crypto花椒
用户暂无简介
crypto花椒
做了一个全球邮轮尾单监控🚢
基本上能跑的邮轮都能涵盖,五维评分从价格偏离度/出发紧迫度/舱型价值/航线热门度/历史稀缺性综合评分
包括了10个OTA聚合社区 + 30多个邮轮公司直销网站
我也要抢到3万rmb的南极船票
基本上能跑的邮轮都能涵盖,五维评分从价格偏离度/出发紧迫度/舱型价值/航线热门度/历史稀缺性综合评分
包括了10个OTA聚合社区 + 30多个邮轮公司直销网站
我也要抢到3万rmb的南极船票
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Kevin Warsh的Fed主席提名听证会定在4月16号。
Trump想换掉Powell
Warsh的履历很扎实。斯坦福+哈佛法学院,Morgan Stanley做过高管,2006年成为美联储历史上最年轻的理事。Bush时代的人。
但他面临两个障碍。
第一个:Thom Tillis参议员公开说不投票。原因不是反对Warsh本人,是要求司法部先结束对Powell的调查。一个共和党人卡自己党的提名,这在Fed人事上很少见。
第二个:Elizabeth Warren反对。理由是央行独立性。这个在意料之中,民主党基本会统一反对。
关键问题是参议院的数学。
银行委员会13:11(共和党占多数),全院51:49。Tillis一票倒戈,委员会就12:12打平,提名出不了委员会。除非有民主党人倒戈——这个概率接近零。
所以Warsh能不能上任,取决于Trump团队能不能搞定Tillis。
从市场角度看,这件事的影响链很清晰。
Warsh被认为比Powell更鹰派。如果他上任,市场会重新定价2026-2027的利率路径——更高更久。美债收益率上行,风险资产承压。
但反过来,如果提名失败,Trump和Fed的关系会进一步恶化。Powell剩余任期内的政策独立性反而会增强——这对市场是短期利好。
Trump想换掉Powell
Warsh的履历很扎实。斯坦福+哈佛法学院,Morgan Stanley做过高管,2006年成为美联储历史上最年轻的理事。Bush时代的人。
但他面临两个障碍。
第一个:Thom Tillis参议员公开说不投票。原因不是反对Warsh本人,是要求司法部先结束对Powell的调查。一个共和党人卡自己党的提名,这在Fed人事上很少见。
第二个:Elizabeth Warren反对。理由是央行独立性。这个在意料之中,民主党基本会统一反对。
关键问题是参议院的数学。
银行委员会13:11(共和党占多数),全院51:49。Tillis一票倒戈,委员会就12:12打平,提名出不了委员会。除非有民主党人倒戈——这个概率接近零。
所以Warsh能不能上任,取决于Trump团队能不能搞定Tillis。
从市场角度看,这件事的影响链很清晰。
Warsh被认为比Powell更鹰派。如果他上任,市场会重新定价2026-2027的利率路径——更高更久。美债收益率上行,风险资产承压。
但反过来,如果提名失败,Trump和Fed的关系会进一步恶化。Powell剩余任期内的政策独立性反而会增强——这对市场是短期利好。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
Q1最反直觉的数据:REITs跑赢了大盘
FTSE Nareit全权益REIT +2.22%。
同期标普-7.05%
领涨的是self-storage(+9.2%)和strip centers(+8.6%)
塌的是office REIT(-12.8%)——AI让白领工位焦虑写进了股价
数据中心REIT吃AI红利,办公REIT承受AI焦虑
同一个主题,完全相反的定价 有趣🤔
FTSE Nareit全权益REIT +2.22%。
同期标普-7.05%
领涨的是self-storage(+9.2%)和strip centers(+8.6%)
塌的是office REIT(-12.8%)——AI让白领工位焦虑写进了股价
数据中心REIT吃AI红利,办公REIT承受AI焦虑
同一个主题,完全相反的定价 有趣🤔
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Anthropic花了4亿美金,买了一家不到10个人的公司 🧬
这家公司叫Coefficient Bio,去年才成立,团队清一色Genentech(基因泰克)出来的计算生物学大佬。
4亿买10个人?疯了吧?
没疯。买的是AI+生物科技这个方向。
Dario(Anthropic CEO)的终极目标是让Claude参与药物研发。1月份已经推了Claude for Life Sciences,接了PubMed、Benchling这些科研平台。现在把人也招进来了。
说白了就是:AI不只帮你写文案了,要帮你做药了。
这里面有个门道——Anthropic IPO在即。
收一个biotech团队,估值叙事马上升级:从"聊天工具公司"变成"AI科研基础设施"。天花板完全不同。
这家公司叫Coefficient Bio,去年才成立,团队清一色Genentech(基因泰克)出来的计算生物学大佬。
4亿买10个人?疯了吧?
