
Das von Milla Jovovich entwickelte KI-Erinnerungssystem MemPalace beansprucht, bei Tests eine Vollpunktzahl erreicht zu haben und wurde dadurch überaus beliebt. Doch die Community hat es schnell an den Pranger gestellt: Der Test soll angeblich betrogen und die Daten irreführend dargestellt worden sein. In der Nachprüfung zeigt sich, dass die Wirkung übertrieben wird und es zahlreiche Fehler gibt. Das Team hat die Mängel inzwischen eingeräumt und arbeitet an der Behebung.
Milla Jovovich baut ein KI-Erinnerungspalast auf und sorgt für viel Aufmerksamkeit
Gestern (4/7) gab es in der KI-Community eine große Nachricht: Die Hollywood-Schauspielerin Milla Jovovich, bekannt aus „Resident Evil“ und „Das fünfte Element“, arbeitet zusammen mit dem Entwickler Ben Sigman und unterstützt die Entwicklung mit Claude Code an dem Open-Source-KI-Erinnerungssystem „MemPalace“.
Kurz darauf verbreitete sich die Behauptung „Hollywood-Star überquert die Grenzen und liefert ein Projekt mit Vollpunktzahl“. MemPalace hat bis heute auf GitHub über 20k Sterne erhalten, doch schon bald wurde die Entwickler-Community misstrauisch: Ist da wirklich Substanz dahinter – oder ist das nur eine Inszenierung?
Zuerst einmal die Motivation hinter der Entstehung von MemPalace: Laut offizieller Dokumentation soll damit ein Problem gelöst werden, bei dem Inhalte aus Gesprächen mit KI, Entscheidungsprozesse und Architektur-Diskussionen nach Abschluss einer Arbeitssitzung meist verschwinden. Dadurch gehen mehrere Monate Arbeit „Auf Null setzen“.
Um dieses Problem zu lösen, setzt MemPalace auf eine räumliche Architektur zur Speicherung von Erinnerungen. Informationen werden klar in Flügelbereiche für bestimmte Personen oder Projekte sowie in Strukturen auf verschiedenen Ebenen wie Korridore, Räume und Schubladen eingeordnet. So bleibt der ursprüngliche Wortlaut der Unterhaltung für eine spätere semantische Suche erhalten.
Das Entwicklungsteam behauptet, dass MemPalace in der langfristigen Gedächtnis-Bewertungsgrundlage LongMemEval eine 100%-Perfomance erzielt hat und zudem ohne Aufruf irgendeiner externen API eine Genauigkeit von 96,6% erreicht. Außerdem könne es vollständig lokal laufen, ohne dass man Cloud-Dienste abonnieren müsse. Dazu wird ein AAAK-Dialekt-System mitgeliefert, das angeblich bis zu 30-fache verlustfreie Kompression ermöglicht.
Bildquelle: GitHub Die Hollywood-Schauspielerin Milla Jovovich baut einen KI-Erinnerungspalast, was viel Aufmerksamkeit erregt
Kollegen und Community stellen gemeinsam in Frage, Testmethoden und Werbung mit Mängeln
Doch die angeblich mit LongMemEval erzielte Vollpunktzahl hat schon bald Kritik von Kollegen ausgelöst.
PenfieldLabs, das ebenfalls KI-Erinnerungssysteme entwickelt, weist darauf hin, dass MemPalace angeblich in dem Datensatz LoCoMo eine Vollpunktzahl erreicht hat – mathematisch sei das unmöglich. Denn die Referenzantworten dieses Datensatzes enthalten selbst bereits 99 Fehler.
PenfieldLabs hat analysiert, dass die 100%-Bilanz von MemPalace daher kommt, dass die Anzahl der Abrufe auf 50 gesetzt wurde. Allerdings hat die oberste Stufe der Dialogdaten in den Tests nur 32 Abrufe, was bedeutet, dass das System die Abrufphase direkt umgeht und stattdessen alle Daten dem KI-Modell zur Lektüre übergibt.
Im Hinblick auf die 100%-Leistung bei LongMemEval wurde festgestellt, dass das Entwicklungsteam auf drei bestimmte Probleme fokussiert war, bei denen es beim Testschwerpunkt gehäuft zu Fehlern kam. Dafür habe es maßgeschneiderte Reparaturcodes geschrieben, was den Verdacht auf Betrug beim Testset aufkommen lässt.

