Giao dịch
Cơ bản
Giao ngay
Giao dịch tiền điện tử một cách tự do
Giao dịch ký quỹ
Tăng lợi nhuận của bạn với đòn bẩy
Giao dịch khối & Chuyển đổi
0 Fees
Giao dịch bất kể khối lượng, không mất phí, không trượt giá
Token đòn bẩy
Sản phẩm ETF có thuộc tính đòn bẩy giao dịch giao ngay không cần vay không cháy tải khoản
Trước giờ mở cửa
Giao dịch các token mới trước khi chúng được niêm yết chính thức
Futures
Futures
Hàng trăm hợp đồng được thanh toán bằng USDT hoặc BTC
Quyền chọn
HOT
Giao dịch với các quyền chọn kiểu Châu Âu
Tài khoản hợp nhất
Tối đa hóa hiệu quả sử dụng vốn của bạn
Giao dịch demo
Bắt đầu với Hợp đồng
Nắm vững kỹ năng giao dịch hợp đồng từ đầu
Sự kiện tương lai
Tham gia các sự kiện để giành được những phần thưởng hậu hĩnh
Giao dịch demo
Sử dụng tiền ảo để trải nghiệm giao dịch không rủi ro
Kiếm tiền
Launch
CandyDrop
Sưu tập kẹo để kiếm airdrop
Launchpool
Thế chấp nhanh, kiếm token mới tiềm năng
HODLer Airdrop
Nắm giữ GT và nhận được airdrop lớn miễn phí
Launchpad
Đăng ký sớm dự án token lớn tiếp theo
Điểm Alpha
NEW
Giao dịch tài sản on-chain và tận hưởng phần thưởng airdrop!
Điểm Futures
NEW
Kiếm điểm futures và nhận phần thưởng airdrop
Đầu tư
Simple Earn
Kiếm lãi từ các token nhàn rỗi
Đầu tư tự động
Đầu tư tự động một cách thường xuyên.
Sản phẩm tiền kép
Mua thấp và bán cao để kiếm lợi nhuận từ biến động giá
Soft Staking
Kiếm phần thưởng với staking linh hoạt
Vay Crypto
0 Fees
Thế chấp một loại tiền điện tử để vay một loại khác
Trung tâm cho vay
Trung tâm cho vay một cửa
Trung tâm tài sản VIP
Quản lý tài sản tùy chỉnh giúp tăng trưởng tài sản của bạn
Quản lý tài sản cá nhân
Quản lý tài sản tùy chỉnh giúp tăng trưởng tài sản kỹ thuật số của bạn
Quỹ định lượng
Đội ngũ quản lý tài sản hàng đầu giúp bạn kiếm lợi nhuận mà không cần lo lắng
Staking
Stake tiền điện tử để kiếm tiền từ các sản phẩm PoS
Đòn bẩy thông minh
NEW
Không bị thanh lý bắt buộc trước hạn, không phải lo lắng về lợi nhuận đòn bẩy
Đúc GUSD
Sử dụng USDT/USDC để đúc GUSD với lợi suất tương đương kho bạc
Thêm
Cơ quan quản lý Úc cảnh báo về Grok trong các đơn khiếu nại ngày càng tăng về lạm dụng hình ảnh AI
33phút trước
Những Tên Cướp Bịt Mặt Trói Buộc Phụ Nữ Ở Pháp, Đánh Cắp USB Tiền Điện Tử
1giờ trước
Chủ đề thịnh hành
Xem thêm31.68K Phổ biến
440 Phổ biến
60.26K Phổ biến
233.27K Phổ biến
13.99K Phổ biến
Gate Fun hot
Xem thêm- Vốn hóa:$3.57KNgười nắm giữ:10.00%
- Vốn hóa:$3.69KNgười nắm giữ:20.37%
- Vốn hóa:$4.6KNgười nắm giữ:24.99%
- Vốn hóa:$5.68KNgười nắm giữ:29.93%
- Vốn hóa:$3.57KNgười nắm giữ:10.00%
Ghim
Các insider cho biết DeepSeek V4 sẽ vượt qua Claude và ChatGPT trong lĩnh vực lập trình, ra mắt trong vòng vài tuần
Tóm tắt ngắn gọn
DeepSeek được cho là đang lên kế hoạch ra mắt mô hình V4 vào khoảng giữa tháng 2, và nếu các thử nghiệm nội bộ là dấu hiệu, các ông lớn AI của Thung lũng Silicon nên cảm thấy lo lắng. Startup AI có trụ sở tại Hàng Châu này có thể nhắm tới việc phát hành vào khoảng ngày 17 tháng 2—Tết Nguyên Đán, tất nhiên—với một mô hình được thiết kế đặc biệt cho các nhiệm vụ lập trình, theo The Information. Những người có kiến thức trực tiếp về dự án này cho biết V4 vượt trội hơn cả Claude của Anthropic và dòng GPT của OpenAI trong các bài kiểm tra nội bộ, đặc biệt khi xử lý các đoạn mã dài cực kỳ. Tất nhiên, không có bất kỳ bài kiểm tra hay thông tin nào về mô hình đã được công khai, nên không thể xác minh trực tiếp những tuyên bố này. DeepSeek cũng chưa xác nhận những tin đồn đó.