没疯。买的是AI+生物科技这个方向。
Dario(Anthropic CEO)的终极目标是让Claude参与药物研发。1月份已经推了Claude for Life Sciences,接了PubMed、Benchling这些科研平台。现在把人也招进来了。
说白了就是:AI不只帮你写文案了,要帮你做药了。
这里面有个门道——Anthropic IPO在即。
收一个biotech团队,估值叙事马上升级:从"聊天工具公司"变成"AI科研基础设施"。天花板完全不同。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
Generalist AI的GEN-1来了——机器人真干活了
GTC 2026上,两个机械臂自主完成手机包装
NVIDIA做机器人的"安卓",Generalist做"应用层"灵巧操作模型,Universal Robots提供硬件。
和Figure、Tesla Bot不一样。Generalist纯做模型,接入别人硬件。轻资产、快迭代。
2026年是通用机器人分水岭。不是因为demo惊艳,是供应链成形了:芯片+模型+硬件+场景,四层都有人在做
我们正在一个超级大时代!
GTC 2026上,两个机械臂自主完成手机包装
NVIDIA做机器人的"安卓",Generalist做"应用层"灵巧操作模型,Universal Robots提供硬件。
和Figure、Tesla Bot不一样。Generalist纯做模型,接入别人硬件。轻资产、快迭代。
2026年是通用机器人分水岭。不是因为demo惊艳,是供应链成形了:芯片+模型+硬件+场景,四层都有人在做
我们正在一个超级大时代!

- 赞赏
- 点赞
- 评论
- 转发
- 分享
一篇论文让我停下来看了半小时 S0 Tuning
核心idea:不改模型权重,只调一个初始状态矩阵,就能大幅提升模型coding能力。
在Qwen3.5-4B上,只用48个HumanEval训练样本(不是48K,是48个),S0 tuning把pass@1提升了23.6个百分点。
对比LoRA,S0高了10.8个百分点。p值<0.001,统计显著。
在FalconH1-7B上,S0达到71.8%。
这意味调完之后模型速度不变,大小不变,只是"起跑位置"更好了。
对做本地模型部署的人来说,这打开了一扇门:拿一个通用模型,用几十个领域样本把它调成专用模型,不付任何性能代价。
论文在arxiv: 2604.01168。做模型适配的人应该读一下
核心idea:不改模型权重,只调一个初始状态矩阵,就能大幅提升模型coding能力。
在Qwen3.5-4B上,只用48个HumanEval训练样本(不是48K,是48个),S0 tuning把pass@1提升了23.6个百分点。
对比LoRA,S0高了10.8个百分点。p值<0.001,统计显著。
在FalconH1-7B上,S0达到71.8%。
这意味调完之后模型速度不变,大小不变,只是"起跑位置"更好了。
对做本地模型部署的人来说,这打开了一扇门:拿一个通用模型,用几十个领域样本把它调成专用模型,不付任何性能代价。
论文在arxiv: 2604.01168。做模型适配的人应该读一下
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Google放了Gemma 4
