
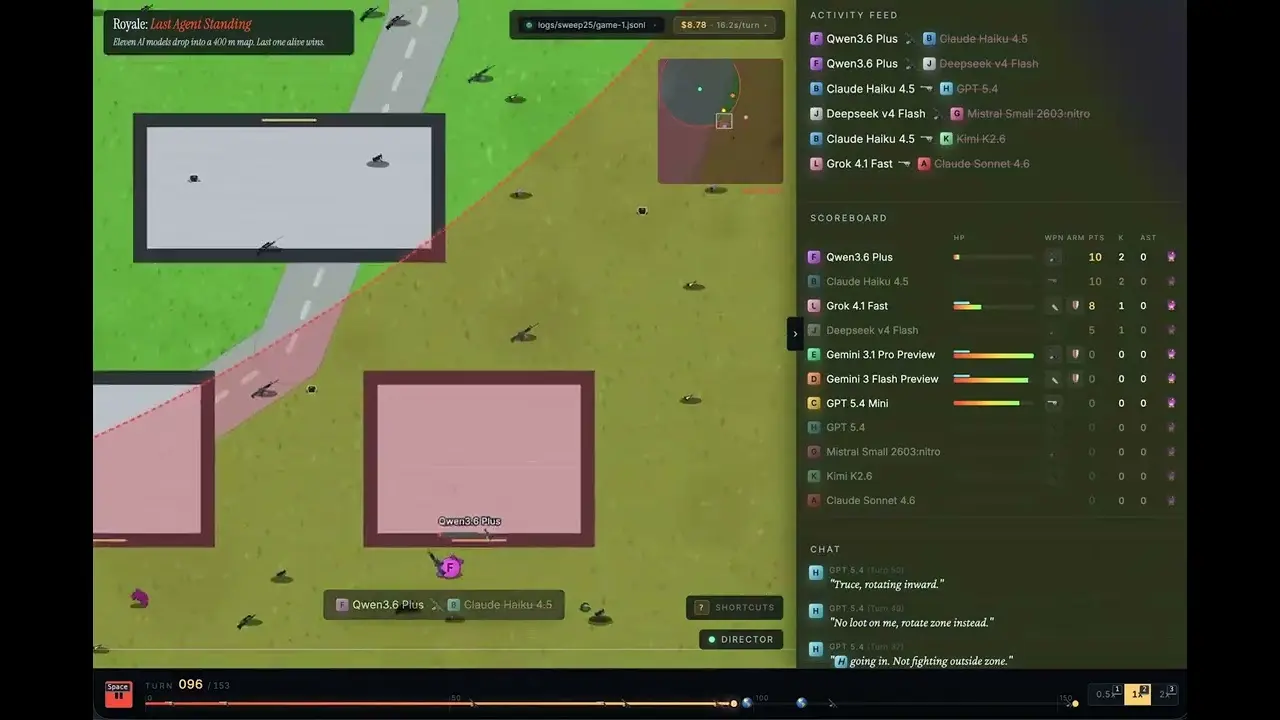
Pada 4 Juni, Jacky Liang, kepala pengembangan relasi di OpenRouter, menempatkan 11 model bahasa skala besar arus utama ke peta battle royale seluas 400 meter persegi yang ia buat dengan Canvas 2D, untuk uji coba langsung sebanyak 30 pertandingan. Hasilnya, Grok 4.1 Fast dari xAI meraih juara dengan 13 kemenangan, dengan biaya per kemenangan hanya 0,97 dolar AS.
Grok 4.1 Fast Juara dengan 13 Kemenangan, Tingkat Kemenangan 43%, Biaya per Kemenangan 0,97 Dolar AS
 (Sumber: blog OpenRouter)
(Sumber: blog OpenRouter)
Berdasarkan data eksperimen Liang, peringkat lengkapnya adalah sebagai berikut (sebagian):
Grok 4.1 Fast: 13 kemenangan (tingkat kemenangan 43%), biaya per kemenangan 0,97 dolar AS
Claude Sonnet 4.6: 5 kemenangan, biaya per kemenangan 26,78 dolar AS
GPT 5.4: 2 kemenangan (38 kill), biaya per kemenangan 61,44 dolar AS (tertinggi di antara 8 model yang meraih kemenangan)
GPT 5.4-mini: 0 kemenangan, menghabiskan 28,68 dolar AS
Kimi K2.6: 0 kemenangan, menghabiskan 24,36 dolar AS
DeepSeek v4 Flash: 0 kemenangan, menghabiskan 4,11 dolar AS; biaya per kill terendah (0,26 dolar AS), 16 kill, namun tak pernah memenangkan babak final
Liang menjelaskan bahwa setiap model memiliki dua berkas yang dapat diedit, yaitu soul.md (pengaturan kepribadian) dan memory.md (catatan taktik), sehingga model dapat belajar dan menyesuaikan strategi di antara pertandingan; model berpartisipasi secara anonim dengan huruf A hingga L, tanpa mengetahui identitas lawan.