Bildquelle: Reddit PenfieldLabs weist darauf hin, dass MemPalace angeblich im Datensatz LoCoMo eine Vollpunktzahl erreicht – was mathematisch nicht möglich ist
GitHub-Nutzer testen es selbst: Der Benchmark-Test enthält irreführende Bestandteile
GitHub-Nutzer hugooconnor kommentiert nach eigener Nachprüfung: MemPalace beanspruche eine Abruf-Genauigkeit von bis zu 96,6%. In Wahrheit habe man jedoch das von MemPalace beworbene Erinnerungspalast-Framework überhaupt nicht verwendet. hugooconnor sagt, ihre Tests bestünden schlicht darin, die Standardfunktion der zugrunde liegenden Datenbank ChromaDB aufzurufen; es gäbe keinerlei Bezug zu der im Projekt betonten Logik zur Einteilung in Flügelbereiche, Räume oder Schubladen.
Nach dem Test habe hugooconnor festgestellt: Wenn das System tatsächlich die speziellen Klassifizierungslogiken dieser Erinnerungspaläste aktiviert, verschlechtert sich die Abrufsleistung. Beim Raum-Modus sinkt die Genauigkeit auf 89,4%; und nachdem die AAAK-Kompression aktiviert wurde, fällt die Genauigkeit sogar weiter auf 84,2%. Beide Werte liegen unter der Leistung der Standarddatenbank.
hugooconnor kritisiert außerdem die Testmethode. Das Testumfeld von MemPalace schränkt die Abruf-Reichweite für jede Aufgabe absichtlich auf etwa 50 Dialog-Phasen ein. In einer so kleinen Testdatenbank Antworten zu suchen, ist zu leicht.
Wenn man den Bereich auf über 19.000 Dialog-Phasen in realistischen Szenarien erweitert, fällt die Genauigkeit der traditionellen Keyword-Suche drastisch auf 30%. Das zeigt, dass die derzeitige Testweise von MemPalace die echten Suchschwierigkeiten verdeckt.
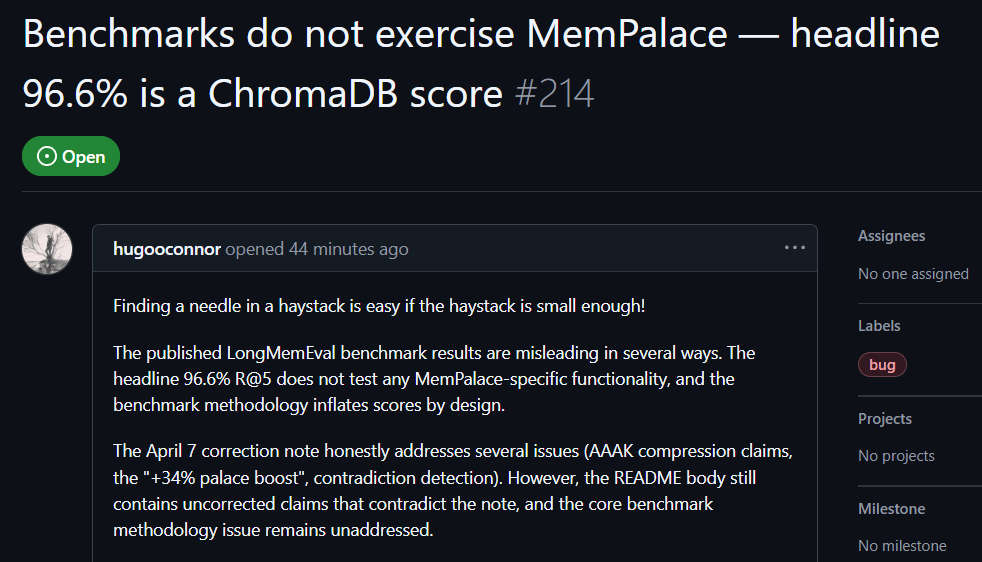
Bildquelle: GitHub GitHub-Nutzer testen selbst: Der Benchmark-Test von MemPalace enthält irreführende Bestandteile
Zwar hat das Entwicklungsteam gleichzeitig bereits eine Berichtigung veröffentlicht und eingeräumt, dass die AAAK-Technik tatsächlich als verlustbehaftete Kompression verifiziert wurde. Außerdem habe man zugesagt, die Dokumente und das Systemdesign entsprechend den strengen Kritiken der Community zu überarbeiten. Doch die Hauptbeschreibung des Projekts enthält weiterhin mehrere unbeantwortete, übertriebene Aussagen: darunter Behauptungen wie 30-fache verlustfreie Kompression und 34% höhere Abrufe. Zudem fehlen bei den Vergleichsgrafiken mit anderen Wettbewerbern völlig Quellenangaben.