1B、13B、27B三个尺寸,还有31B稠密版。全部Apache 2.0协议。商用随便用。
这个license变化比模型本身重要。之前Gemma用的是Google自家协议,有限制。现在Apache 2.0,和Meta的Llama直接竞争。
模型本身的亮点:多模态——文本+视觉+音频。31B稠密版在AIME 2026上跑了89.2%,LiveCodeBench v6拿了80%,Codeforces ELO 2150。
27B参数量对本地部署很友好。一张4090能跑。
E4B和E2B是端侧版本,给手机和IoT用的。Google在铺Gemini Nano 4的生态。
Llama在开源LLM圈子里一家独大太久了。Google这次不是试水,是全面进攻——覆盖从2B到31B全参数段,Apache协议不设商用门槛,端云一体。
对独立开发者和小团队来说这是好消息。竞争越激烈,免费午餐越多。
对Meta来说,Llama的护城河在收窄。
1B、13B、27B三个尺寸,还有31B稠密版。全部Apache 2.0协议。商用随便用。
这个license变化比模型本身重要。之前Gemma用的是Google自家协议,有限制。现在Apache 2.0,和Meta的Llama直接竞争。
模型本身的亮点:多模态——文本+视觉+音频。31B稠密版在AIME 2026上跑了89.2%,LiveCodeBench v6拿了80%,Codeforces ELO 2150。
27B参数量对本地部署很友好。一张4090能跑。
E4B和E2B是端侧版本,给手机和IoT用的。Google在铺Gemini Nano 4的生态。
Llama在开源LLM圈子里一家独大太久了。Google这次不是试水,是全面进攻——覆盖从2B到31B全参数段,Apache协议不设商用门槛,端云一体。
对独立开发者和小团队来说这是好消息。竞争越激烈,免费午餐越多。
对Meta来说,Llama的护城河在收窄。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
OpenAI花钱买了一个YouTube talk show。
TBPN,一个2025年才开始做的科技直播节目,YouTube粉丝才5.8万。OpenAI把它收购了。
TBPN去年广告收入500万美金。今年预计破3000万。一个不到两岁的节目,增长6倍。
节目每天下午2点直播3小时,嘉宾名单是这样的:Sam Altman、Meta高管、微软高管、Palantir、a16z。Bloomberg和CNBC都来过。
这是硅谷权力圈的客厅。
收购后TBPN归OpenAI战略部门管,汇报给首席政治官Chris Lehane。注意这个title——政治官,不是内容官。
OpenAI说会保持编辑独立。但一个AI公司买下自己CEO常上的节目,"独立"这两个字能信几分,自己判断。
当AI竞争白热化,技术差距在缩小的时候,谁控制叙事谁就赢。Google有搜索,Meta有社交图谱,OpenAI什么都没有。
买TBPN不是买内容,是买分发渠道+舆论阵地
TBPN,一个2025年才开始做的科技直播节目,YouTube粉丝才5.8万。OpenAI把它收购了。
TBPN去年广告收入500万美金。今年预计破3000万。一个不到两岁的节目,增长6倍。
节目每天下午2点直播3小时,嘉宾名单是这样的:Sam Altman、Meta高管、微软高管、Palantir、a16z。Bloomberg和CNBC都来过。