Dù sao, cộng đồng nhà phát triển cũng không chờ đợi thông báo chính thức. Reddit r/DeepSeek và r/LocalLLaMA đã bắt đầu sôi động, người dùng tích trữ tín dụng API, và các người đam mê trên X đã nhanh chóng chia sẻ dự đoán rằng V4 có thể củng cố vị thế của DeepSeek như một kẻ ngoại đạo nhỏ bé nhưng kiên cường, không chơi theo luật của các tỷ đô của Thung lũng Silicon.
Điều này sẽ không phải là lần đầu tiên DeepSeek gây đột phá. Khi công ty ra mắt mô hình lý luận R1 vào tháng 1 năm 2025, nó đã gây ra một đợt bán tháo trị giá $1 nghìn tỷ trên thị trường toàn cầu. Lý do? R1 của DeepSeek phù hợp với mô hình o1 của OpenAI trong các bài kiểm tra về toán học và lý luận mặc dù được cho là chỉ tốn khoảng $6 triệu để phát triển—gần 68 lần rẻ hơn so với chi phí của các đối thủ cạnh tranh. Mô hình V3 của nó sau đó đạt 90.2% trên bài kiểm tra MATH-500, vượt xa Claude với 78.3% và bản cập nhật gần đây “V3.2 Speciale” còn nâng cao hiệu suất hơn nữa.
Hình ảnh: DeepSeek
Tập trung vào lập trình của V4 sẽ là một bước chuyển chiến lược. Trong khi R1 nhấn mạnh lý luận thuần túy—logic, toán học, chứng minh chính thức—V4 là một mô hình lai (lý luận và nhiệm vụ phi lý luận) nhằm vào thị trường nhà phát triển doanh nghiệp, nơi mà việc tạo mã chính xác cao trực tiếp mang lại doanh thu. Để chiếm ưu thế, V4 cần vượt qua Claude Opus 4.5, hiện đang giữ kỷ lục Verified của SWE-bench ở mức 80.9%. Nhưng nếu dựa vào các lần ra mắt trước của DeepSeek, thì điều này không phải là không thể đạt được ngay cả khi đối mặt với tất cả các hạn chế mà một phòng thí nghiệm AI