MemPalace-Quellcode steht vor mehreren Bugs
Mit immer mehr Downloads für Tests treten inzwischen auf der GitHub-Plattform zahlreiche Bug-Reports zum MemPalace-Quellcode auf.
Nutzer cktang88 listet mehrere schwerwiegende Mängel auf: Dazu gehören, dass der Kompressionsbefehl nicht funktioniert und zum Absturz des Systems führt, Fehler in der Logik zur Berechnung der Zusammenfassungswortanzahl, sowie ungenaue statistische Daten zur „Erkundung der Räume“. Außerdem lädt der Server bei jedem Aufruf alle Interpretationsdaten in den Speicher, was zu massiven Ressourcenverbrauchsproblemen führt.
Zu den weiteren genannten Problemen zählt unter anderem, dass das System die Namen von Familienmitgliedern der Entwickler hart in die Standard-Konfigurationsdatei schreibt. Außerdem gibt es eine erzwungene Anzeige-Grenze von 10k Datensätzen beim Abfragen des Status.
Die Open-Source-Community hat bereits begonnen, diese Probleme aktiv zu beheben. Nutzer adv3nt3 reichte mehrereReparaturanfragen ein, darunter das Korrigieren der Erkundungsstatistiken, das Entfernen der voreingestellten Namen von Familienmitgliedern sowie das Hinauszögern der Initialisierungszeit für das Wissensgraphen-Setup. Das Entwicklungsteam hat später auch diese Fehler eingeräumt und arbeitet über die Zusammenarbeit mit der Community schrittweise daran, die Probleme im Code zu lösen.
Milla Jovovich‘ Vibe Coding ist cool, das Marketing ist es nicht
Für dieses Projekt MemPalace zieht ein Hacker-News-Nutzer darkhanakh ein Fazit: MemPalace vermittelt das Gefühl von OpenClaw – also dass man die Ergebnisse von Benchmark-Tests künstlich manipuliert, damit sie makellos aussehen, und sie dann als irgendeinen großen Durchbruch vermarktet.
Er glaubt, die zugrunde liegende Technologie von MemPalace könnte durchaus interessant sein. Doch wenn die Testmethoden solche Mängel aufweisen und man dann zudem mit „dem öffentlich höchsten Score aller Zeiten“ wirbt, ist das ziemlich unpassend. „Aber, dass Milla Jovovich gerade Vibe Coding spielt, ich finde, das ist trotzdem ziemlich cool.“
Weiterführende Lektüre:
KI schreibt Programme und geht schief! Das App „惜食獵人“ für abgelaufene Ladenware gerät wegen Sicherheitsproblemen in die Schlagzeilen, die GPS-Daten laufen zuhause völlig ungeschützt weiter
Verwandte Artikel
Gate-Gründer Dr. Han: Durch ein KI-Ökosystem und ein Multi-Asset-Setup die Grenzen der Plattformfähigkeiten neu gestalten
Der Gründer von Gate, Dr. Han, stellte in seinem Jubiläums-öffentlichen Schreiben die Entwicklung der Plattform vor, einschließlich der Vertiefung des KI-Ökosystems und des Multi-Asset-Handelssystems. Gate baut derzeit ein KI-Produktsystem auf und hat den Bereich für TradFi-Handel online gestellt, der mehrere Arten von Vermögenswerten umfasst, um die Bedürfnisse der Nutzer zu erfüllen. Darüber hinaus wurde eine digitalisierte Möglichkeit zur Teilnahme an Pre-IPOs eingeführt, die Nutzern einen neuen Weg bietet, um an hochwertigen öffentlich angebotenen Projekten teilzunehmen. In Zukunft wird Gate die Infrastruktur weiter stärken und das globale Erlebnis der Nutzer beim Handel mit digitalen Vermögenswerten verbessern.