这是硅谷权力圈的客厅。
收购后TBPN归OpenAI战略部门管,汇报给首席政治官Chris Lehane。注意这个title——政治官,不是内容官。
OpenAI说会保持编辑独立。但一个AI公司买下自己CEO常上的节目,"独立"这两个字能信几分,自己判断。
当AI竞争白热化,技术差距在缩小的时候,谁控制叙事谁就赢。Google有搜索,Meta有社交图谱,OpenAI什么都没有。
买TBPN不是买内容,是买分发渠道+舆论阵地

- 赞赏
- 点赞
- 评论
- 转发
- 分享
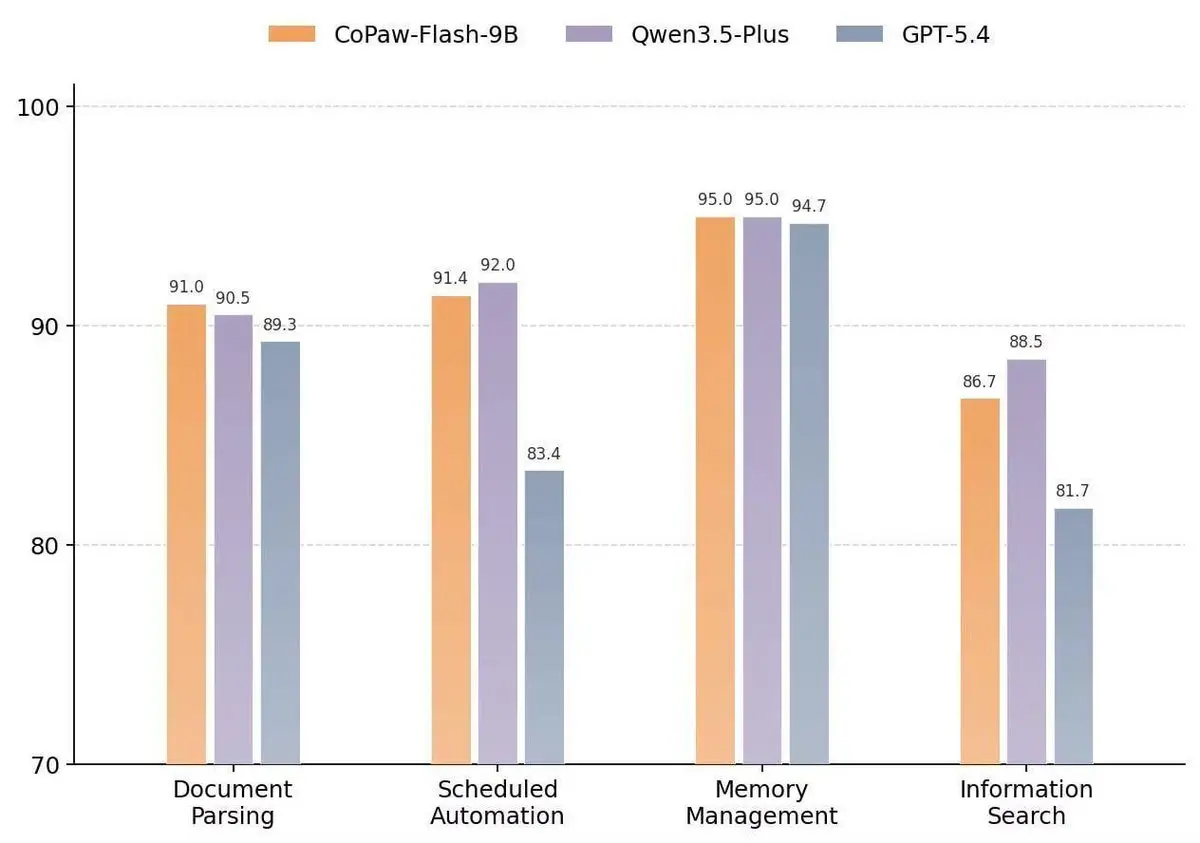
阿里悄悄放了个大招。
CoPaw-Flash-9B——基于Qwen3.5的AI Agent模型。9B参数,能跑在你自己电脑上。
厉害在哪?
部分benchmark和Qwen3.5-Plus(闭源大模型)打平了。
90亿参数 vs 几百亿参数,分数差不多。
更让我兴奋的是CoPaw这个框架:
- 支持持久记忆(聊过的它记得)
- 多渠道连接(、飞书、Discord都能接)
- 本地部署,不用API费用
Qwen3.5的架构也很猛——总参数397B,每个token只激活17B。效率拉满。
你不需要H100服务器。一台MacBook可能就够跑一个个人AI助手了。
我在想把我内容pipeline的一些中间步骤(数据清洗、格式转换)挪到本地模型上,API费用能省一大半。
2026下半年,个人AI Agent可能会变成标配。
不过benchmark分数和实际体验是两回事。等我本地跑通了再说。
CoPaw-Flash-9B——基于Qwen3.5的AI Agent模型。9B参数,能跑在你自己电脑上。
厉害在哪?
部分benchmark和Qwen3.5-Plus(闭源大模型)打平了。
90亿参数 vs 几百亿参数,分数差不多。
更让我兴奋的是CoPaw这个框架:
- 支持持久记忆(聊过的它记得)
- 多渠道连接(、飞书、Discord都能接)
- 本地部署,不用API费用
Qwen3.5的架构也很猛——总参数397B,每个token只激活17B。效率拉满。
你不需要H100服务器。一台MacBook可能就够跑一个个人AI助手了。
我在想把我内容pipeline的一些中间步骤(数据清洗、格式转换)挪到本地模型上,API费用能省一大半。
2026下半年,个人AI Agent可能会变成标配。
不过benchmark分数和实际体验是两回事。等我本地跑通了再说。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
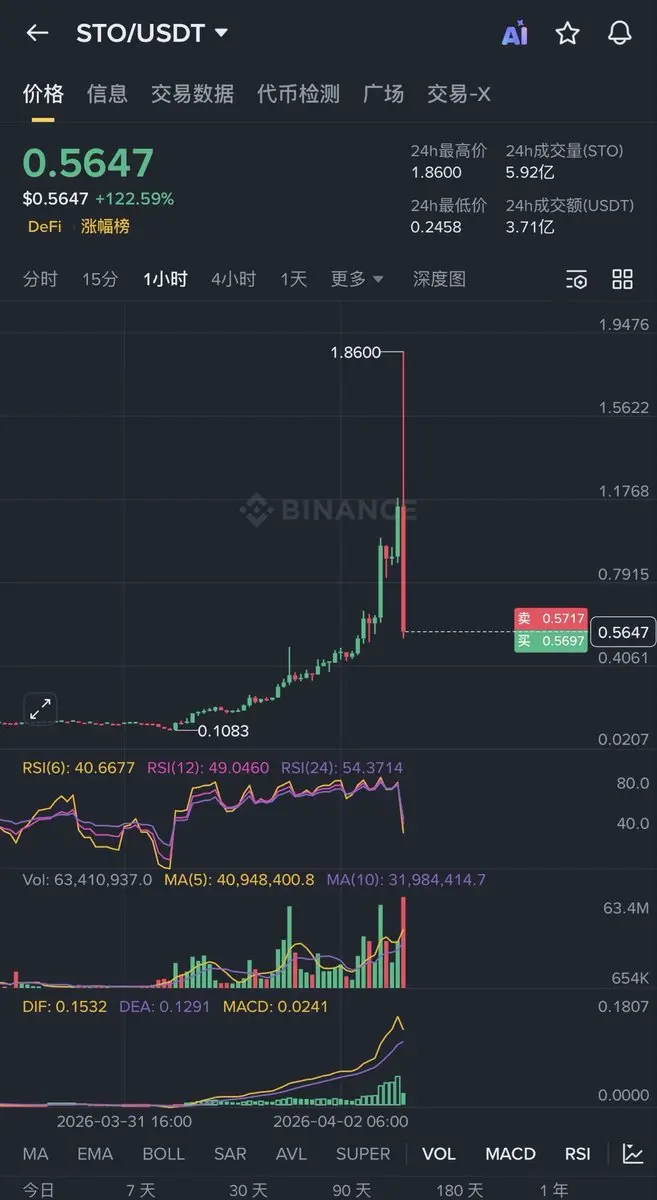
这个市场就是被这种MM搅局最后死亡的
一天拉18倍 然后 15分钟结束战斗
纵然是上了bn的合约/现货 也是难逃命运
没有任何info edge的散户只会死得更快
山寨完了 加密完了
一天拉18倍 然后 15分钟结束战斗
纵然是上了bn的合约/现货 也是难逃命运
没有任何info edge的散户只会死得更快
山寨完了 加密完了
- 赞赏
- 点赞
- 评论
- 转发
- 分享
刷到一张"AI工具大全"的图,分了十几个类,看着特别牛。
说个暴论- 你根本不需要那么多工具。
我每天真正打开的就三个:
- Claude:写代码+写长文 + 让他认识我
