Khi khối lượng công việc suy luận phát triển từ các cụm thử nghiệm sang ứng dụng thực tế trong doanh nghiệp, giải pháp tối ưu mặc định không còn là "mọi thứ đều tập trung tại trung tâm dữ liệu siêu lớn." Bài viết này phân tích logic phân tầng của các node biên, trung tâm dữ liệu khu vực và cụm trung tâm từ góc nhìn độ trễ, băng thông, khả dụng và tuân thủ. Bài viết giải thích các điểm chính về phân chia nhiệm vụ, ranh giới dữ liệu và quản trị vận hành trong cấu trúc lai, đồng thời cung cấp cái nhìn tổng quan so sánh với chuỗi hạ tầng AI rộng hơn.
Các quan điểm phổ biến thường đồng nhất sức mạnh băm AI với "trung tâm dữ liệu siêu lớn cộng GPU cao cấp." Đối với đào tạo và một số kịch bản suy luận tập trung, định nghĩa này thường phù hợp. Hạ tầng AI có các yêu cầu suy luận phân tán rộng, nhạy cảm với độ trễ và yêu cầu dữ liệu phải nằm trong phạm vi, trong khi gián đoạn mạng hoặc tắc nghẽn cao điểm là không thể chấp nhận. Trong các trường hợp này, cấu trúc suy luận trở thành vấn đề hạ tầng: sức mạnh băm không chỉ cần khả dụng mà còn phải đặt đúng "vị trí địa lý và tầng mạng phù hợp."
Nếu hạ tầng AI được xem là một chuỗi liên tục, kéo dài từ cấp chip lên đến dịch vụ và quản trị, bài viết này tập trung vào cấu trúc và hình thức triển khai: cách phân bổ sức mạnh tính toán và dữ liệu giữa các tầng biên, khu vực và trung tâm để cân bằng độ trễ, chi phí, khả dụng và tuân thủ. Các chủ đề thượng nguồn như điện, đóng gói và HBM thích hợp cho thảo luận phía cung, còn chi tiết định tuyến đa mô hình cấp doanh nghiệp và quản trị agent bổ sung cho vận hành sản xuất.
Tại sao cần bàn về "cấu trúc suy luận phân tán"
Suy luận tập trung mang lại vận hành thống nhất, mở rộng linh hoạt và tận dụng tài nguyên cao. Tuy nhiên, khi doanh nghiệp có bất kỳ đặc điểm nào sau đây, quyết định cấu trúc sẽ ảnh hưởng lớn đến trải nghiệm và chi phí:
-
Ràng buộc độ trễ mạnh: Điều khiển công nghiệp, tương tác thời gian thực, liên kết âm thanh/hình ảnh và địa điểm bán lẻ ngoại tuyến đều nhạy cảm với độ trễ cuối; đường trả về quá dài làm tăng dao động.
-
Chủ quyền và lưu trú dữ liệu: Các kịch bản như thông tin cá nhân, giao dịch tài chính, dịch vụ chính phủ và y tế thường yêu cầu dữ liệu phải nằm trong phạm vi, trong biên giới hoặc khu vực chỉ định.
-
Băng thông trả về và chi phí: Các điểm cuối lớn liên tục tải lên dữ liệu thô về suy luận tập trung, khiến phí mạng backbone và egress trở thành yếu tố chi phí chính.
-
Khả dụng và phục hồi: Khi xảy ra lỗi mạng diện rộng, biến động DNS hoặc tắc nghẽn liên vùng, kiến trúc hoàn toàn tập trung dễ gặp rủi ro "mất khả dụng toàn site."
-
Ngoại tuyến hoặc mạng yếu: Các môi trường như mỏ, tàu, và một số nhà máy yêu cầu khả năng vận hành tại chỗ, không phụ thuộc mạnh vào kết nối trực tuyến thời gian thực.
Những thách thức này không thể giải quyết đơn giản bằng "mô hình trung tâm mạnh hơn," bởi vấn đề cốt lõi nằm ở khoảng cách vật lý, đường mạng và ranh giới chính sách — không phải ở sức mạnh băm cực đại của một suy luận duy nhất.
