Первоисточник: AIGC Open Community
 Источник изображения: Generated by Unbounded AI
Источник изображения: Generated by Unbounded AI
В связи с появлением Transformer способность больших языковых моделей, таких как ChatGPT, обрабатывать задачи на естественном языке была значительно улучшена. Тем не менее, сгенерированный контент содержит много неверной или устаревшей информации, и отсутствует система фактической оценки для проверки подлинности контента.
Для того, чтобы всесторонне оценить адаптивность больших языковых моделей к изменениям в мире и аутентичность контента, исследовательская группа Google AI опубликовала статью под названием «Повышение точности больших языковых моделей с помощью знаний поисковых систем». Предложен метод FRESH для повышения точности больших языковых моделей, таких как ChatGPT и Bard, за счет получения информации в режиме реального времени от поисковых систем.
Исследователи сконструировали новый набор вопросов и ответов FRESHQA, который содержит 600 реальных вопросов различных типов, а частота ответов разделена на четыре категории: «никогда не меняться», «медленно меняться», «часто меняться» и «ложные предпосылки»**.
При этом также разработаны два метода оценивания: строгий режим, требующий, чтобы вся информация в ответах была точной и актуальной, и нестрогий режим, который оценивает только правильность основных ответов.
Результаты экспериментов показывают, что FRESH значительно повышает точность больших языковых моделей на FRESHQA. Например, GPT-4 на 47% точнее, чем оригинальный GPT-4 благодаря строгому режиму FRESH.
Кроме того, этот метод слияния поисковых систем является более гибким, чем прямое расширение параметров модели, и может обеспечить динамический внешний источник знаний для существующих моделей. Результаты эксперимента также показывают, что FRESH может значительно повысить точность больших языковых моделей на задачах, требующих знаний в реальном времени.
Адрес доклада:
Адрес с открытым исходным кодом: Big Language Model S/FreshQA (в разработке, скоро будет с открытым исходным кодом)
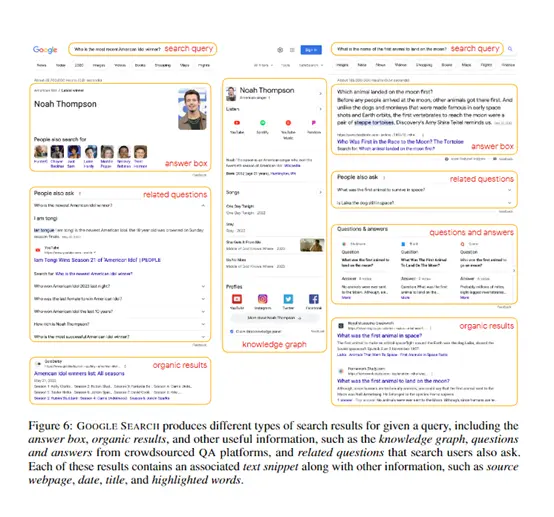 Судя по содержанию статьи Google, метод FRESH в основном состоит из 5 модулей.
Судя по содержанию статьи Google, метод FRESH в основном состоит из 5 модулей.
Сборка набора тестов FRESHQA
Для того, чтобы всесторонне оценить адаптивность больших языковых моделей к изменяющемуся миру, исследователи сначала построили бенчмарк-набор FRESHQA, который содержит 600 реальных вопросов открытого доступа, которые можно разделить на четыре категории в зависимости от частоты изменения ответов: «никогда не меняться», «медленно меняться», «часто меняться» и «ложные предпосылки».
-
Никогда не меняться: ответ на вопросы, который в принципе не изменится.
-
Медленные изменения: Ответ на вопрос меняется каждые несколько лет.
-
Частые изменения: ответы на вопросы, которые могут меняться каждый год или реже.
-
Неверная посылка: Задача, содержащая неверную посылку.
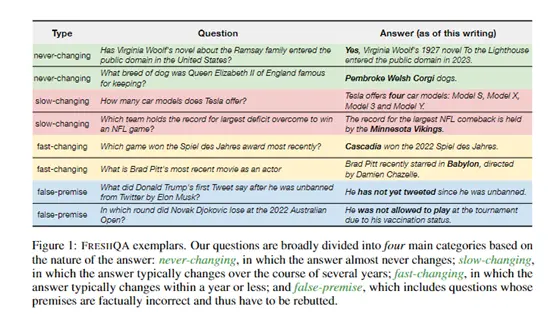 Вопросы охватывают самые разные темы и имеют разный уровень сложности. Ключевая особенность FRESHQA заключается в том, что ответ может меняться со временем, поэтому модель должна быть чувствительной к изменениям в мире.