Trung Quốc phải đối mặt. Chất gia vị không quá bí mật Giả sử các tin đồn là đúng, làm thế nào phòng thí nghiệm nhỏ này có thể đạt được thành tích như vậy? Vũ khí bí mật của công ty có thể nằm trong bài báo nghiên cứu ngày 1 tháng 1: Manifold-Constrained Hyper-Connections, hay mHC. Được đồng tác giả bởi nhà sáng lập Liang Wenfeng, phương pháp đào tạo mới này giải quyết một vấn đề cơ bản trong việc mở rộng các mô hình ngôn ngữ lớn—làm thế nào để mở rộng khả năng của mô hình mà không gây ra sự không ổn định hoặc nổ tung trong quá trình huấn luyện. Kiến trúc AI truyền thống buộc tất cả thông tin đi qua một con đường hẹp duy nhất. mHC mở rộng con đường đó thành nhiều luồng có thể trao đổi thông tin mà không gây sụp đổ trong quá trình huấn luyện.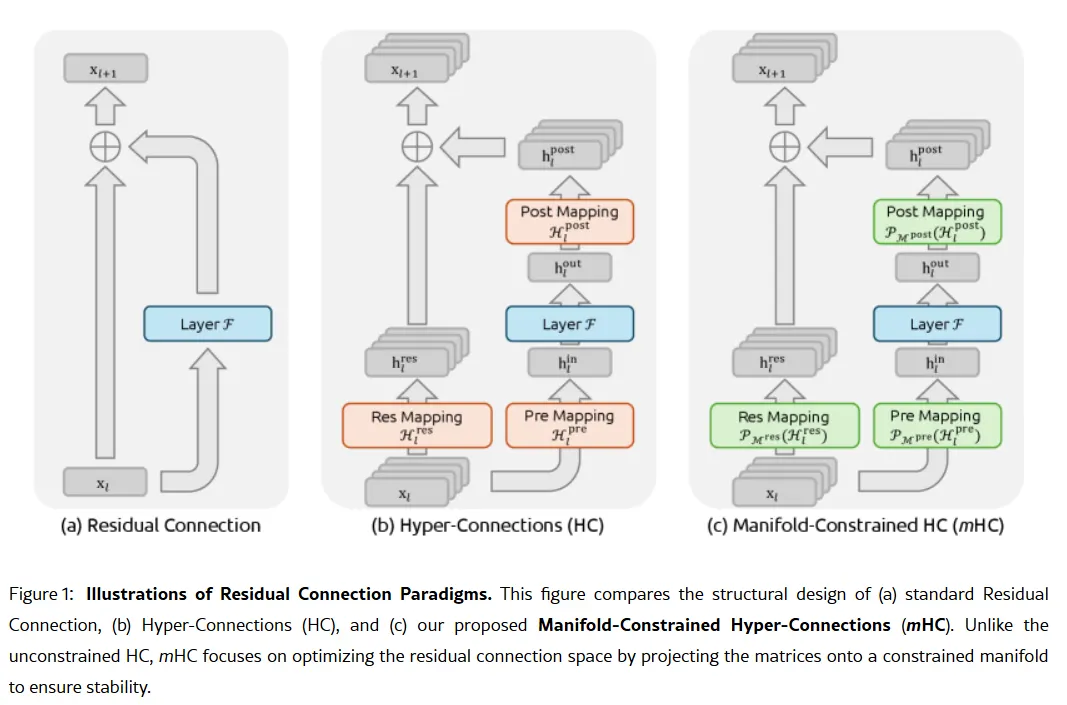
Hình ảnh: DeepSeek
Wei Sun, nhà phân tích chính về AI tại Counterpoint Research, gọi mHC là một “bước đột phá đáng chú ý” trong bình luận với Business Insider. Kỹ thuật này, bà nói, cho thấy DeepSeek có thể “vượt qua các nút thắt về tính toán và mở ra những bước nhảy trong trí tuệ,” ngay cả khi hạn chế truy cập vào các chip cao cấp do các hạn chế xuất khẩu của Mỹ. Lian Jye Su, nhà phân tích trưởng tại Omdia, nhận xét rằng sự sẵn sàng công khai phương pháp của DeepSeek thể hiện một “sự tự tin mới trong ngành công nghiệp AI Trung Quốc.” Phương pháp mã nguồn mở của công ty đã khiến nó trở thành tâm điểm của các nhà phát triển, những người xem nó như hiện thân của những gì OpenAI từng là, trước khi chuyển sang các mô hình đóng và các vòng gọi vốn trị giá tỷ đô.
