Основні поради:
ChatGPT та інші чат-штучні інтелекти, засновані на технології обробки природної мови, мають три основні проблеми з дотриманням законодавства, які необхідно терміново вирішити в короткостроковій перспективі:
По-перше, коли справа доходить до прав інтелектуальної власності на відповіді, надані чат-штучним інтелектом, основна проблема відповідності полягає в тому, чи відповіді, створені чат-штучним інтелектом, генерують відповідні права інтелектуальної власності, і чи потрібен дозвіл на права інтелектуальної власності.
По-друге, чи потрібен процес інтелектуального аналізу даних і навчання чат-штучного інтелекту на величезній кількості тексту для обробки природної мови (широко відомого як корпус) для отримання відповідних прав інтелектуальної власності?
По-третє, одним із механізмів відповіді ChatGPT та інших чат-ШІ є отримання статистичної мовної моделі шляхом математичного статистичного підрахунку великої кількості наявних текстів природною мовою, що призводить до того, що чатовий ШІ, швидше за все, «говоритиме серйозну нісенітницю», що, своєю чергою, призводить до юридичного ризику поширення неправдивої інформації.
Загалом наразі законодавство Китаю про штучний інтелект все ще перебуває на стадії попереднього дослідження, і немає офіційного законодавчого плану чи відповідного проєкту пропозиції, а відповідні відомства особливо обережно ставляться до нагляду за сферою штучного інтелекту.

1. ChatGPT – це не “технологія штучного інтелекту між епохами”
ChatGPT по суті є продуктом розвитку технології обробки природної мови, і все ще по суті є лише мовною моделлю.
На початку 2023 року величезні інвестиції глобального технологічного гіганта Microsoft зробили ChatGPT «топовим потоком» у технологічній сфері та успішно вийшли з кола. З різким зростанням концепції ChatGPT на ринку капіталу багато вітчизняних технологічних компаній також почали викладати це поле, тоді як ринок капіталу з ентузіазмом ставиться до концепції ChatGPT, ми, як юридичні працівники, не можемо не оцінити, які ризики правової безпеки може принести сам ChatGPT, і який його шлях дотримання законодавства?
Перш ніж обговорювати юридичні ризики та шляхи відповідності ChatGPT, ми повинні спочатку вивчити технічне обґрунтування ChatGPT – чи дає ChatGPT запитувачу будь-які запитання, які він хоче, як випливає з новин?
В очах команди сестри Са ChatGPT здається далеко не таким «богом», як рекламували деякі новини – одним словом, це просто інтеграція технологій обробки природної мови, таких як Transformer і GPT, і це все одно по суті мовна модель, заснована на нейронних мережах, а не «прогрес ШІ між епохами».
Як згадувалося раніше, ChatGPT є продуктом розвитку технології обробки природної мови, і з точки зору історії розвитку технології, він приблизно пройшов три етапи: мовну модель, засновану на граматиці, мовну модель, засновану на статистиці, і мовну модель, засновану на нейронних мережах Принцип роботи та юридичні ризики, які можуть виникнути з цього принципу, повинні бути спочатку з’ясовані як робочий принцип статистичної мовної моделі, попередника мовної моделі, заснованої на нейронних мережах.
На етапі мовної моделі, заснованої на статистиці, інженери штучного інтелекту визначають ймовірність послідовних зв’язків між словами, підраховуючи величезну кількість тексту природною мовою, і коли люди ставлять запитання, ШІ починає аналізувати, які слова є високоймовірними в мовному середовищі, де складаються складові слова задачі, а потім з’єднує ці слова з високою ймовірністю разом, щоб повернути статистичну відповідь. Можна сказати, що цей принцип пройшов через розвиток технології обробки природної мови з моменту її появи, і навіть у певному сенсі подальша поява мовних моделей на основі нейронних мереж також є модифікацією мовних моделей, заснованих на статистиці.
