谷歌最新技術:通過搜尋引擎,極大增強ChatGPT等模型的準確率
原文來源:AIGC開放社區
 圖片來源:由無界 AI生成
圖片來源:由無界 AI生成
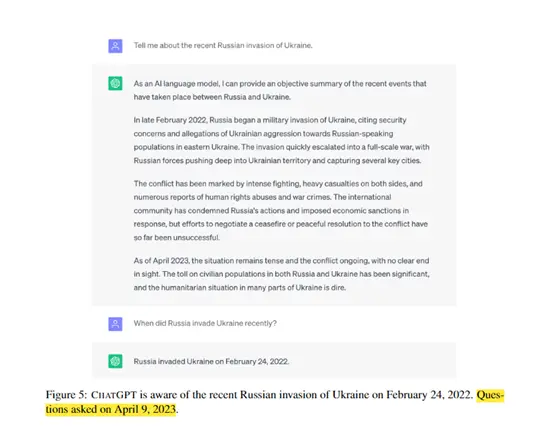
由於Transformer的出現,使得ChatGPT等大語言模型在處理自然語言任務上的能力得到了大幅度提升。 但生成的內容卻包含大量錯誤或過時的信息,同時缺乏事實性評估體系,來驗證內容的真偽。
為了全面評估大語言模型對世界變化的適應能力和內容的真實性,谷歌AI研究團隊發佈了一篇名為《通過搜尋引擎知識增強大語言模型的準確性》的論文。 提出了一種FRESH的方法,可通過從搜尋引擎獲取實時資訊,來提升ChatGPT、Bard等大型語言模型的準確性。
研究人員構建了一個新的問答基準測試集FRESHQA,其中包含600個各類真實問題,答案變化頻率分為“永不改變”“變化緩慢”“變化頻繁”和“錯誤前提”四大類別。
同時,還設計了嚴格模式和寬鬆模式兩種評估方法,前者要求回答中的所有信息必須準確最新,後者僅評估主要回答的正確性。
實驗結果顯示,FRESH明顯提升了大語言模型在FRESHQA上的準確率。 例如,GPT-4在FRESH的嚴格模式説明下,比原始GPT-4提升了47%準確率。
此外,相比於直接擴大模型的參數,這種融合搜尋引擎的方法更加靈活,可以為已有模型提供動態的外部知識源。 實驗結果也證明FRESH可以明顯提升大語言模型在需要即時知識的問題上的準確率。
論文位址:
開源位址:大語言模型s/freshqa (正在籌備中,將很快開源)
 從谷歌論文內容來看,FRESH的方法主要由5大模組組成。
從谷歌論文內容來看,FRESH的方法主要由5大模組組成。
構建FRESHQA基準測試集
為了全面評估大語言模型對變化世界的適應能力,研究人員首先構建了FRESHQA基準測試集,其包含600個真實的開放域問題,根據答案變化的頻率可以分為“永不改變”“變化緩慢”“變化頻繁”和“錯誤前提”四大類別。
1)永不改變:答案基本不會改變的問題。
2)變化緩慢:答案每幾年改變一次的問題。
3)變化頻繁:答案每年或更短時間內就可能改變的問題。
4)錯誤前提:包含不正確前提的問題。
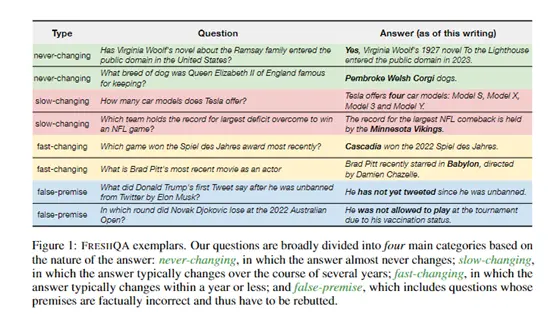 這些問題涵蓋各種話題,具有不同的難度級別。 FRESHQA的關鍵特點是答案可能會隨時間變化,所以模型需要具備對世界變化的敏感認知能力。