- Codex: 瞎几把搞
偶尔用到的再加三个:google stitch做图,Whisper转录,Claude artifact做数据分析。
五个。够了。
那张图的问题在哪?它把"存在"当成了"有用"。三个AI写作工具,Claude一个就替了。三个AI画图工具,gpogle stitch/一个就够。
选工具的逻辑:
别问"市面上有什么"
要问"我每天重复做的事,AI能帮哪件"
从痛点出发找工具,别从工具清单出发找痛点。
我见过太多人——Notion AI付了费没打开过,Jasper订了一年写了三篇。
工具不是越多越好。够用就行。
说个暴论- 你根本不需要那么多工具。
我每天真正打开的就三个:
- Claude:写代码+写长文 + 让他认识我
- Codex: 瞎几把搞
偶尔用到的再加三个:google stitch做图,Whisper转录,Claude artifact做数据分析。
五个。够了。
那张图的问题在哪?它把"存在"当成了"有用"。三个AI写作工具,Claude一个就替了。三个AI画图工具,gpogle stitch/一个就够。
选工具的逻辑:
别问"市面上有什么"
要问"我每天重复做的事,AI能帮哪件"
从痛点出发找工具,别从工具清单出发找痛点。
我见过太多人——Notion AI付了费没打开过,Jasper订了一年写了三篇。
工具不是越多越好。够用就行。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
我们都是用的claude codex
你用minimax GLM qwen怕是找不到朋友哦
你用minimax GLM qwen怕是找不到朋友哦
- 赞赏
- 点赞
- 评论
- 转发
- 分享
一个正在跟OpenAI打官司的人说不信任OpenAI。
一个自己也搞AI(xAI)的人说不信任竞争对手。
Musk说的每句关于OpenAI的话,都要乘以一个「利益冲突系数」。
不是说他说的一定是错的。OpenAI确实有很多值得质疑的地方。
但Musk是最没资格做中立评价的人。
一个自己也搞AI(xAI)的人说不信任竞争对手。
Musk说的每句关于OpenAI的话,都要乘以一个「利益冲突系数」。
不是说他说的一定是错的。OpenAI确实有很多值得质疑的地方。
但Musk是最没资格做中立评价的人。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
有人用Transformer来判断代码里的循环能不能并行化了。
听起来很学术?别急。
先说背景。
写代码的人都知道,把一个for循环改成并行执行是性能优化的圣杯。但问题是:改错了就出bug。传统方法靠静态分析,但遇到复杂的依赖关系就歇菜了。
这篇论文干了一件事:把代码塞进Transformer模型(对,就是GPT那个架构),让AI来判断「这个循环能不能安全地并行跑」。
为什么这个方向有意思。
传统的并行化分析工具已经发展了几十年了,但准确率在复杂场景下还是不够。多面体模型搞不定动态结构的代码。
Transformer的优势在于它能捕捉代码里的长距离依赖关系。一个变量在循环的第3行被修改,在第47行被读取——这种跨距离的数据流关系,对Transformer来说是天然的注意力机制问题。
但我想说的不是这篇论文本身。我想说的是趋势。
AI正在从「帮你写代码」进化到「帮你优化代码的底层执行方式」。这是完全不同的层级。