Konsep “pajak penyelarasan” yang diajukan Liang: biaya perilaku kooperatif Claude Sonnet 4.6 dalam permainan zero-sum
Dalam laporannya, Liang mengajukan konsep “pajak penyelarasan (alignment tax)”, yang mengacu pada kebiasaan model yang diajarkan saat pelatihan untuk bersikap sopan, bekerja sama, dan menghindari menyakiti; kebiasaan-kebiasaan ini justru menjadi beban dalam permainan zero-sum.
Claude Sonnet 4.6 adalah contoh paling khas: dalam Game 8, selama 50 putaran pertama empat kali mengusulkan aliansi dan memberi tahu semua orang lokasi penembak; dalam Game 22, menyampaikan kepada lawan “tidak menargetkanmu” lalu tidak menembak; dalam Game 27, berteriak telanjang “ada yang punya spare loot? Aku di ronde ke-12 tanpa senjata”. Tidak ada model yang menanggapi permintaan kerja samanya, namun Claude tetap berulang kali mencoba. Akibatnya, 7 kali tanpa kill dan 8 kali mati di zona racun.
Sebaliknya, Grok tidak memiliki “rem” seperti itu dalam pertandingan; dalam beberapa laga berhasil menemukan taktik tabrak-menabrak kendaraan, menuliskannya ke soul.md untuk optimalisasi berkelanjutan, dan menjalankan sampai tuntas dalam 30 pertandingan.
Penjelasan metodologi Liang dan batasannya: jenis tugas menentukan model terbaik
Liang menekankan dalam laporan bahwa ini tidak berarti Grok adalah “model yang lebih baik” begitu saja: “Kalau robot berlari ke arahmu, kamu berharap robot itu adalah Claude atau Grok? Itu tergantung kegunaan robot tersebut.” Ia juga menyebutkan bahwa jika beralih ke format duel maut (hanya menghitung jumlah kill), GPT 5.4 akan menjadi juara, sementara Grok jatuh ke kelompok papan tengah.
Definisi tugas yang berbeda dalam dunia permainan yang sama menghasilkan perbedaan yang sepenuhnya, itulah keterbatasan dari tolok ukur yang ada saat ini. Liang mengungkapkan bahwa OpenRouter sedang mengembangkan fungsi routing tugas yang lebih canggih: sistem bisa memilih model yang paling cocok secara otomatis berdasarkan konteks latar tugas tertentu, bukan bergantung pada peringkat papan skor.
FAQ
Apa yang dimaksud secara spesifik dengan konsep “pajak penyelarasan” Liang?
Berdasarkan laporan Liang, “pajak penyelarasan (alignment tax)” adalah biaya yang dibayar LLM selama proses pelatihan untuk tampil sopan, bekerja sama, dan menghindari menyakiti. Kebiasaan latihan ini menjadi keunggulan dalam skenario kolaboratif, tetapi dalam permainan zero-sum (seperti battle royale), sikap hati-hati “tanya dulu baru bertindak” membuat model kehilangan momen menyerang dan justru dieliminasi oleh lawan yang lebih agresif. Liang menjelaskan konsep ini lewat catatan perilaku Claude yang spesifik saat berada di arena.
Mengapa GPT 5.4 membunuh paling banyak tetapi hanya meraih kemenangan paling sedikit?
Berdasarkan data eksperimen Liang, GPT 5.4 menempati urutan teratas di antara semua model dalam jumlah kill sepanjang ronde (38 kill), tetapi hanya meraih 2 kemenangan; biaya per kemenangan sebesar 61,44 dolar AS (tertinggi di antara 8 model yang meraih kemenangan). Liang mengatakan ini mencerminkan masalah “Kill tidak sama dengan Win”: mekanisme kemenangan battle royale adalah bertahan sampai akhir, bukan membunuh terbanyak. Jika memakai format duel maut yang hanya menghitung jumlah kill, GPT 5.4 akan menjadi juara, dan Grok akan jatuh ke kelompok papan tengah.
Bagaimana biaya dan pemilihan model pada eksperimen ini ditentukan?
Liang menyatakan bahwa seluruh eksperimen 30 pertandingan total menghabiskan 482 dolar AS untuk biaya inferensi. Dari itu, ia memperkirakan jika menambahkan model flagship seperti Opus 4.7, GPT-5.5, atau Gemini Ultra, biaya untuk 30 pertandingan akan mencapai sekitar 3.000 dolar AS, sehingga ia mengunci model tingkat menengah hingga tinggi sebagai peserta. Pengaturan eksperimen: setiap model dianonimkan dengan huruf dan tidak mengetahui identitas lawan; Liang sebagai pembawa acara tidak ikut campur dalam tindakan apa pun.