente no método VLA. Estes esquemas tiveram algum sucesso em configurações de controlo de baixa dimensão (como garras paralelas binárias), mas enfrentam desafios de escalabilidade em controlo humanoide de alta dimensão;
- Simplicidade da arquitetura: O Helix utiliza uma arquitetura padrão - um VLM de código aberto e com peso aberto para o sistema 2, bem como uma estratégia de movimento visual baseada em Transformer simples para o sistema 1;
- Separação de preocupações: Desacoplar S1 e S2 nos permite iterar separadamente em cada sistema, sem a necessidade de procurar um espaço de observação ou representação de ação unificado.
A Figura apresenta alguns modelos e detalhes de treinamento, que coletaram um conjunto diversificado de dados de comportamento remoto de alta qualidade, com vários robôs e operadores, totalizando cerca de 500 horas. Para gerar pares de treinamento sob condições de linguagem natural, os engenheiros utilizaram um modelo de linguagem visual (VLM) automaticamente rotulado para gerar instruções pós-evento.
O VLM lidará com segmentos de vídeo de câmeras embarcadas em robôs e perguntará: ‘Que comandos você daria ao robô para executar as ações vistas no vídeo?’ Todos os itens manipulados durante o treinamento são excluídos da avaliação para evitar a contaminação dos dados.
Arquitetura do Modelo
O sistema Helix é composto principalmente por dois componentes principais: S2, uma rede principal VLM; S1, um Transformer potencial de movimento visual condicional.
O S2 é construído com base num VLM de código aberto e aberto com 7 bilhões de parâmetros, pré-treinado em dados em escala de Internet. Ele lida com informações de imagem e estado do robô de visão única (incluindo postura do pulso e posição dos dedos), e as projeta no espaço de incorporação de linguagem visual. Combinando instruções de linguagem natural especificando comportamentos desejados, o S2 destila todas as informações relevantes para as tarefas semânticas em um vetor latente contínuo, transmitindo para o S1 para modular suas ações de baixo nível.
S1 é um codificador-decodificador Transformer de atenção cruzada com 80 milhões de parâmetros, responsável pelo controle de baixo nível. Ele depende de uma rede visual multicamadas totalmente convolucional para processamento visual, inicializada no ambiente de simulação. Embora S1 receba as mesmas entradas de imagem e estado que S2, ele processa essas entradas com uma frequência mais alta para alcançar um controle em loop mais responsivo. O vetor latente de S2 é projetado no espaço de marcação de S1 e conectado ao longo da dimensão da sequência com as características visuais extraídas pela rede visual de S1, proporcionando condições de tarefa.
Durante o trabalho, S1 produz um controle completo da forma humana superior a 200 hertz, incluindo postura desejada do pulso, controle de flexão e extensão dos dedos, e orientação do tronco e da cabeça. A Figure adicionou um movimento sintético de “percentagem de conclusão da tarefa” ao espaço de ação, permitindo que o Helix preveja sua própria condição de término, facilitando assim a classificação de vários comportamentos aprendidos.
Treinamento
O treinamento do Helix é totalmente ponta a ponta: mapeando pixels e comandos de texto originais para ações contínuas com perda de regressão padrão.
O caminho de propagação inversa do gradiente é permitir a otimização conjunta desses dois componentes, permitindo que o vetor de comunicação oculta, usado para modular o comportamento S1, seja propagado de S1 para S2.
O Helix não precisa de ajustes específicos para tarefas individuais; ele só precisa manter uma única fase de treinamento e um conjunto de pesos de rede neural, sem a necessidade de uma cabeça de ação separada ou de uma fase de ajuste fino para cada tarefa.
Durante o treinamento, eles também adicionam um deslocamento de tempo entre as entradas S1 e S2. Esse deslocamento é calibrado para corresponder à diferença de atraso de inferência implantada entre S1 e S2, garantindo que os requisitos de controle em tempo real durante a implantação reflitam com precisão o treinamento.
Inferência de fluxo otimizada
O design de treino da Helix permite a implantação eficiente de modelos em paralelo nos robôs Figure, cada um equipado com duas GPUs embarcadas de baixo consumo de energia. O pipeline de inferência é dividido em modelos de planeamento de alto nível S2 e controlo de baixo nível S1, cada modelo a ser executado numa GPU dedicada.
S2 executa como um processo de fundo assíncrono para lidar com as últimas observações (câmera embarcada e estado do robô) e comandos de linguagem natural. Ele atualiza continuamente o vetor oculto compartilhado de memória para codificar intenções comportamentais avançadas.
O S1 é executado como um processo em tempo real independente, com o objetivo de manter o loop de controle chave de 200Hz necessário para a execução suave de todo o movimento do corpo superior. A sua entrada são os resultados de observação mais recentes e o mais recente vetor oculto S2. Devido à diferença de velocidade inerente entre o raciocínio de S2 e S1, o S1 naturalmente funcionará com uma resolução temporal mais alta na observação do robô, criando assim um loop de feedback mais estreito para o controle de reação.
Esta estratégia de implementação reflete intencionalmente o deslocamento temporal introduzido no treino, podendo assim reduzir ao máximo a discrepância entre o treino e a distribuição de inferência. Este modelo de execução assíncrona permite que dois processos funcionem com as suas melhores taxas, garantindo que a Helix funcione à mesma velocidade que a estratégia de aprendizagem de imitação de tarefa única mais rápida.
Curiosamente, após o lançamento do Figure Helix, o doutorando da Universidade Tsinghua, Yanjiang Guo, afirmou que sua abordagem técnica é bastante semelhante a um artigo CoRL 2024 deles, os leitores interessados também podem consultar.