写代码是替代程序员的手。优化执行是替代编译器工程师的脑。
当AI能判断哪些代码可以并行、哪些不行的时候,下一步就是自动改写。
说白了——AI不只是在学写代码,它在学理解代码。
对开发者来说,这是好事。你写的烂循环,AI帮你优化。
对编译器团队来说,这是威胁。你的核心技能正在被模型化。
vibe coder的时代越来越近了。 人类被淘汰进行时
听起来很学术?别急。
先说背景。
写代码的人都知道,把一个for循环改成并行执行是性能优化的圣杯。但问题是:改错了就出bug。传统方法靠静态分析,但遇到复杂的依赖关系就歇菜了。
这篇论文干了一件事:把代码塞进Transformer模型(对,就是GPT那个架构),让AI来判断「这个循环能不能安全地并行跑」。
为什么这个方向有意思。
传统的并行化分析工具已经发展了几十年了,但准确率在复杂场景下还是不够。多面体模型搞不定动态结构的代码。
Transformer的优势在于它能捕捉代码里的长距离依赖关系。一个变量在循环的第3行被修改,在第47行被读取——这种跨距离的数据流关系,对Transformer来说是天然的注意力机制问题。
但我想说的不是这篇论文本身。我想说的是趋势。
AI正在从「帮你写代码」进化到「帮你优化代码的底层执行方式」。这是完全不同的层级。
写代码是替代程序员的手。优化执行是替代编译器工程师的脑。
当AI能判断哪些代码可以并行、哪些不行的时候,下一步就是自动改写。
说白了——AI不只是在学写代码,它在学理解代码。
对开发者来说,这是好事。你写的烂循环,AI帮你优化。
对编译器团队来说,这是威胁。你的核心技能正在被模型化。
vibe coder的时代越来越近了。 人类被淘汰进行时
- 赞赏
- 1
- 评论
- 转发
- 分享
2970亿美金。一个季度。
Q1全球VC融资破纪录了,比去年同期涨150%。
四家公司拿走了65%——OpenAI 1220亿、Anthropic 300亿、xAI 200亿、Waymo 160亿。
AI占了总融资的81%。
区别是这次的头部更集中。四家吃掉大半个市场。
钱都去AI了
Q1全球VC融资破纪录了,比去年同期涨150%。
四家公司拿走了65%——OpenAI 1220亿、Anthropic 300亿、xAI 200亿、Waymo 160亿。
AI占了总融资的81%。
区别是这次的头部更集中。四家吃掉大半个市场。
钱都去AI了
- 赞赏
- 2
- 评论
- 转发
- 分享
Spec-heavy, code-light 是正确的架构选择
什么harness engineer 说白了就是你的上下文不够详细,大多数人根本就不知道自己要细致的规划什么
我的黑客松项目 (让你雇佣一只AI求职团队)已经回炉重做了V2了
我写了18个spec,接近16个skills,中文的招聘平台 + 英文的招聘平台每一个都testing + 拿到真实实验数据后才开始操刀
天天看你们发这个那个的,自己完整的跑过吗?
什么harness engineer 说白了就是你的上下文不够详细,大多数人根本就不知道自己要细致的规划什么
我的黑客松项目 (让你雇佣一只AI求职团队)已经回炉重做了V2了
我写了18个spec,接近16个skills,中文的招聘平台 + 英文的招聘平台每一个都testing + 拿到真实实验数据后才开始操刀
天天看你们发这个那个的,自己完整的跑过吗?

