Source: Qubits
Thinking more about the steps before ChatGPT gives an answer can improve accuracy.
So can you skip the prompt and directly internalize this ability in the big model?
The new study by CMU and the Google team adds a pause token when training large models to achieve this.
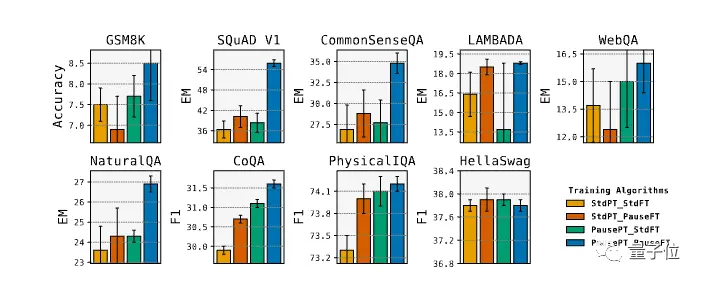
 In the experiment, the scores of 8 evaluations improved, among which the EM score of SQuAD increased by 18%, the CommonSenseQA increased by 8%, and the inference task in GSM8k also increased by 1%.
In the experiment, the scores of 8 evaluations improved, among which the EM score of SQuAD increased by 18%, the CommonSenseQA increased by 8%, and the inference task in GSM8k also increased by 1%.
 Researcher Jack Hack said he had come up with a similar hypothesis not long ago and was glad to see it tested.
Researcher Jack Hack said he had come up with a similar hypothesis not long ago and was glad to see it tested.
 Nvidia engineer Aaron Erickson said that is it a truth to add “uh-huh-ah” when talking to humans?
Nvidia engineer Aaron Erickson said that is it a truth to add “uh-huh-ah” when talking to humans?
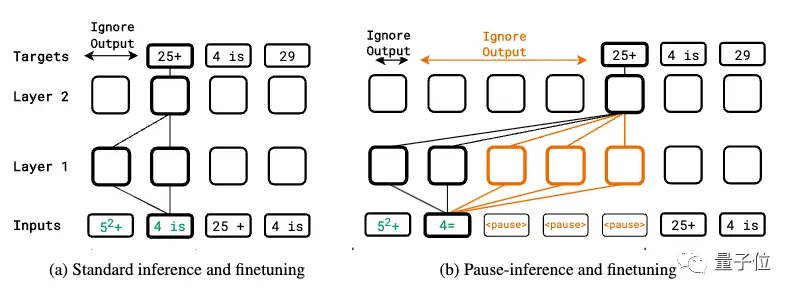
Pre-training fine-tuning are added to the pause token
The whole study is based on a simple idea:
Append a series (pause token) to the input sequence, delaying the model from outputting the next token.
This can give the model additional computational time to process more complex inputs.
 The authors not only introduce it when the downstream task is fine-tuned, but also randomly insert it into the sequence during pre-training, allowing the model to learn how to take advantage of this computational delay in both stages.
The authors not only introduce it when the downstream task is fine-tuned, but also randomly insert it into the sequence during pre-training, allowing the model to learn how to take advantage of this computational delay in both stages.
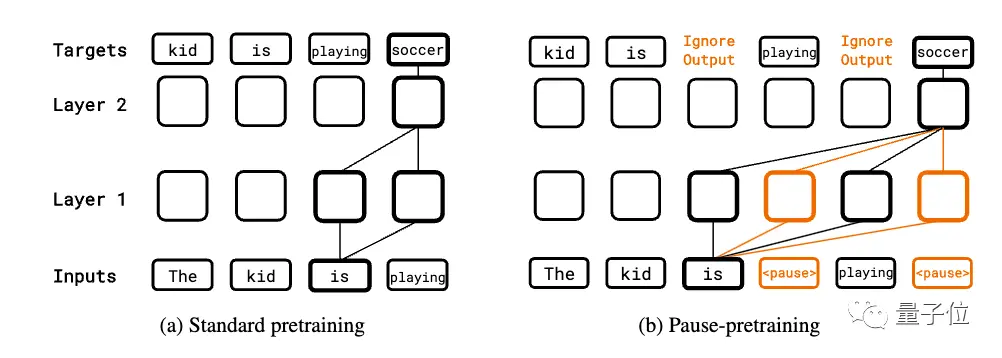 In the pre-training stage, a certain percentage of pause tokens are randomly inserted into the corpus into the input sequence for standard autoregressive pre-training. However, the prediction of the suspended token is skipped when calculating the loss.
In the pre-training stage, a certain percentage of pause tokens are randomly inserted into the corpus into the input sequence for standard autoregressive pre-training. However, the prediction of the suspended token is skipped when calculating the loss.
When the downstream task is fine-tuned, a certain number of pause tokens are appended to the input, and then autoregressive prediction is made on the target sequence, while fine-tuning the model parameters.
The inference phase also appends the same number of pause tokens, but ignores the model output until the last pause token, and then starts extracting the answer.
The experiment uses the standard Transformer pure Decoder model, which is divided into two versions: 130M parameter and 1B parameter.
The pause token only adds 1024 parameters, which is its own embedding size.
Experiments on 9 different tasks showed that the effect of introducing pause tokens only during the fine-tuning phase was not obvious, and some tasks did not improve.
But if you use pause tokens in both the pre-training and finetune phases, you get a significant improvement on most tasks.
The paper also explores key hyperparameters such as the number and location of suspended tokens. It was found that there is usually an optimal quantity for different models.
Finally, the authors also point out that this work also has a number of limitations.
- Since the suspension token increases the amount of model computation, whether it is fair to compare with other methods remains to be discussed
- The new method needs to be re-pre-trained, and it is still difficult to apply it in practice
- There is still a lack of in-depth understanding of specific working mechanisms
- If the number of pause tokens is 0 during inference, the model still performs poorly
The CEO of the search engine You.com said that the next step is to try all the techniques for improving human cognitive performance on large models?
 Now there is “think step by step” and “take a deep breath”.
Now there is “think step by step” and “take a deep breath”.
Maybe the next blockbuster paper is to teach big models to sleep with problems, or more outrageously healthy eating and exercise.
Paper Address:
Reference Links:
[1]
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
