Futures
Access hundreds of perpetual contracts
CFD
Gold
One platform for global traditional assets
Options
Hot
Mit Vanilla-Optionen im europäischen Stil handeln
Einheitliches Konto
Maximieren Sie Ihre Kapitaleffizienz
Demo-Handel
Einführung in den Futures-Handel
Bereiten Sie sich auf Ihren Futures-Handel vor
Futures Events
Join events to earn rewards
Demo-Handel
Nutzen Sie virtuelle Gelder um risikofreien Handel zu erleben
Launch
CandyDrop
Sammle Süßigkeiten, um Airdrops zu erhalten
Launchpool
Schnelles Staking, verdienen Sie potenziell neue Token
HODLer Airdrop
Halten Sie GT und erhalten Sie kostenlos massive Airdrops
IPO Access
Unlock full access to global stock IPOs
Alpha Points
Trade on-chain assets and earn airdrops
Punti Futures
Guadagna punti Futures e richiedi le ricompene dell'airdrop
Investition
Simple Earn
Earn interest with idle tokens
Automatisches Investieren
Investieren Sie regelmäßig automatisch
Dual Investment
Profit from market volatility
Sanftes Staking
Verdienen Sie Belohnungen mit flexiblem Staking
Krypto - Anleihe
0 Fees
Verpfänden Sie eine Kryptowährung, um eine andere auszuleihen
Lending-Center
One-Stop-Lending-Hub
Werbeaktionen
Activity Center
Participate in activities to earn rewards
Referral
20 USDT
Invite friends to earn referral rewards
Affiliate Program
Earn exclusive commission rewards
Gate Booster
Grow influence and earn airdrops
Announcements
Real-time platform updates
Gate-Blog
Artikel zur Kryptobranche
VIP-Dienste
Große Rabatte auf Gebühren
Asset Management
All-in-One-Lösung für die Verwaltung Ihrer Vermögenswerte
Institutional
Enterprise digital asset solutions
Developers (API)
Connects to the Gate application ecosystem
OTC-Banküberweisung
Fiat einzahlen und abheben
Maklerprogramm
Attraktive API-Rabattmechanismen
AI
Gate AI
Your all-in-one conversational AI partner
Gate AI Bot
Use Gate AI directly in your social App
GateClaw
Gate Blue Lobster, ready to go
Gate for AI Agent
Skills и CLI
Gate Skills Hub
10K+ Fähigkeiten
From office tasks to trading, the all-in-one skill hub makes AI even more useful.
GateRouter
Smartly choose from 40+ AI models, with 0% extra fees
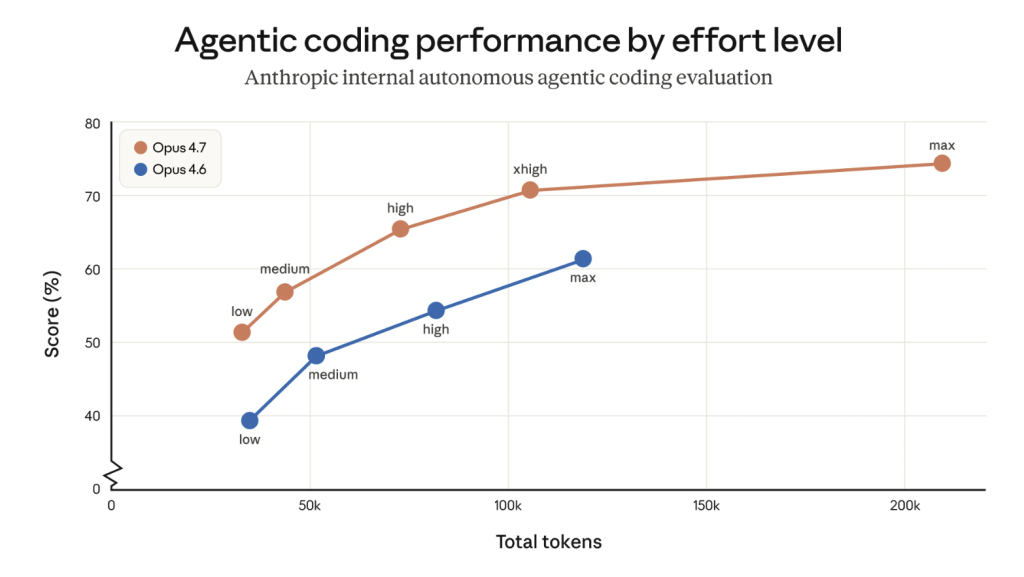 Anstieg des Tokenverbrauchs bei Opus 4.7. Quelle: Anthropic
Anstieg des Tokenverbrauchs bei Opus 4.7. Quelle: Anthropic