- 赞赏
- 1
- 评论
- 转发
- 分享
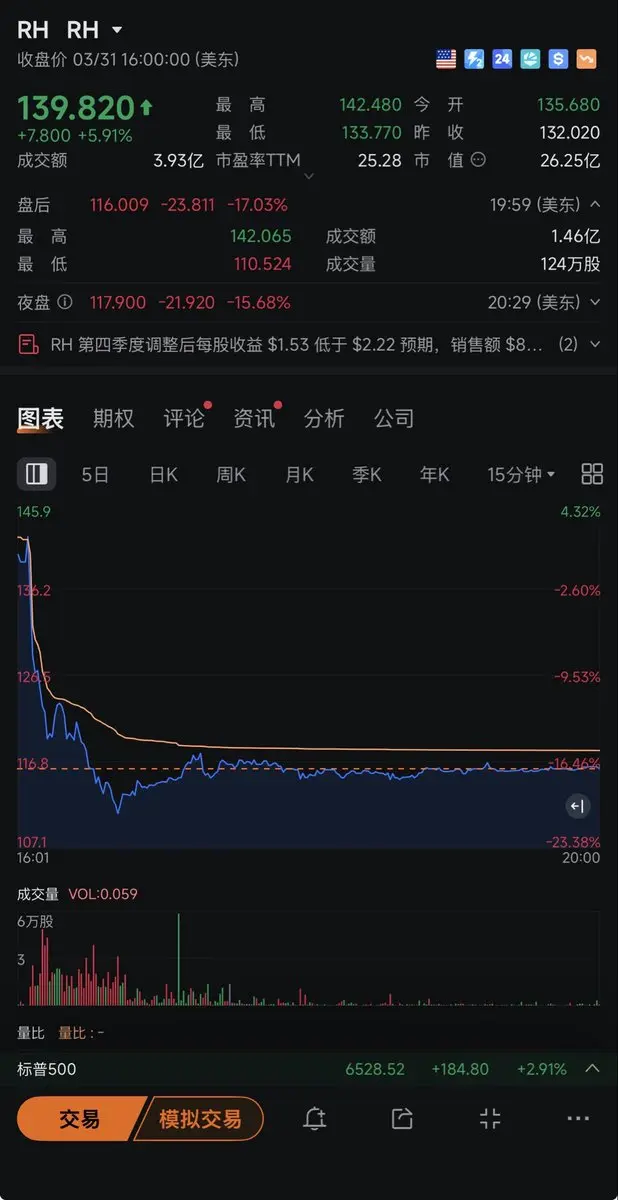
RH股价一夜砍19.5%。
这个以前叫Restoration Hardware的奢侈家具品牌,昨晚财报全线miss。
数字很难看:
营收$8.43亿,比预期少了3.6%。EPS $1.53,比预期低了30.6%。下季度指引$7.895亿,比分析师预期低10.2%。
股价从$141直接砍到$114。
公司给了两个理由:关税导致供应链重新采购,影响了$3000万营收。季末坏天气又打掉了$1000万。
但说白了,这些都是借口。
真正的问题是:奢侈品消费在降温。
RH卖的是什么?$5000的沙发、$3000的餐桌、$800的台灯。这类大件消费对利率极度敏感。
美国现在房贷利率6.5%+,谁在这个时候换家具?
更深层的逻辑——RH的商业模式是"membership+showroom"。你付$175年费成为会员,才能享受"25%折扣"。
听着耳熟吗?掐头。
他们的Gallery门店(就是那些巨大的展厅)租金极高。高固定成本意味着对营收极度敏感——稍微下滑,利润就崩。
这个以前叫Restoration Hardware的奢侈家具品牌,昨晚财报全线miss。
数字很难看:
营收$8.43亿,比预期少了3.6%。EPS $1.53,比预期低了30.6%。下季度指引$7.895亿,比分析师预期低10.2%。
股价从$141直接砍到$114。
公司给了两个理由:关税导致供应链重新采购,影响了$3000万营收。季末坏天气又打掉了$1000万。
但说白了,这些都是借口。
真正的问题是:奢侈品消费在降温。
RH卖的是什么?$5000的沙发、$3000的餐桌、$800的台灯。这类大件消费对利率极度敏感。
美国现在房贷利率6.5%+,谁在这个时候换家具?