Вопросы охватывают самые разные темы и имеют разный уровень сложности. Ключевая особенность FRESHQA заключается в том, что ответ может меняться со временем, поэтому модель должна быть чувствительной к изменениям в мире.
Строгий режим и расслабленный режим
Исследователи предложили два режима оценивания: строгий режим, который требует, чтобы вся информация в ответах была точной и актуальной, и нестрогий режим, который оценивает только правильность основных ответов.
Это обеспечивает более полный и детальный способ измерения фактической природы языковых моделей.
Оценка различных больших языковых моделей на основе FRESHQA
На FRESHQA исследователи сравнили большие языковые модели, охватывающие различные параметры, включая GPT-3, GPT-4, ChatGPT и другие. Оценивание проводится как в строгом режиме (требуется безошибочный), так и в разрешительном режиме (оцениваются только первичные ответы).
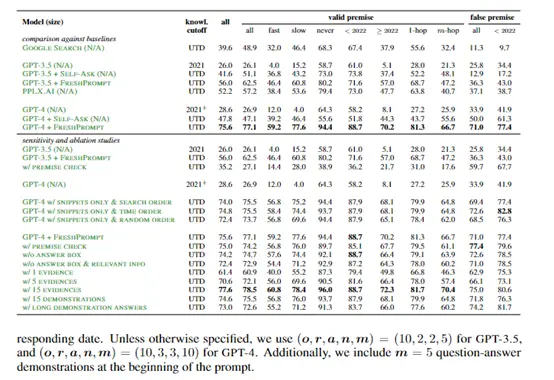 Установлено, что все модели плохо справляются с задачами, требующими знаний в реальном времени, особенно с задачами с частыми изменениями и некорректными посылками. Это показывает, что нынешняя большая языковая модель имеет ограничения в своей адаптивности к меняющемуся миру.
Установлено, что все модели плохо справляются с задачами, требующими знаний в реальном времени, особенно с задачами с частыми изменениями и некорректными посылками. Это показывает, что нынешняя большая языковая модель имеет ограничения в своей адаптивности к меняющемуся миру.
Получение релевантной информации из поисковых систем
Чтобы улучшить фактическую природу большой языковой модели, основная идея FRESH заключается в извлечении информации о проблеме из поисковой системы в режиме реального времени.
 В частности, получив вопрос, FRESH будет запрашивать поисковую систему Google в качестве ключевого слова, чтобы получить несколько типов результатов поиска, включая поля ответов, результаты веб-страницы, «другие пользователи также спрашивали» и т. д.
В частности, получив вопрос, FRESH будет запрашивать поисковую систему Google в качестве ключевого слова, чтобы получить несколько типов результатов поиска, включая поля ответов, результаты веб-страницы, «другие пользователи также спрашивали» и т. д.
Извлечение информации с помощью интеграции с разреженным обучением
FRESH использует обучение с несколькими выстрелами для интеграции полученных доказательств во входную подсказку модели на большом языке в унифицированном формате и предоставляет несколько демонстраций того, как синтезировать доказательства для получения правильного ответа.
Это может научить большие языковые модели понимать задачу и интегрировать информацию из разных источников, чтобы придумывать актуальные и точные ответы.
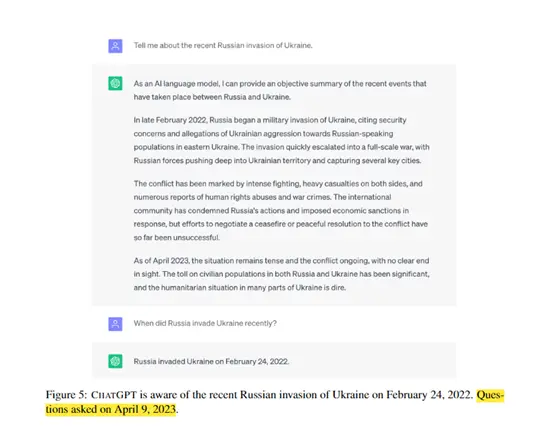 В Google заявили, что FRESH имеет большое значение для улучшения динамической адаптивности больших языковых моделей, что также является важным направлением для будущих технологических исследований больших языковых моделей.
В Google заявили, что FRESH имеет большое значение для улучшения динамической адаптивности больших языковых моделей, что также является важным направлением для будущих технологических исследований больших языковых моделей.

Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.
