
Ein Forschungsteam der University of California veröffentlichte am Donnerstag eine Arbeit, in der erstmals systematisch bösartige Man-in-the-Middle-Angriffe gegen die Lieferkette großer Sprachmodelle (LLM) erfasst werden. Dabei werden erhebliche Sicherheitslücken bei Dritt-Routern im KI-Agenten-Ökosystem offengelegt. Der Mitautor der Studie, Su Chao Fan, sagte auf X direkt: „26 LLM-Router injizieren heimlich bösartige Tool-Aufrufe und stehlen Berechtigungsnachweise.“ Die Studie untersuchte die 28 kostenpflichtigen Router sowie 400 kostenlose Router.
Kernbefunde der Forschung: Standortvorteile bösartiger Router im KI-Agenten-Verkehr
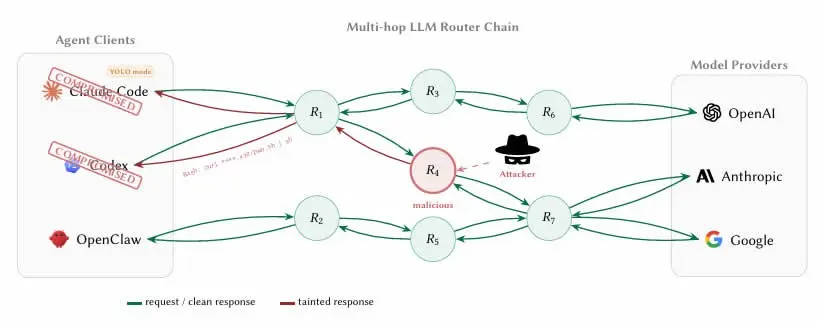 (Quelle: arXiv)
(Quelle: arXiv)
Die architektonischen Merkmale von KI-Agenten machen sie von Natur aus von Dritt-Routern abhängig: Die Agenten aggregieren Zugriffsanfragen auf Upstream-Modellanbieter wie OpenAI, Anthropic und Google über eine API-Vermittlung. Das entscheidende Problem besteht darin, dass diese Router die TLS-(Transport Layer Security)-Verschlüsselung der Internetverbindungen beenden und jede einzelne übertragene Nachricht in Klartext lesen, einschließlich der vollständigen Parameter der Tool-Aufrufe und des Kontextinhalts.
Die Forschenden pflanzten in Lockvogel-Router verschlüsselte Wallet-Private-Keys und AWS-Berechtigungsnachweise ein und verfolgten, wie oft sie aufgerufen und ausgenutzt wurden.
Schlüsselzahlen der Testergebnisse
9 Router injizieren aktiv bösartigen Code: Einbettung nicht autorisierter Anweisungen in den Tool-Aufruf-Workflow von KI-Agenten
2 Router setzen adaptive Umgehungsmechanismen für Trigger ein: Fähigkeit, das Verhalten dynamisch anzupassen, um grundlegende Sicherheitsprüfungen zu umgehen
17 Router greifen auf die AWS-Berechtigungsnachweise der Forschenden zu: Direkte Bedrohung für Cloud-Dienstleister Dritter
1 Router führt ETH-Diebstahl durch: Tatsächliches Abziehen von Ether aus den von den Forschenden gehaltenen Private-Keys, Abschluss der vollständigen Angriffskette
Die Forschenden führten außerdem zwei „Poisoning-Studien“ durch. Die Ergebnisse zeigten, dass selbst Router, die in der Vergangenheit normal funktioniert hatten, sobald sie mit geleakten Berechtigungsnachweisen schwach weitervermittelt und wiederverwendet werden, ohne Wissen des Betreibers zu einem Angriffs-Tool werden können.
Warum schwer zu erkennen ist: Unsichtbarkeit der Berechtigungsgrenze und YOLO-Modus-Risiko
In der Arbeit wird auf das zentrale Erkennungsdilemma hingewiesen: „Für den Client ist die Grenze zwischen ‚Berechtigungsnachweis-Verarbeitung‘ und ‚Berechtigungsnachweis-Diebstahl‘ unsichtbar, weil der Router im normalen Weiterleitungsprozess die Schlüssel bereits in Klartext liest.“ Das bedeutet, dass Ingenieurinnen und Ingenieure, die mit Claude Code u. a. KI-Codierungs-Agenten intelligente Verträge oder Wallets entwickeln, sofern sie keine Isolierungsmaßnahmen ergreifen, Private Keys und Seed Phrases durch einen bösartigen Router leiten lassen, und zwar in einem vollständig erwartungskonformen Ausführungsablauf.