Endereço do artigo:
Resultados
Controlo total do corpo inteiro VLA de granularidade fina
O Helix pode coordenar um espaço de ação de 35 graus de liberdade a uma frequência de 200Hz, controlando tudo, desde o movimento de um único dedo até a trajetória do atuador final, a orientação da cabeça e a postura do tronco.
O controle da cabeça e do tronco apresenta desafios únicos - quando a cabeça e o tronco se movem, eles mudam a gama que o robô pode alcançar e ver, criando assim um loop de feedback, no passado, esse loop de feedback costumava levar à instabilidade.
O vídeo 3 demonstra a operação prática dessa coordenação: o robô rastreia suavemente as duas mãos com a cabeça, ajustando simultaneamente o tronco para obter a melhor amplitude de toque, mantendo ao mesmo tempo um controle preciso dos dedos para a manipulação. Antes disso, alcançar esse nível de precisão em um espaço de movimento tão complexo era difícil, mesmo para uma única tarefa conhecida. A empresa Figure afirma que nenhum sistema VLA anterior foi capaz de exibir esse nível de coordenação em tempo real, mantendo a capacidade de generalização entre tarefas e objetos.

O VLA da Helix pode controlar a parte superior de um robô humanoide, sendo o primeiro modelo a fazê-lo neste campo de estudo de robótica.
Zero Sample Multi-Robot Collaboration
A Figure indica que empurrou o Helix ao limite num cenário de operações multiagentes de alta dificuldade: dois robôs da Figure colaboraram para armazenar mantimentos sem amostras.
O vídeo 1 mostra dois avanços básicos: dois robôs operaram com sucesso itens totalmente novos (nunca encontrados durante o treinamento), demonstrando uma generalização robusta para várias formas, tamanhos e materiais.
Além disso, ambos os robôs operam com os mesmos pesos do modelo Helix, sem necessidade de treinamento específico para robôs individuais ou atribuições de papel explícitas. A sua cooperação é realizada através de instruções em linguagem natural, como “Pegue um saco de biscoitos e entregue ao robô à sua direita” ou “Pegue um saco de biscoitos do robô à sua esquerda e coloque-o na gaveta aberta” (ver vídeo 4). Esta é a primeira vez que o VLA é usado para mostrar operações de cooperação flexíveis e expansíveis entre vários robôs. O fato de terem lidado com objetos totalmente novos com sucesso torna essa conquista ainda mais significativa.