Triển khai phân tầng: các tầng biên, khu vực và trung tâm giải quyết gì
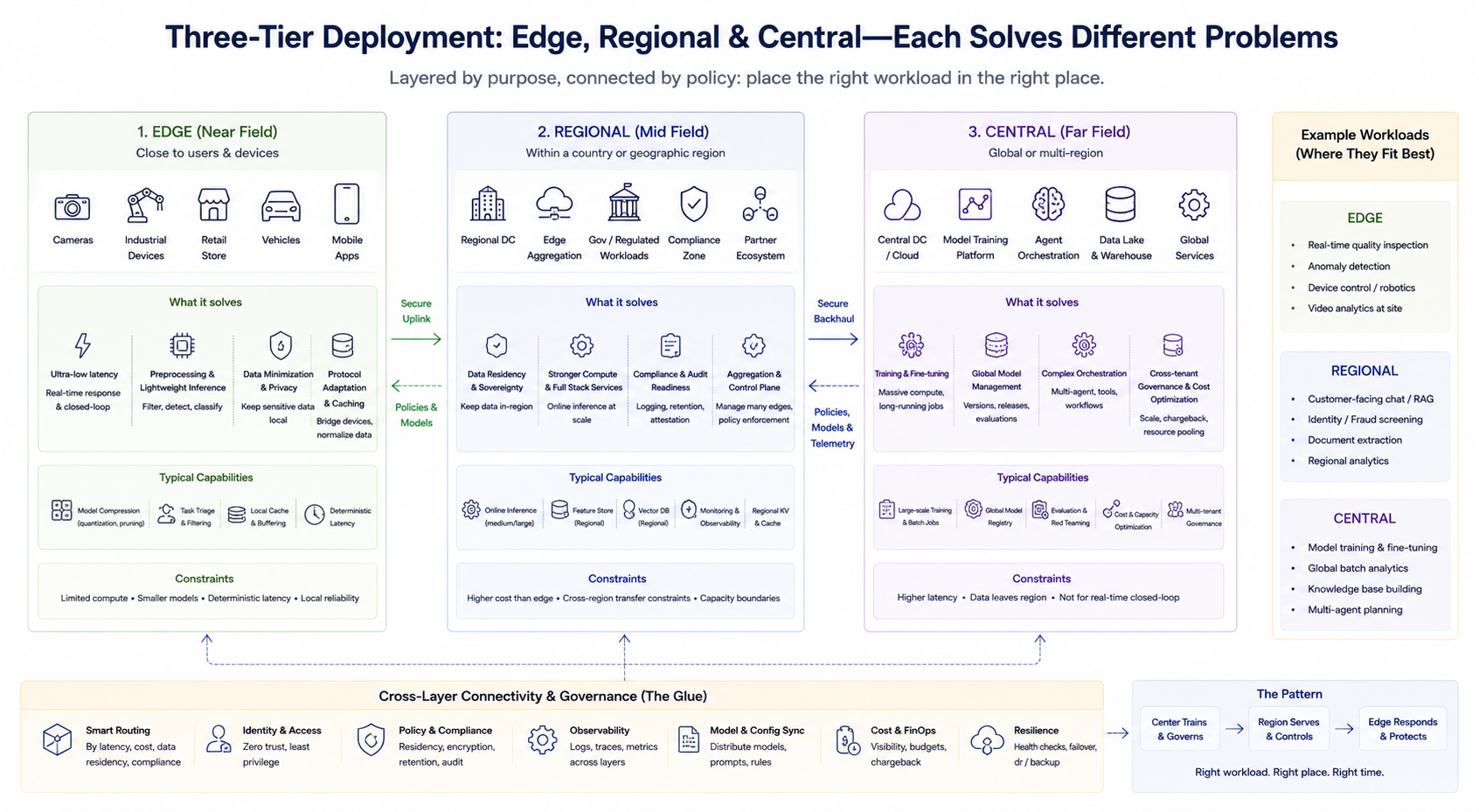
Cách tiếp cận kỹ thuật điển hình không phải lựa chọn nhị phân mà là kết hợp phân tầng. Khung đơn giản giúp làm rõ trách nhiệm của từng tầng (tên gọi cụ thể có thể khác nhau tùy nhà cung cấp):
Tầng biên (Gần trường)
Đặt gần người dùng hoặc thiết bị, tầng này xử lý tiền xử lý độ trễ thấp, suy luận nhẹ, lưu trữ tạm và thích ứng giao thức. Phù hợp với vòng lặp kín thời gian thực và giảm tải dữ liệu nhạy cảm. Sức mạnh băm biên thường hạn chế, nên ưu tiên nén mô hình, cắt nhiệm vụ và độ trễ xác định.
