Định tuyến yêu cầu AI là một năng lực hạ tầng được thiết kế để quản lý tài nguyên suy luận đa mô hình. Khi các mô hình ngôn ngữ lớn như GPT, Claude, Gemini và DeepSeek không ngừng phát triển, ngày càng có nhiều ứng dụng AI tích hợp đồng thời nhiều mô hình. Việc lựa chọn thông minh giữa các mô hình khác nhau đã trở thành một chủ đề quan trọng trong thiết kế hệ thống AI.
Gate.AI nằm ở vị trí trung gian giữa các ứng dụng và dịch vụ mô hình, đóng vai trò là một Cổng AI và lớp định tuyến mô hình. Khi kiến trúc đa mô hình trở thành tiêu chuẩn ngành, định tuyến mô hình không chỉ ảnh hưởng đến hiệu suất hệ thống mà còn tác động đến kiểm soát chi phí, độ ổn định dịch vụ và khả năng tự chủ của Tác nhân AI.
Định tuyến yêu cầu AI là gì?
Với vai trò là một cơ chế lập lịch tự động chọn mô hình mục tiêu dựa trên đặc điểm nhiệm vụ, định tuyến yêu cầu AI trong kiến trúc truyền thống thường là việc ứng dụng chỉ gọi một mô hình cố định duy nhất để hoàn thành nhiệm vụ suy luận. Trong kiến trúc đa mô hình, mỗi mô hình lại mang đến những lợi thế riêng, chẳng hạn như khả năng lập luận, tạo mã, xử lý văn bản dài hoặc tối ưu chi phí.
Lớp định tuyến mô hình sẽ phân tích nội dung yêu cầu và điều hướng đến mô hình phù hợp nhất để thực thi, từ đó nâng cao hiệu quả sử dụng tài nguyên tổng thể.
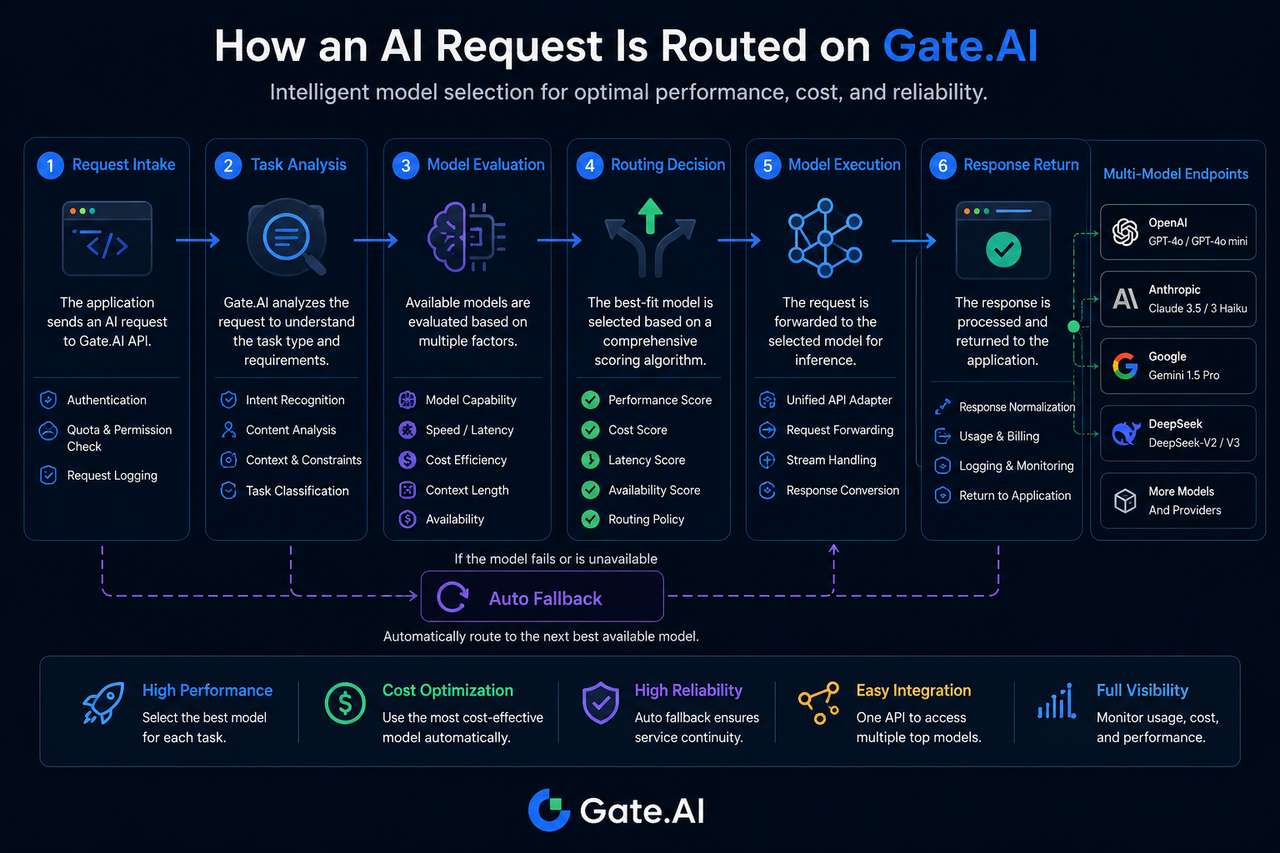
Bước 1: Yêu cầu AI đi vào Gate.AI
Một quy trình định tuyến bắt đầu từ giai đoạn tiếp nhận yêu cầu.