Щоб навести простий для розуміння приклад, команда сестри Са ввела запитання «Які туристичні пам’ятки є в Даляні?» у вікно чату ChatGPT, як показано на малюнку нижче:
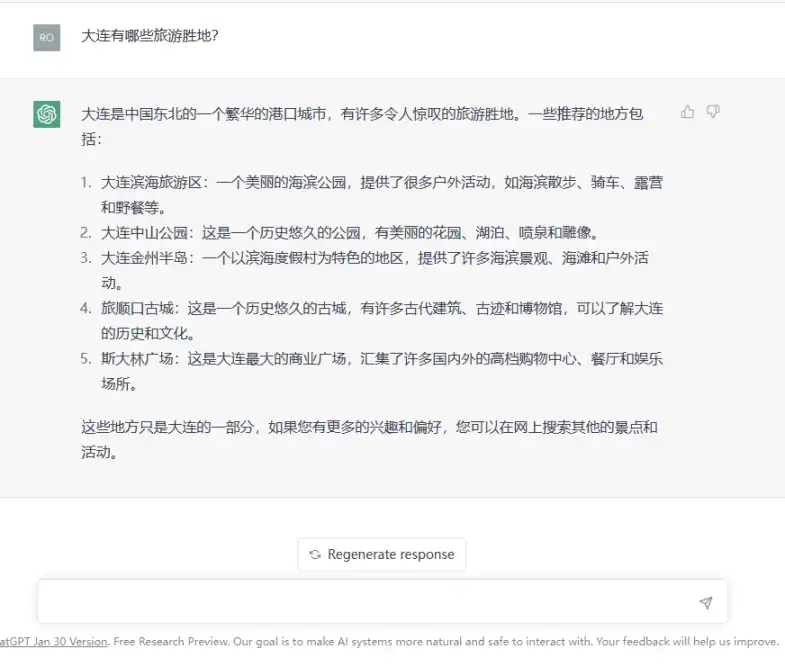
На першому етапі ШІ проаналізує основні морфеми в питанні «Далянь, які, туристичні та мальовничі місця», а потім знайде набір тексту природною мовою, де ці морфеми розташовані в існуючому корпусі, знайде словосполучення з найбільшою ймовірністю входження в цьому наборі, а потім об’єднає ці словосполучення, щоб сформувати остаточну відповідь. Наприклад, ШІ виявить, що в корпусі є слово «Парк Чжуншань» з високою ймовірністю появи трьох слів «Далянь, туризм і курорт», тому він повернеться до «Парк Чжуншань», а слово «парк» має найвищу ймовірність словосполучення з такими словами, як сад, озеро, фонтан, статуя і т.д., тому воно далі повернеться «Це історичний парк з прекрасними садами, озерами, фонтанами і статуями. 」
Іншими словами, весь процес ґрунтується на статистиці ймовірностей текстової інформації природною мовою (корпус), яка вже існує за ШІ, тому відповіді, що повертаються, також є «статистичними результатами», що призводить до «серйозної нісенітниці» ChatGPT з багатьох питань. Як відповідь на питання «Які туристичні пам’ятки в Даляні», хоча в Даляні є парк Чжуншань, в парку Чжуншань немає озер, фонтанів і статуй. В історії Даляня дійсно була «площа Сталіна», але площа Сталіна ніколи не була комерційною площею, як і на ній не було торгових центрів, ресторанів чи розважальних закладів. Судячи з усього, інформація, яку повертає ChatGPT, є неправдивою.

По-друге, ChatGPT наразі є найбільш підходящим сценарієм застосування як мовна модель
Хоча в попередній частині ми прямо пояснили недоліки мовних моделей на основі статистики, ChatGPT вже є мовною моделлю на основі нейронних мереж, яка значно покращує мовну модель, засновану на статистиці, а її технічна основа Transformer і GPT є останнім поколінням мовних моделей Модель об’єднана для дуже глибокого моделювання природної мови, і повернуті речення іноді є «нісенітницею», але на перший погляд вони все одно виглядають як «людські відповіді», тому ця технологія має широкий спектр сценаріїв застосування в сценаріях, що вимагають масової взаємодії людини з комп’ютером.