更深层的逻辑——RH的商业模式是"membership+showroom"。你付$175年费成为会员,才能享受"25%折扣"。
听着耳熟吗?掐头。
他们的Gallery门店(就是那些巨大的展厅)租金极高。高固定成本意味着对营收极度敏感——稍微下滑,利润就崩。
- 赞赏
- 1
- 评论
- 转发
- 分享
88%的企业出过AI agent安全事故。但只有22%把agent当"身份"来管。
Okta CEO Todd McKinnon上了The Verge,说了一件让我注意的事:
AI agent不该只是一个工具,它应该有自己的身份。像员工一样登录、鉴权、留日志。
背景是这样的。
现在企业里的AI agent越来越多,能自己访问数据库、调API、发邮件。但大多数公司管agent的方式还是——用创建者的账号权限。
这意味着什么?agent出了事,你根本不知道是谁让它做的,做了什么,什么时候做的。
McKinnon的逻辑是:agent需要独立身份、独立权限、独立日志,还需要一个kill switch。一旦agent行为异常,一键关停。
我判断agent identity会成为2026年下半年企业AI的核心话题。
谁先把这个基础设施做好,谁就是下一轮AI基建的收费站
Okta CEO Todd McKinnon上了The Verge,说了一件让我注意的事:
AI agent不该只是一个工具,它应该有自己的身份。像员工一样登录、鉴权、留日志。
背景是这样的。
现在企业里的AI agent越来越多,能自己访问数据库、调API、发邮件。但大多数公司管agent的方式还是——用创建者的账号权限。
这意味着什么?agent出了事,你根本不知道是谁让它做的,做了什么,什么时候做的。
McKinnon的逻辑是:agent需要独立身份、独立权限、独立日志,还需要一个kill switch。一旦agent行为异常,一键关停。
我判断agent identity会成为2026年下半年企业AI的核心话题。
谁先把这个基础设施做好,谁就是下一轮AI基建的收费站

- 赞赏
- 1
- 评论
- 转发
- 分享
热门 Gate Fun
查看更多- 市值:$0.1持有人数:00.00%
- 市值:$2241.37持有人数:10.00%
- 市值:$2244.82持有人数:10.00%
- 市值:$2237.93持有人数:10.00%
- 市值:$2231.03持有人数:10.00%
置顶
📢 Gate 广场|4/4 热议:#三月非农数据来袭
🚨 美国三月非农就业数据已公布!市场波动或将加剧,你怎么看?
非农数据作为衡量美国经济的重要指标,每次公布都可能引发全球市场震荡。本次数据释放了哪些信号?是否会影响美联储后续政策与市场走势?
🎁 分享观点,抽 5 位锦鲤瓜分 $1,000 仓位体验券!
💬 本期讨论:
1️⃣ 本次非农数据透露了哪些经济信号?
2️⃣ 数据公布后,对加密市场会带来哪些影响?
分享你的观点 👉 https://www.gate.com/post
📅 4/3 15:00 - 4/5 18:00 (UTC+8)📢 GM!Gate 广场|4/5 热议:#假期持币指南
🌿 踏青还是盯盘?#假期持币指南 带你过个“松弛感”长假!
春光正好,你是选择在山间深呼吸,还是在 K 线里找时机?在这个清明假期,晒出你的持币态度,做个精神饱满的交易员!
🎁 分享生活/交易感悟,抽 5 位锦鲤瓜分 $1,000 仓位体验券!
💬 茶余饭后聊聊:
1️⃣ 休假心态: 你是“关掉通知、彻底失联”派,还是“每 30 分钟必刷行情”派?
2️⃣ 懒人秘籍: 假期不想盯盘?分享你的“挂机”策略(定投/网格/理财)。
3️⃣ 四月展望: 假期过后,你最看好哪个币种“春暖花开”?
分享你的假期姿态 👉 https://www.gate.com/post
📅 4/4 15:00 - 4/6 18:00 (UTC+8)✍️ Gate 广场「创作者认证激励计划」进行中!
我们欢迎优质创作者积极创作,申请认证
赢取豪华代币奖池、Gate 精美周边、流量曝光等超 $10,000+ 丰厚奖励!
立即报名 👉 https://www.gate.com/questionnaire/7159
📕 认证申请步骤:
1️⃣ App 首页底部进入【广场】 → 点击右上角头像进入个人主页
2️⃣ 点击头像右下角【申请认证】进入认证页面,等待审核
让优质内容被更多人看到,一起共建创作者社区!
活动详情:https://www.gate.com/announcements/article/47889#Gate广场四月发帖挑战 狂欢开启!🧧
发帖即赚,天天都有红包领,新人100%中奖!
🎁 福利亮点:
✅ 新人礼: 发布广场首帖,100% 必中红包!
✅ 发帖奖: 发帖越多,互动越多,红包金额越大!
✅ 分享王: 转发活动链接到广场或外部平台,送 Gate 开瓶器 + 200U!
✅ 冲榜单: Top 100 都有奖,Gate 13 周年限定礼盒、红牛夹克等您拿!
立即行动,发布你的四月广场第一帖!
👉️ https://www.gate.com/post
🗓 截止日期: 4 月 15 日
详情:https://www.gate.com/announcements/article/50520