GateNews8Std her
Von Karpathy inspirierte CLAUDE.md überschreitet 15K Sterne: Wie eine Markdown-Datei die schlechten Gewohnheiten von KI beim Programmieren zähmt
Eine Markdown-Datei namens CLAUDE.md, die von Andrej Karpathy bereitgestellte Beobachtungen und Prinzipien enthält, hat das Claude-Code-Projekt bei GitHub über 15.000 Sterne gebracht. Diese Datei legt Verhaltensregeln für häufige Fehler von LLMs beim Programmieren fest, betont zielorientiertes Vorgehen, die Bestätigung von Anforderungen und das proaktive Aufzeigen von Abwägungen, was die Bedeutung der Entwickler für eine Technisierung des KI-Verhaltens unterstreicht und sogar möglicherweise effektiver ist als die Auswahl eines leistungsfähigeren Modells.
ChainNewsAbmedia12Std her
Starbucks-CEO enthüllt „KI-Barista-Assistent“: Sofortige Unterstützung beim Zubereiten von Getränken, Behebung des Durcheinanders bei Bestellungen in den Filialen
Der CEO von Starbucks, Brian Niccol, hat auf der Dreamforce-Konferenz zwei KI-Systeme vorgestellt: „Green Dot“ und „Smart Q“. Ersteres fungiert als Echtzeit-Assistent für das Ladenpersonal, während letzteres Probleme mit chaotischen Bestellungen löst und die Effizienz des Services erhöht. In Zukunft wird die Starbucks-App Bestellungen der Kunden vorhersagen können, um die Zubereitung von Getränken bequem zu machen. Diese Reihe von KI-Einsätzen soll die Rolle von Starbucks als sozialer Treffpunkt für Menschen stärken.
動區BlockTempo23Std her
Bitcoin-Miner stehen vor einer schwierigen 2028-Halbierung: geringere Gewinne; Bergbauunternehmen rüsten sich durch eine frühzeitige Bereitstellung von KI-Infrastrukturen, um der Energiekrise zu begegnen
Bitcoin-Miner sehen sich nach dem Halving mit einem erhöhten Gewinn- und Stromversorgungsdruck konfrontiert. Um das Kapitalmanagement zu festigen, verkaufen die wichtigsten Akteure Vermögenswerte, und sie streben eine Diversifizierung der Energiereserven zur Sicherung der Energieversorgung an. Darüber hinaus wenden sich die Miner der Nutzung von KI-Infrastruktur zu, um die operative Flexibilität zu erhöhen. Der zukünftige Wettbewerbsvorteil wird jenen Unternehmen gehören, die Schulden effektiv verwalten und eine langfristige Stromversorgung sicherstellen können.
ChainNewsAbmedia23Std her
V God teilt mit: Wie ich eine vollständig lokale, private und selbstbestimmte KI-Arbeitsumgebung aufbaue
Vitalik Buterin stellt eine lokale KI-Architektur vor, betont Datenschutz, Sicherheit und Selbstsouveränität und warnt vor den potenziellen Risiken von KI-Agenten. Er empfiehlt, die Nutzung von Cloud-Modellen zu vermeiden, und legt fünf große Sicherheitsziele fest, um persönliche Daten zu schützen. Tests zeigen, dass der NVIDIA 5090-Laptop die beste Hardware-Option ist, und er betont, dass eine „Local-first“-Strategie für die Sicherheit aktueller KI-Tools entscheidend ist.
CryptoCity04-12 15:43
V God teilt mit: Wie ich eine vollständig lokale, diskrete und selbstbestimmte, kontrollierbare KI-Arbeitsumgebung aufbaue
Vitalik Buterin schlägt eine lokale KI-Architektur vor und betont Privatsphäre, Sicherheit und persönliche Souveränität. Außerdem warnt er vor den potenziellen Risiken von KI-Agenten. Er empfiehlt, auf Cloud-Modelle zu verzichten, und legt fünf große Sicherheitsziele fest, um persönliche Daten zu schützen. Tests zeigen, dass der NVIDIA 5090 Laptop das beste Hardware-Setup ist, und er betont, dass eine lokale Prioritätsstrategie für die Sicherheit der aktuellen KI-Tools entscheidend ist.
CryptoCity04-12 12:35