Không phải ai cũng bị thuyết phục. Một số nhà phát triển trên Reddit phàn nàn rằng các mô hình lý luận của DeepSeek lãng phí tính toán cho các nhiệm vụ đơn giản, trong khi các nhà phê bình cho rằng các bài kiểm tra của công ty không phản ánh thực tế phức tạp của thế giới thực. Một bài đăng trên Medium có tiêu đề “DeepSeek Tệ—Và Tôi Đã Chán Giả Vờ Không Phải Như Vậy” đã lan truyền mạnh mẽ vào tháng 4 năm 2025, cáo buộc các mô hình tạo ra “rác thải boilerplate với lỗi” và “thư viện ảo tưởng.” DeepSeek cũng mang theo hành lý nặng nề. Các vấn đề về quyền riêng tư đã làm phiền công ty, với một số chính phủ cấm ứng dụng gốc của DeepSeek. Các mối liên hệ của công ty với Trung Quốc và các câu hỏi về kiểm duyệt trong các mô hình của nó thêm phần căng thẳng địa chính trị vào các tranh luận kỹ thuật. Dù sao, đà phát triển là không thể phủ nhận. DeepSeek đã được chấp nhận rộng rãi ở châu Á, và nếu V4 thực hiện đúng các lời hứa về lập trình, thì việc áp dụng trong doanh nghiệp ở phương Tây có thể sẽ theo sau.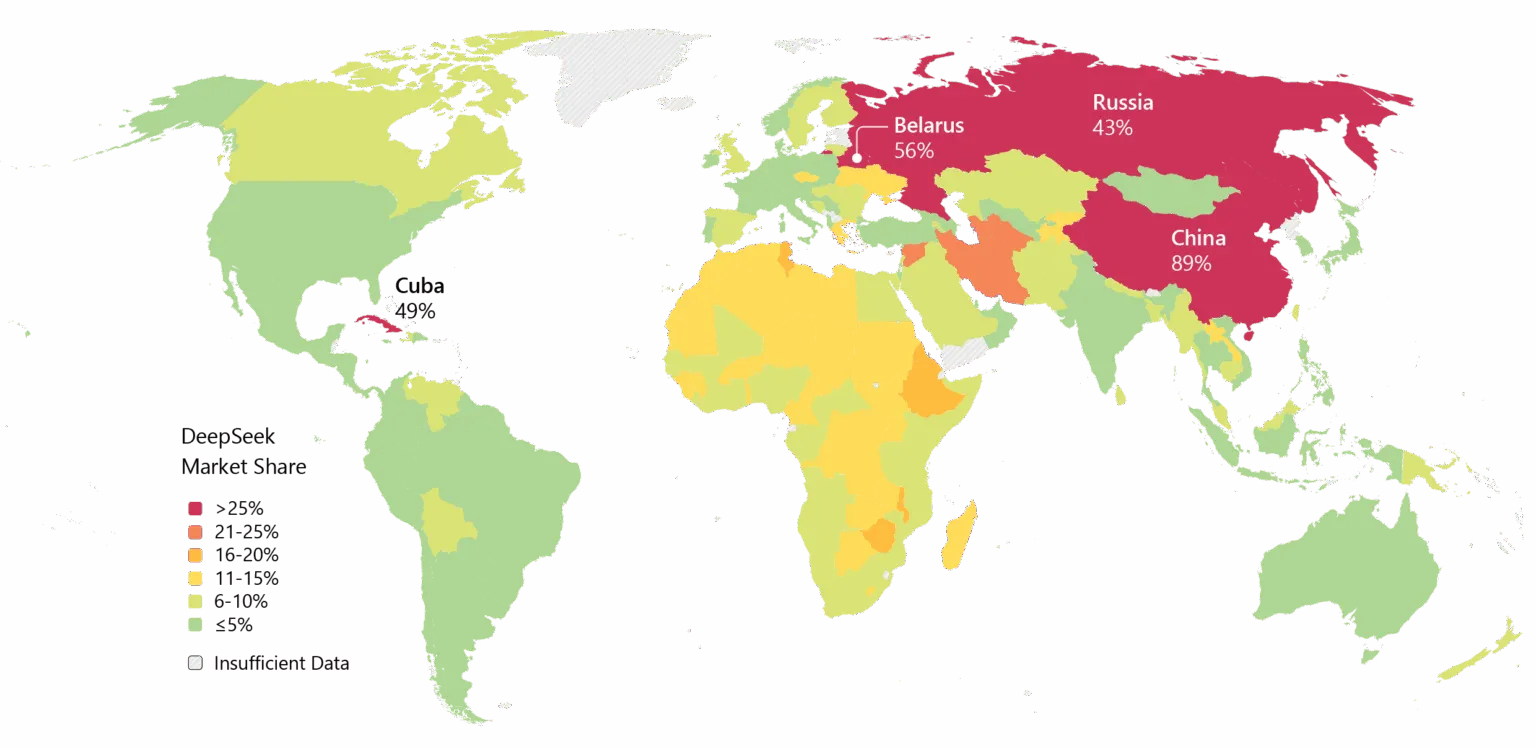
Hình ảnh: Microsoft
Cũng còn vấn đề thời điểm. Theo Reuters, DeepSeek ban đầu dự định ra mắt mô hình R2 vào tháng 5 năm 2025, nhưng đã kéo dài thời gian sau khi nhà sáng lập Liang không hài lòng với hiệu suất của nó. Hiện tại, với V4 được cho là sẽ ra mắt vào tháng 2 và R2 có thể theo sau vào tháng 8, công ty đang tiến hành với tốc độ cho thấy sự cấp bách—hoặc sự tự tin. Có thể cả hai.