Наразі таких сценаріїв три:
По-перше, пошукові системи;
По-друге, механізм взаємодії людини і комп’ютера в банках, юридичних фірмах, різних посередниках, торгових центрах, лікарнях і державних сервісних платформах, таких як система скарг клієнтів, навігація по інструкціях і система консультацій з питань державних справ у вищезгаданих місцях;
По-третє, механізм взаємодії розумних автомобілів і розумних будинків (таких як розумні колонки і розумні світильники).
Пошукові системи, які поєднують технології чату зі штучним інтелектом, такі як ChatGPT, швидше за все, представлять традиційний підхід на основі пошукових систем + мовні моделі на основі нейронних мереж. В даний час традиційні пошукові гіганти, такі як Google і Baidu, мають глибоке накопичення технології мовних моделей на основі нейронних мереж, наприклад, у Google є Sparrow і Lamda, які можна порівняти з ChatGPT.
Застосування технології чату зі штучним інтелектом, такої як ChatGPT, у системі скарг клієнтів, керівництві та навігації лікарень і торгових центрів, а також системі консультацій державних установ з питань державних справ значно знизить витрати на людські ресурси відповідних підрозділів і заощадить час спілкування, але проблема полягає в тому, що відповіді, засновані на статистиці, можуть давати абсолютно неправильні відповіді на контент, і ризики контролю ризиків, пов’язані з цим, можливо, потребують додаткової оцінки.
У порівнянні з двома вищезазначеними сценаріями застосування, юридичний ризик того, що додаток ChatGPT стане механізмом взаємодії людини та комп’ютера вищезгаданих пристроїв у сферах розумних автомобілів та розумних будинків, набагато менший, оскільки прикладне середовище в цій галузі є відносно приватним, а неправильний контент, що подається ШІ, не спричинить великих юридичних ризиків, і в той же час такі сценарії не мають високих вимог до точності контенту, а бізнес-модель є більш зрілою.

III. Попереднє дослідження юридичних ризиків ChatGPT та шляху комплаєнсу
По-перше, загальний нормативно-правовий ландшафт штучного інтелекту в Китаї
Як і багато нових технологій, технологія обробки природної мови, представлена ChatGPT, стикається з «дилемою Коллінгріджа» Ця дилема включає в себе інформаційну дилему, тобто соціальні наслідки нової технології, які не можуть бути передбачені на ранній стадії технології, і так звану дилему контролю, тобто, коли виявляються несприятливі соціальні наслідки нової технології, технологія часто стає частиною всієї соціальної та економічної структури, так що несприятливі соціальні наслідки не можуть бути ефективно контрольовані.
У той час, коли сфера штучного інтелекту, особливо технології обробки природної мови, перебуває на стадії бурхливого розвитку, технологія, швидше за все, потрапить у так звану «дилему Коллінгріджа», а відповідне правове регулювання, схоже, не «встигає». В даний час в Китаї відсутнє національне законодавство про індустрію штучного інтелекту, але були відповідні законодавчі спроби на місцевому рівні. У вересні минулого року Шеньчжень оголосив «Положення про сприяння розвитку індустрії штучного інтелекту в Шеньчженьській особливій економічній зоні», яке є спеціальним законодавством для національної індустрії нештучного інтелекту, а потім Шанхай також прийняв «Положення про сприяння розвитку індустрії штучного інтелекту в Шанхаї».
Що стосується етичного регулювання штучного інтелекту, Національний професійний комітет з управління штучним інтелектом нового покоління також видав у 2021 році «Кодекс етики штучного інтелекту нового покоління», запропонувавши інтегрувати етику в весь життєвий цикл досліджень і розробок штучного інтелекту.
По-друге, юридичний ризик дезінформації, спричиненої ChatGPT
Зміщуючи фокус з макро на мікро, окрім загального нормативно-правового ландшафту індустрії штучного інтелекту та етичного регулювання штучного інтелекту, практичні питання відповідності, що існують в основі чатів зі штучним інтелектом, таких як ChatGPT, також потребують термінової уваги.
Як згадувалося в частині 2 цієї статті, робочий механізм ChatGPT дозволяє його відповідям бути абсолютно “серйозною нісенітницею”, що вкрай вводить в оману. Звичайно, неправдиві відповіді на запитання на кшталт «які туристичні визначні пам’ятки в Даляні» можуть не мати серйозних наслідків, але якщо ChatGPT застосувати до пошукових систем, систем скарг клієнтів та інших сфер, неправдива інформація, на яку він відповідає, може становити надзвичайно серйозні юридичні ризики.