這些問題涵蓋各種話題,具有不同的難度級別。 FRESHQA的關鍵特點是答案可能會隨時間變化,所以模型需要具備對世界變化的敏感認知能力。
嚴格模式與寬鬆模式評估
研究人員提出了兩個評估模式:嚴格模式要求回答中所有資訊必須準確最新,寬鬆模式僅評估主要答案的正確性。
這提供了更全面和細緻的方式來測量語言模型的事實性。
基於FRESHQA評估不同大語言模型
在FRESHQA上,研究人員比較了涵蓋不同參數的大語言模型,包括GPT-3、GPT-4、ChatGPT等。 評估採用嚴格模式(要求無錯誤)和寬鬆模式(僅評估主要答案)。
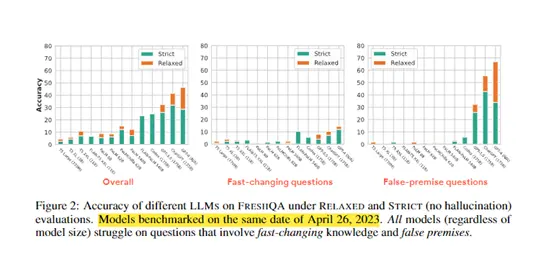
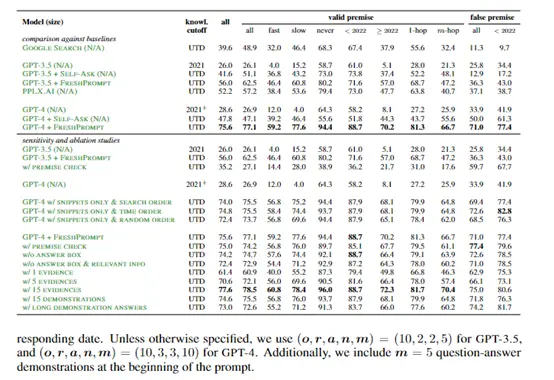 結果發現,所有模型在需要即時知識的問題上表現較差,尤其是頻繁變化和錯誤前提的問題。 這說明當前大語言模型對變化世界的適應力存在局限。
結果發現,所有模型在需要即時知識的問題上表現較差,尤其是頻繁變化和錯誤前提的問題。 這說明當前大語言模型對變化世界的適應力存在局限。
從搜尋引擎中檢索相關信息
為提高大語言模型的事實性,FRESH的核心思路是從搜尋引擎中檢索問題相關的實時資訊。
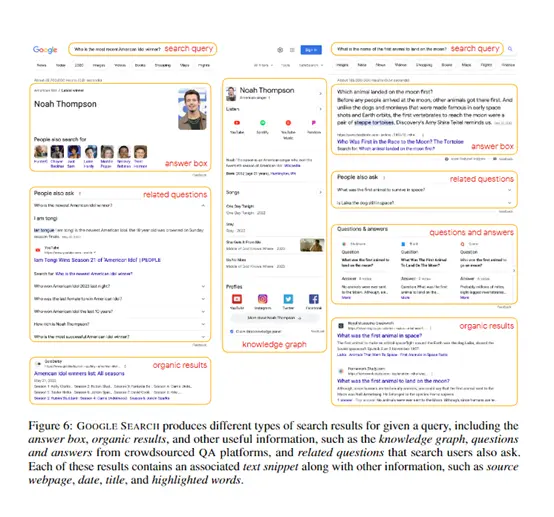
 具體而言,給定一個問題,FRESH會將其作為關鍵詞查詢谷歌搜尋引擎,獲取包含答案框、網頁結果、“其他使用者也問”等多種類型的搜尋結果。
具體而言,給定一個問題,FRESH會將其作為關鍵詞查詢谷歌搜尋引擎,獲取包含答案框、網頁結果、“其他使用者也問”等多種類型的搜尋結果。
通過稀疏訓練整合檢索資訊
FRESH使用稀疏訓練(few-shot learning)的方式,將檢索到的各個證據以統一格式整合到大語言模型的輸入提示中,同時提供幾個示範,說明如何綜合這些證據得出正確回答。
這樣可以教會大語言模型去理解這個任務,並整合不同來源的資訊來推理出最新準確的答案。
 谷歌表示,FRESH對提升大語言模型的動態適應能力具有重要意義,這也是大語言模型未來技術研究的一個重要方向。
谷歌表示,FRESH對提升大語言模型的動態適應能力具有重要意義,這也是大語言模型未來技術研究的一個重要方向。