O Helix realiza uma colaboração precisa entre vários robôs
Emergência da capacidade de ‘pegar qualquer coisa’


Com apenas uma instrução de ‘pegar [X]’, o robô Figure equipado com Helix pode basicamente pegar qualquer item doméstico pequeno. Durante os testes sistêmicos, sem necessidade de demonstração prévia ou programação personalizada, o robô conseguiu lidar com milhares de novos itens bagunçados - desde utensílios de vidro e brinquedos até ferramentas e roupas.
É particularmente notável que o Helix possa estabelecer uma ligação entre a compreensão da linguagem em escala da internet e o controlo preciso de robôs. Por exemplo, quando solicitado a ‘pegar itens do deserto’, o Helix não só consegue identificar que um cato de brinquedo corresponde a este conceito abstrato, mas também pode selecionar a mão mais próxima e comandar com precisão um movimento seguro para a pegar.
A empresa afirma: “Para implantar robôs humanoides em ambientes não estruturados, essa capacidade de captura de ‘linguagem para ação’ genérica abre novas possibilidades emocionantes.”

O Helix pode traduzir instruções de alto nível, como “pegar [X]”, em ações de baixo nível.
Discussão
A eficiência de treinamento do Helix é muito alta
Helix alcançou uma poderosa generalização de objetos com recursos extremamente limitados. A Figure afirma: “Usamos aproximadamente 500 horas de dados de supervisão de alta qualidade no total para treinar o Helix, o que representa apenas uma pequena parte do conjunto de dados VLA coletado anteriormente (<5%), e não depende da coleta de dados de múltiplos robôs ou de várias fases de treinamento.” Eles observaram que essa escala de coleta se assemelha mais aos conjuntos de dados modernos de aprendizado por imitação de tarefas únicas. Apesar da demanda relativamente pequena de dados, o Helix pode ser expandido para espaços de ação mais desafiadores, ou seja, controle completo do corpo superior, com saídas de alta taxa e alta dimensão.
conjunto de peso único
Os sistemas VLA existentes geralmente exigem ajustes finos especializados ou cabeças de ação dedicadas para otimizar o desempenho na execução de diferentes comportamentos avançados. É digno de nota que o Helix pode realizar apanhar e colocar itens em vários recipientes, operar gavetas e frigoríficos, coordenar transferências hábeis entre vários robôs e manipular milhares de novos objetos, tudo isso com apenas um conjunto de pesos de rede neural (7B para o Sistema 2, 80M para o Sistema 1).

Pegar no Helix (Helix significa espiral)
Resumo
Helix é o primeiro modelo “visão-linguagem-movimento” que controla diretamente a parte superior de um robô humanoide através da linguagem natural. Ao contrário dos sistemas de robôs anteriores, o Helix é capaz de gerar instantaneamente operações de longo alcance, colaborativas e ágeis, sem a necessidade de demonstrações específicas da tarefa ou programação manual extensa.
O Helix demonstrou uma forte capacidade de generalização de objetos, podendo pegar milhares de novos itens para casa com diferentes formas, tamanhos, cores e características de material, que nunca foram encontrados durante o treinamento, apenas com comandos de linguagem natural. A empresa afirmou: “Isso representa um passo transformador na expansão do comportamento dos robôs humanoides - acreditamos que isso será fundamental à medida que nossos robôs ajudem cada vez mais no ambiente doméstico diário.”
Embora esses resultados iniciais sejam de fato animadores, em geral, o que vimos acima ainda é uma validação de conceito, apenas demonstrando possibilidades. A verdadeira transformação ocorrerá quando Helix for implantado em larga escala na prática. Esperamos ansiosamente por esse dia!
A propósito, o lançamento da Figure pode ser apenas um pequeno passo para a inteligência encarnada este ano. Hoje, de madrugada, o robô 1X também anunciou o lançamento iminente de novos produtos.