Власне, такий юридичний ризик уже з’явився, і Galactica, мовна модель у сфері наукових досліджень сервісу Meta, яка була запущена майже одночасно з ChatGPT у листопаді 2022 року, була виведена в автономний режим лише через 3 дні тестування через неоднозначні запитання про правдиві та хибні відповіді. Виходячи з того, що технічні принципи не можуть бути зламані за короткий проміжок часу, якщо ChatGPT та подібні мовні моделі застосовуються до пошукових систем, систем скарг клієнтів та інших сфер, вони повинні бути трансформовані для відповідності. Коли виявляється, що користувач може поставити професійне запитання, користувачеві слід направити його на консультацію до відповідного фахівця замість того, щоб шукати відповідь у ШІ, і слід значно нагадати користувачеві, що автентичність запитань, які повертає ШІ чату, може потребувати додаткової перевірки, щоб мінімізувати відповідні ризики відповідності.
По-третє, проблеми з дотриманням вимог інтелектуальної власності, спричинені ChatGPT
Зміщуючи акцент з макро на мікро, окрім автентичності відповідей ШІ, питання інтелектуальної власності чатового ШІ, особливо великих мовних моделей, таких як ChatGPT, також мають привернути увагу комплаєнс-офіцерів.
Перша проблема комплаєнсу полягає в тому, чи потребує «інтелектуальний аналіз текстових даних» відповідного ліцензування інтелектуальної власності. Як зазначалося вище, ChatGPT покладається на величезну кількість текстів природною мовою (або мовних баз даних), ChatGPT потрібно видобувати та навчати дані в корпусі, а ChatGPT потрібно копіювати вміст корпусу у власну базу даних, і відповідна поведінка часто називається «інтелектуальним аналізом текстових даних» у сфері обробки природної мови. Виходячи з припущення, що відповідні текстові дані можуть становити твір, все ще існують суперечки щодо того, чи порушує інтелектуальний аналіз текстових даних право на відтворення.
У сфері порівняльного права і Японія, і Європейський Союз розширили сферу добросовісного використання у своєму законодавстві про авторське право, додавши «інтелектуальний аналіз текстових даних» у ШІ як новий випадок добросовісного використання. Хоча деякі вчені виступали за зміну китайської системи добросовісного використання з «закритої» на «відкриту» в процесі перегляду закону Китаю про авторське право в 2020 році, ця пропозиція не була остаточно прийнята, і в даний час закон Китаю про авторське право все ще зберігає закриті положення системи добросовісного використання, і тільки тринадцять обставин, передбачених статтею 24 Закону про авторське право, можуть бути визнані добросовісним використанням, іншими словами, в даний час закон Китаю про авторське право не включає «інтелектуальний аналіз текстових даних» в ШІ Інтелектуальний аналіз текстових даних, що входить до сфери розумного застосування, все ще вимагає відповідного дозволу інтелектуальної власності в Китаї.
Що стосується питання про те, чи є роботи, створені штучним інтелектом, оригінальними, команда сестри Са вважає, що критерії судження не повинні відрізнятися від існуючих стандартів судження, іншими словами, незалежно від того, чи виконана відповідь штучним інтелектом або людиною, вона повинна оцінюватися відповідно до існуючих стандартів оригінальності. Очевидно, що за законами про інтелектуальну власність більшості країн, включаючи Китай, автором твору може бути лише фізична особа, а ШІ не може стати автором твору.
Нарешті, якщо ChatGPT зрощує сторонній твір у своїй відповіді, як слід обробляти його права інтелектуальної власності? Команда сестри Са вважає, що якщо відповідь ChatGPT зрощує захищений авторським правом твір у корпусі (хоча це з меншою ймовірністю станеться відповідно до принципу роботи ChatGPT), то відповідно до чинного закону Китаю про авторське право, якщо це не є добросовісним використанням, його потрібно скопіювати без дозволу власника авторських прав.

