Starknet 公布主網故障原因,網路已恢復穩定運作
Starknet 開發團隊,基於以太坊的 layer-2 擴展網路 (L2),已公布事後檢查報告 (post-mortem),釐清主網於星期一暫停運作的根本原因。
根據報告,問題源自於 blockifier (執行層) 與證明層 (證明層) 之間的網路狀態不一致。Starknet 團隊解釋,在特定的跨函數呼叫組合、變數寫入操作、回滾 (revert) 及錯誤捕捉機制中,blockifier 曾“記憶”了一個在已回滾函數內產生的狀態變更,導致交易執行出現偏差。
然而,這個錯誤從未到達 L1 的完成狀態,因為 Starknet 的證明層已偵測到異常並阻止錯誤交易被記錄到帳本,顯示檢查機制仍按設計正常運作。
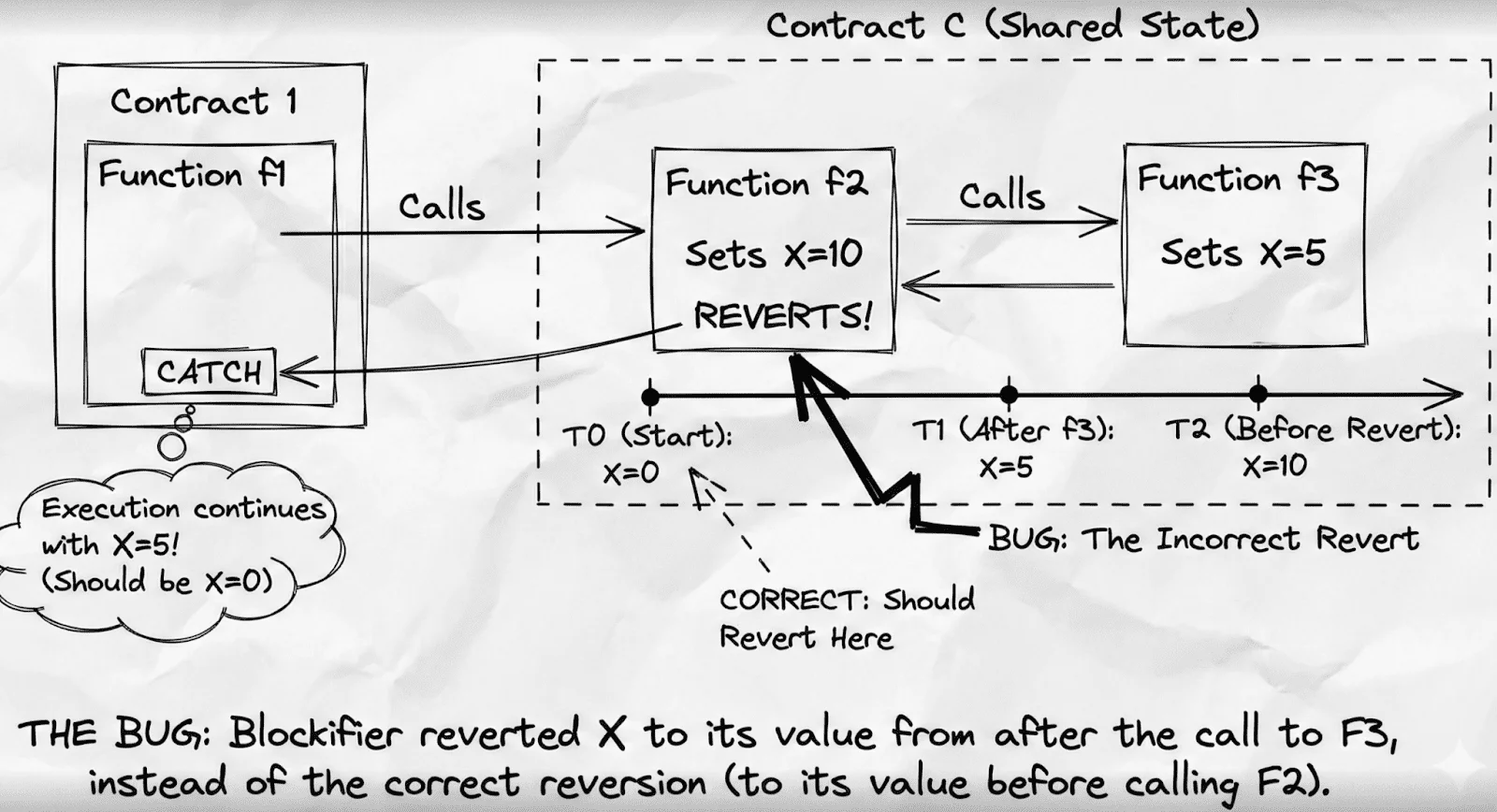 示意圖:程式碼錯誤如何影響網路 | 來源:Starknet 由於此問題,網路必須進行一次區塊重組 (block reorganization),使約 18 分鐘的網路運作被回溯。團隊表示,Starknet 現已恢復正常運作。
示意圖:程式碼錯誤如何影響網路 | 來源:Starknet 由於此問題,網路必須進行一次區塊重組 (block reorganization),使約 18 分鐘的網路運作被回溯。團隊表示,Starknet 現已恢復正常運作。