Tầng khu vực (Giữa trường)
Cung cấp sức mạnh băm mạnh hơn và stack dịch vụ đầy đủ trong quốc gia hoặc khu vực địa lý nhất định, đáp ứng lưu trú dữ liệu, kiểm toán tuân thủ và nhu cầu suy luận tập trung quy mô vừa. Tầng này cũng thường là mặt phẳng tổng hợp và điều khiển cho nhiều node biên.
Tầng trung tâm (Xa trường)
Xử lý đào tạo, xử lý hàng loạt quy mô lớn, quản lý mô hình toàn cầu, điều phối agent phức tạp, quản trị cross-tenant thống nhất và tối ưu chi phí. Phù hợp với khối lượng công việc ít nhạy cảm với độ trễ nhưng cần sức mạnh băm lớn và tổng hợp dữ liệu.
Ba tầng này không phải cấp bậc cố định mà phân chia theo nhiệm vụ kinh doanh. Doanh nghiệp có thể đồng thời vận hành đào tạo trung tâm, suy luận trực tuyến khu vực và phát hiện thời gian thực biên, định tuyến yêu cầu tới tầng phù hợp theo chiến lược routing.
Phân chia nhiệm vụ: gì ở biên, gì về trung tâm
Nguyên tắc phân chia thường xoay quanh bốn trục: tối thiểu hóa dữ liệu, ngân sách độ trễ, độ phức tạp mô hình và tần suất cập nhật.
Nhiệm vụ phù hợp với biên (giả sử đáp ứng yêu cầu sức mạnh băm):
-
Trích xuất đặc trưng thời gian thực, phát hiện đối tượng, kiểm tra chất lượng và các vòng lặp kín độ trễ thấp
-
Suy luận nhẹ sau phi tập trung hóa tại chỗ (ví dụ chỉ tải lên vector đặc trưng thay vì dữ liệu thô)
-
Suy luận dự phòng và chiến lược cache hit trong môi trường mạng yếu
Nhiệm vụ phù hợp với trung tâm hoặc khu vực:
-
Quy trình agent cần ngữ cảnh lớn, mô hình mạnh, toolchain phức tạp hoặc điều phối đa hệ thống
-
Suy luận phân tích cần tổng hợp dữ liệu liên phòng ban
-
Gọi nhạy cảm cần kiểm toán tập trung và quản lý khóa thống nhất
Sai lầm phổ biến là ép mô hình lớn ngữ cảnh dài lên biên dẫn đến OOM, hoặc gửi vòng lặp kín yêu cầu độ trễ thấp hoàn toàn về trung tâm gây gián đoạn nhịp sản xuất. Mục tiêu thiết kế cấu trúc không phải "biên càng nhiều càng tốt" mà là đặt đúng khối lượng công việc vào đúng vị trí dưới các ràng buộc.
Chủ quyền dữ liệu và tuân thủ: cấu trúc quyết định kiến trúc
Yêu cầu chủ quyền dữ liệu trực tiếp thay đổi hình thức triển khai suy luận. Mô hình có thể tải về tại chỗ, nhưng log, cache, index vector và trace gọi vẫn có thể gây rủi ro tuân thủ. Thực tế, các câu hỏi chính gồm:
-
Dữ liệu nào phải lưu trữ và tính toán tại tầng biên hoặc khu vực
-
Metadata nào có thể rời khu vực hoặc lên cloud, và có cần ẩn danh, thời gian lưu giữ không
-
Có cho phép sử dụng cross-region các phiên bản mô hình, nhà cung cấp khác nhau không (tránh "drift tuân thủ")
-
Khi kiểm toán và điều tra, output có thể tái dựng là "tạo ra tại vị trí, thời gian và dựa trên fragment dữ liệu cụ thể" không
Đáp án các câu hỏi này thường quyết định hệ thống có thể vận hành thực tế hay không, quan trọng hơn "mô hình có open source không." Nói cách khác, tuân thủ không phải add-on cho suy luận biên mà là điều kiện đầu vào cho thiết kế cấu trúc.