Khi một ứng dụng gửi yêu cầu, yêu cầu này trước tiên sẽ vào lớp Cổng AI của Gate.AI. Tại đây, hệ thống tiến hành xác minh thông tin nhận dạng, kiểm tra quyền truy cập và ghi lại các tham số yêu cầu.
Nội dung yêu cầu thường bao gồm:
- Đầu vào của người dùng
- Cấu hình mô hình
- Giới hạn token
- Yêu cầu về định dạng phản hồi
- Chiến lược gọi
Sau khi xác minh, yêu cầu sẽ chuyển sang giai đoạn phân tích tiếp theo.
Bước 2: Hệ thống phân tích loại nhiệm vụ
Nhận dạng nhiệm vụ là một thành phần cốt lõi của định tuyến mô hình.
Gate.AI xác định loại nhiệm vụ dựa trên các đặc điểm của yêu cầu, ví dụ:
- Hội thoại chung
- Tóm tắt văn bản dài
- Tạo nội dung
- Tạo mã nguồn
- Phân tích dữ liệu
- Gọi công cụ của tác nhân
Mỗi loại nhiệm vụ có những yêu cầu rất khác nhau về năng lực của mô hình.
Việc nhận dạng nhiệm vụ chính xác sẽ giúp quá trình so khớp mô hình sau đó diễn ra hiệu quả hơn.
Bước 3: Đánh giá và so khớp năng lực mô hình
Giai đoạn đánh giá mô hình sẽ xác định phạm vi các mô hình ứng cử viên.
Hệ thống tham chiếu cơ sở dữ liệu năng lực mô hình để lọc ra các mô hình hiện khả dụng.
Các khía cạnh đánh giá thường bao gồm:
- Năng lực lập luận
- Độ dài ngữ cảnh
- Tốc độ phản hồi
- Khả năng gọi công cụ
- Hỗ trợ đa phương thức
- Mức chi phí
Ví dụ, các nhiệm vụ lập luận phức tạp nên ưu tiên các mô hình có năng lực lập luận mạnh hơn, trong khi các nhiệm vụ xử lý tài liệu dài nên ưu tiên mô hình hỗ trợ cửa sổ ngữ cảnh siêu dài.
Bước 4: Đưa ra quyết định định tuyến
Giai đoạn quyết định định tuyến sẽ xác định mô hình thực thi cuối cùng.
Sau khi xác định các mô hình ứng cử viên, hệ thống sẽ chấm điểm chúng bằng cách kết hợp nhiều chỉ số.
Các yếu tố tham khảo phổ biến bao gồm:
Hiệu suất mô hình
Hiệu suất mô hình quyết định chất lượng hoàn thành nhiệm vụ.
Các vấn đề phức tạp thường đòi hỏi khả năng lập luận logic mạnh mẽ hơn, trong khi các nhiệm vụ đơn giản có thể không cần đến mô hình có hiệu suất cao nhất.
Độ trễ phản hồi
Tốc độ phản hồi ảnh hưởng trực tiếp đến trải nghiệm người dùng.
Đối với các kịch bản tương tác thời gian thực, các mô hình có độ trễ thấp thường nhận được mức ưu tiên cao hơn.
Chi phí gọi
Chi phí suy luận khác nhau giữa các mô hình.
Khi có nhiều mô hình cùng có thể hoàn thành một nhiệm vụ, hệ thống có thể ưu tiên mô hình có hiệu suất tài nguyên cao hơn.
Tính khả dụng của dịch vụ
Trạng thái của mô hình cũng là một yếu tố quan trọng trong quyết định định tuyến.
Nếu một mô hình bị giới hạn tỷ lệ, gặp lỗi hoặc bị tắc nghẽn, hệ thống sẽ tự động giảm mức ưu tiên của nó.
Bước 5: Yêu cầu được gửi đến mô hình mục tiêu
Sau khi quyết định định tuyến được đưa ra, yêu cầu sẽ được chuyển tiếp đến mô hình mục tiêu.
Ở giai đoạn này, Gate.AI xử lý thống nhất các khác biệt về giao diện giữa các nhà cung cấp mô hình khác nhau.
Các nhà phát triển ứng dụng không cần xây dựng giao diện riêng cho từng mô hình.
Một lớp truy cập thống nhất giúp giảm độ phức tạp trong phát triển và nâng cao khả năng mở rộng của hệ thống.