事後,團隊承諾將加強測試與源碼審計,以防止類似錯誤再次發生。此次中斷也凸顯出在多層架構與高複雜度的區塊鏈新世代開發中,面臨的越來越大挑戰。
這並非 Starknet 在 2025 年的首次故障。此前,該網路已發生多次事故,最嚴重的是在 9 月,當時推出了名為 Grinta 的重大協議升級後。
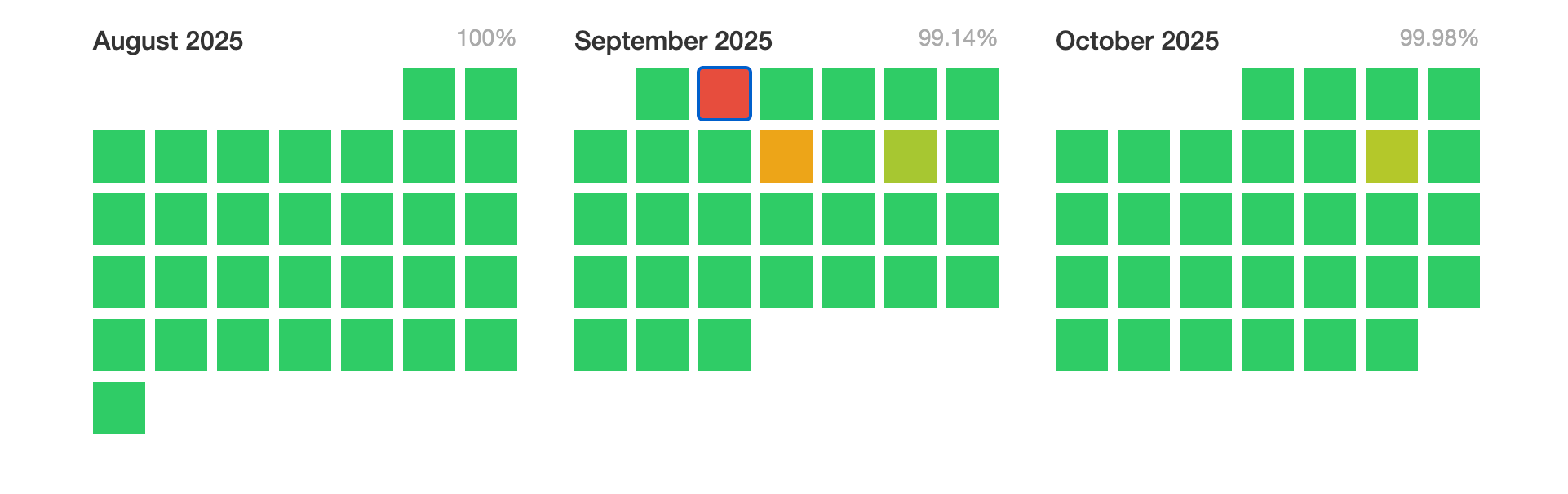 Starknet 的運作時間,紅色方框代表 9 月的停電事件 | 來源:Starknet 根據事後檢查報告,當時的故障持續超過五小時,源自 sequencer 的錯誤——負責排序交易的組件。在中斷期間,區塊產生完全停止,並進行了兩次鏈重組以恢復運作狀態。
Starknet 的運作時間,紅色方框代表 9 月的停電事件 | 來源:Starknet 根據事後檢查報告,當時的故障持續超過五小時,源自 sequencer 的錯誤——負責排序交易的組件。在中斷期間,區塊產生完全停止,並進行了兩次鏈重組以恢復運作狀態。
重組過程中約有一小時的網路運作被回溯,使用者需重新提交交易。對一般用戶來說,重新提交交易可能只帶來小小的不便,若非時效性交易則影響較小;但對於頻繁交易者或需快速退出或進行短期交易的投資者,可能造成嚴重後果。
王俊