Mạng, điện và vận hành: chi phí thực của triển khai phân tán
Suy luận phân tán mang lại chi phí hệ thống cần đánh giá rõ ràng khi lập kế hoạch:
-
Mạng: Khi số node biên và khu vực tăng, quản lý chứng chỉ, đường truyền riêng/SD‑WAN, DNS và điều phối lưu lượng phức tạp hơn. Độ trễ cuối khó kiểm soát khi đa tuyến.
-
Điện và trung tâm dữ liệu: Các site biên phân tán, hiệu suất năng lượng và điều kiện làm mát trên mỗi đơn vị sức mạnh băm thường yếu hơn trung tâm dữ liệu lớn; trung tâm khu vực ở mức trung gian. Tiến độ cung cấp điện và rack upstream vẫn hạn chế tốc độ mở rộng, nhưng ràng buộc chuyển từ "campus đơn" sang "đa điểm song song."
-
Vận hành và nhất quán phiên bản: Khi mô hình, prompt, chiến lược routing và index phát hành đa điểm, drift phiên bản có thể xảy ra. Cần pipeline phát hành thống nhất, chiến lược rollback và kiểm tra sức khỏe, nếu không chi phí xử lý sự cố sẽ nhanh chóng làm mất lợi thế độ trễ của biên.
-
Mở rộng phạm vi bảo mật: Nhiều node hơn nghĩa là nhiều chứng chỉ, nhiều điểm vào và nhiều phương tiện lưu trữ cục bộ. Bảo mật vật lý và chu kỳ patch ở biên thường yếu hơn trung tâm dữ liệu, cần chiến lược tối thiểu quyền và kiểm soát từ xa phù hợp.
Vì vậy, cấu trúc phân tán không chỉ là "đẩy sức mạnh băm ra xa hơn" mà là chuyển một phần phức tạp vận hành và quản trị về sát site kinh doanh. Nếu năng lực tổ chức và công cụ nền tảng không theo kịp, lợi thế cấu trúc khó phát huy.
Quan hệ với suy luận tập trung: kiến trúc lai được triển khai thế nào
Phần lớn giải pháp trưởng thành áp dụng kiến trúc lai: trung tâm xử lý đào tạo, chính sách toàn cầu và khối lượng lớn; khu vực xử lý dịch vụ trực tuyến trong vùng tuân thủ; biên xử lý độ trễ thấp và phục hồi cục bộ. Mô hình kỹ thuật phổ biến gồm:
-
Cache phân tầng và reuse kết quả: Biên phục vụ yêu cầu tần suất cao, miss gửi về trung tâm. Cần định nghĩa key cache, TTL và chính sách dữ liệu nhạy cảm.
-
Chia mô hình và front mô hình nhỏ: Biên chạy mô hình nhỏ phát hiện hoặc phân loại, trung tâm chạy hợp nhất mô hình lớn và sinh diễn giải (đánh giá theo kịch bản).
-
Trả về và tổng hợp bất đồng bộ: Biên quyết định thời gian thực, sau đó trả về mẫu phi tập trung hoặc metric để lặp mô hình và giám sát.
-
Mặt phẳng điều khiển thống nhất: Routing, quota, giám sát và quản lý khóa tập trung tối đa, thực thi phân tán, giảm rủi ro "biên thành đảo cô lập."
Chìa khóa thành công kiến trúc lai là mặt phẳng điều khiển thống nhất cộng mặt phẳng thực thi phân tầng — không chỉ tăng số node.
Kết luận
Bản chất thảo luận về suy luận biên và phân tán không phải "khẩu hiệu phi tập trung" mà là lựa chọn kỹ thuật giữa độ trễ, băng thông, tuân thủ và chi phí vận hành. Khi doanh nghiệp chuyển từ demo sang quy mô, quyết định cấu trúc sẽ định hình mô hình, kiến trúc mạng và quy trình tổ chức. Bỏ qua tầng này có thể dẫn đến sức mạnh băm trung tâm mạnh nhưng bất ổn kéo dài ở tuyến đầu.