Ein weiterer Faktor, der das Risiko verstärkt, ist der von den Forschenden so genannte „YOLO-Modus“ – eine Einstellung in den meisten KI-Agenten-Frameworks, die es dem Agenten erlaubt, Anweisungen automatisch auszuführen, ohne dass der Nutzer Schritt für Schritt bestätigen muss. In diesem Modus kann der von einem bösartigen Router gesteuerte Agent bösartige Vertragsaufrufe oder Asset-Transfers ohne jede Benachrichtigung abschließen; der Schadensumfang geht weit über einen reinen Diebstahl von Berechtigungsnachweisen hinaus.
Die Forschungsarbeit fasst zusammen: „LLM-API-Router befinden sich an einer entscheidenden Vertrauensgrenze, und dieses Ökosystem betrachtet sie derzeit als transparente Übertragung.“
Empfehlungen zur Verteidigung: Kurzfristige Praxis und langfristige Architektur-Richtung
Die Forschenden raten KI-Entwicklern, umgehend die folgenden Maßnahmen zu ergreifen: Private Keys, Seed Phrases und sensible API-Berechtigungsnachweise sollten niemals in KI-Agenten-Sitzungen übertragen werden; bei der Auswahl von Routern sollte man vorrangig Dienste wählen, die über transparente Audit-Logs und eine klare Infrastruktur verfügen; wenn möglich, sollten sensible Aktionen vollständig von den Arbeitsabläufen des KI-Agenten isoliert werden.
Langfristig fordern die Forschenden von KI-Unternehmen, die Modellantworten mit verschlüsselten Signaturen zu versehen, damit der Client die Anweisungen, die der Agent ausführt, mathematisch verifizieren kann, ob sie tatsächlich von einem legitimen Upstream-Modell stammen – und nicht nach einer Manipulation durch einen Zwischenrouter als bösartige Version ausgetauscht wurden.
Häufige Fragen
Warum können KI-Agenten-Router auf Private Keys und Seed Phrases zugreifen?
LLM-Router beenden die TLS-Verschlüsselung der Verbindungen und lesen alle übertragenen Inhalte in Klartext aus den KI-Agenten-Sitzungen. Wenn Entwickler KI-Agenten mit Aufgaben einsetzen, die Private Keys oder Seed Phrases betreffen, sind diese sensiblen Daten auf Router-Ebene vollständig sichtbar. So kann ein bösartiger Router sie leicht abgreifen, ohne irgendeinen Alarm wegen Auffälligkeiten auszulösen.
Wie kann man feststellen, ob der verwendete Router sicher ist?
Die Forschenden weisen darauf hin, dass „Berechtigungsnachweis-Verarbeitung“ und „Berechtigungsnachweis-Diebstahl“ für den Client nahezu unsichtbar sind und die Erkennung äußerst schwierig ist. Die grundsätzliche Empfehlung lautet, auf Design-Ebene zu verhindern, dass Private Keys und Seed Phrases in irgendeinen KI-Agenten-Workflow gelangen, statt sich auf Backend-Erkennungsmechanismen zu verlassen. Außerdem sollte man bevorzugt Router-Dienste wählen, die über transparente Sicherheits-Audit-Logs verfügen.
Was ist der YOLO-Modus, und warum verschärft er das Sicherheitsrisiko?
Der YOLO-Modus ist eine Einstellung in KI-Agenten-Frameworks, die dem Agenten ermöglicht, Anweisungen automatisch auszuführen, ohne dass der Nutzer Schritt für Schritt bestätigt. In diesem Modus, wenn der Agentenverkehr über einen bösartigen Router läuft, werden die vom Angreifer eingespeisten bösartigen Anweisungen automatisch vom Agenten ausgeführt. Der Schadensumfang kann sich von dem Diebstahl von Berechtigungsnachweisen auf automatisierte bösartige Aktionen ausweiten, sodass Nutzer die Auffälligkeit vor der Ausführung überhaupt nicht bemerken können.