Bước 6: Mô hình tạo và trả về kết quả
Sau khi mô hình mục tiêu hoàn tất suy luận, kết quả được trả về cho Gate.AI.
Gate.AI chuẩn hóa phản hồi, đảm bảo cấu trúc dữ liệu nhất quán từ các mô hình khác nhau.
Định dạng đầu ra thống nhất giúp giảm khối lượng công việc thích ứng ở lớp ứng dụng và đơn giản hóa việc tích hợp hệ thống về sau.
Kết quả cuối cùng sẽ được trả về ứng dụng hoặc Tác nhân AI.
Điều gì xảy ra khi mô hình mục tiêu không khả dụng?
Việc mô hình không khả dụng là một tình huống thường gặp trong hệ sinh thái đa mô hình.
Nếu mô hình mục tiêu bị hết thời gian chờ, bị giới hạn tỷ lệ hoặc gặp sự cố dịch vụ, Gate.AI có thể kích hoạt quy trình dự phòng tự động.
Hệ thống sẽ chọn lại một mô hình dự phòng theo các chính sách đã được thiết lập để tiếp tục thực thi nhiệm vụ.
Cơ chế này giảm thiểu rủi ro điểm lỗi đơn lẻ và nâng cao tính liên tục tổng thể của dịch vụ.
Để tìm hiểu thêm về quy trình này, hãy tham khảo bài viết "Điều gì xảy ra khi mô hình AI bị lỗi? Phân tích luồng hoàn chỉnh về cơ chế dự phòng tự động của Gate.AI."
Ví dụ về quy trình định tuyến yêu cầu AI
Ví dụ dưới đây minh họa một luồng điển hình cho nhiệm vụ tạo nội dung:
| Giai đoạn |
Hành động của hệ thống |
| Tiếp nhận yêu cầu |
Ứng dụng gửi yêu cầu tạo nội dung |
| Phân tích nhiệm vụ |
Xác định là tạo nội dung văn bản dài |
| Lọc mô hình |
Chọn mô hình ứng cử viên hỗ trợ ngữ cảnh dài |
| Quyết định định tuyến |
Chấm điểm dựa trên hiệu suất, chi phí và độ trễ |
| Thực thi mô hình |
Gửi yêu cầu đến mô hình mục tiêu |
| Xử lý kết quả |
Trả về đầu ra đã chuẩn hóa |
| Khôi phục lỗi |
Tự động chuyển sang mô hình dự phòng nếu cần |
Quy trình này thường được hoàn tất trong một khoảng thời gian rất ngắn, và người dùng hầu như không nhận thấy việc lựa chọn mô hình đang diễn ra phía sau.
Tổng kết
Là một năng lực cốt lõi của Cổng AI, định tuyến yêu cầu AI tự động chọn mô hình phù hợp nhất để thực thi một nhiệm vụ trong số nhiều mô hình ngôn ngữ lớn. So với việc gọi một mô hình cố định duy nhất, định tuyến mô hình tận dụng tối đa điểm mạnh của từng mô hình, qua đó tăng cường tính linh hoạt, độ ổn định và hiệu quả sử dụng tài nguyên của hệ thống.
Trong kiến trúc Gate.AI, một yêu cầu AI trải qua nhiều giai đoạn: tiếp nhận yêu cầu, nhận dạng nhiệm vụ, đánh giá mô hình, quyết định định tuyến, thực thi mô hình và trả về kết quả.
Câu hỏi thường gặp
Tại sao Gate.AI cần định tuyến mô hình?
Gate.AI kết nối nhiều hệ sinh thái mô hình AI, trong đó mỗi mô hình có thế mạnh riêng về lập luận, tạo mã nguồn, xử lý văn bản dài, v.v. Định tuyến mô hình sẽ tự động chọn mô hình phù hợp nhất dựa trên yêu cầu của từng nhiệm vụ.
Một yêu cầu AI có thể gọi nhiều mô hình cùng lúc không?
Thông thường, một yêu cầu AI duy nhất chỉ được thực thi bởi một mô hình mục tiêu. Tuy nhiên, trong một số kịch bản phức tạp, có thể áp dụng mô hình cộng tác đa mô hình, trong đó các mô hình khác nhau đảm nhận các phần khác nhau của nhiệm vụ.
Những yếu tố nào được xem xét chính trong quyết định định tuyến AI?
Các quyết định định tuyến AI thường xem xét nhiều yếu tố như hiệu suất mô hình, tốc độ phản hồi, chi phí suy luận, độ dài ngữ cảnh, khả năng gọi công cụ và tính khả dụng của dịch vụ.
Sự khác biệt giữa định tuyến mô hình và cân bằng tải là gì?
Cân bằng tải chủ yếu giải quyết việc phân phối lưu lượng, trong khi định tuyến mô hình tập trung vào việc so khớp năng lực mô hình. Định tuyến mô hình chọn mô hình phù hợp nhất dựa trên đặc điểm của nhiệm vụ, chứ không chỉ đơn giản là phân tán lưu lượng yêu cầu.










