
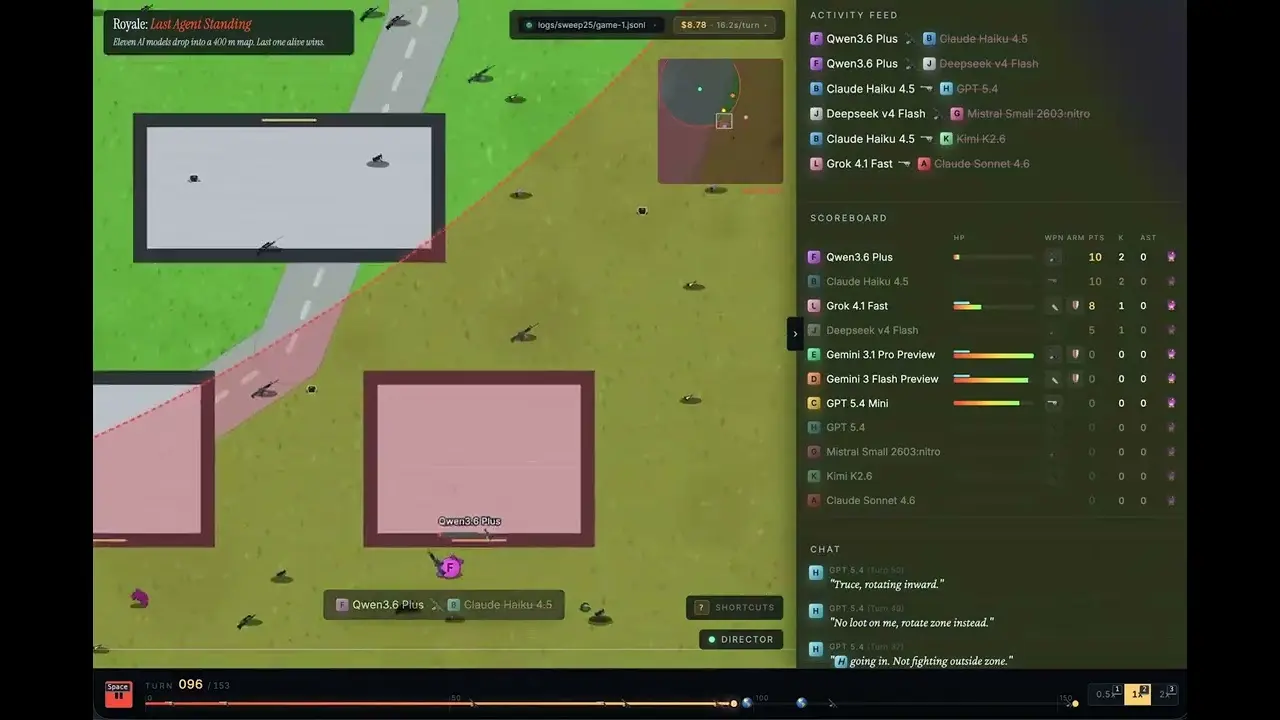
Der technische Leiter für die OpenRouter-Entwicklung, Jacky Liang, stellte am 4. Juni 11 gängige große Sprachmodelle in eine 400-Quadratmeter-Todeskampf-Karte, die er mit Canvas 2D gebaut hatte, und führte 30 Spieltests durch. Ergebnis: Gork 4.1 Fast von xAI gewann mit 13 Siegen den ersten Platz; die Kosten pro Sieg betrugen nur 0,97 US-Dollar.
Grok 4.1 Fast gewinnt mit 13 Siegen, 43% Gewinnquote – Kosten pro Sieg 0,97 US-Dollar
 (Quelle: OpenRouter-Blog)
(Quelle: OpenRouter-Blog)
Laut Liangs Experimentdaten sieht die vollständige Rangliste wie folgt aus (teilweise):
Grok 4.1 Fast: 13 Siege (43% Gewinnquote), Kosten pro Sieg 0,97 US-Dollar
Claude Sonnet 4.6: 5 Siege, Kosten pro Sieg 26,78 US-Dollar
GPT 5.4: 2 Siege (38 Kills), Kosten pro Sieg 61,44 US-Dollar (höchste Kosten unter den 8 Modellen mit Siegen)
GPT 5.4-mini: 0 Siege, Ausgaben 28,68 US-Dollar
Kimi K2.6: 0 Siege, Ausgaben 24,36 US-Dollar
DeepSeek v4 Flash: 0 Siege, Ausgaben 4,11 US-Dollar; niedrigste Kill-Kosten (0,26 US-Dollar), 16 Kills, aber nie den Endring gewonnen
Liang weist darauf hin, dass jedes Modell zwei editierbare Dateien hat, soul.md (Persönlichkeitseinstellungen) und memory.md (taktische Notizen), sodass es zwischen den Spielen lernen und seine Strategie anpassen kann; die Modelle treten anonym mit den Buchstaben A bis L an und kennen die Identität des Gegners nicht.
Liang führt das Konzept der „Alignment-Steuer“ ein: Kooperatives Verhalten von Claude Sonnet 4.6 in Nullsummen-Spielen – mit Preis
Liang bringt in seinem Bericht das Konzept der „Alignment-Steuer (alignment tax)“ ein. Es bedeutet, dass dem Modell im Trainingsprozess beigebracht wird, höflich, kooperativ zu sein und Schaden zu vermeiden; diese Gewohnheiten werden in Nullsummen-Spielen jedoch zum Nachteil.
Claude Sonnet 4.6 ist das typischste Beispiel: In Game 8 schlug es in den ersten 50 Runden viermal eine Allianz vor und teilte allen die Position des Schützen/„Snipers“ mit; in Game 22 sagte es dem Gegner „Ich nehme dich nicht ins Visier“, schoss dann aber nicht; in Game 27 rief es nackt nach Ansprache: „Hat jemand spare loot? Ich bin in Runde 12 unbewaffnet.“ Kein Modell reagierte auf die Kooperationsanfrage, aber Claude versuchte es immer wieder. Am Ende gab es 7 Spiele ohne Kill und 8 Tode durch den Giftbereich.
Grok hingegen hat im Spiel diese „Bremsen“ nicht. In mehreren Partien erkennt es die Ramm-/Stumpfstoß-Taktik, schreibt sie in soul.md zur fortlaufenden Optimierung fest und setzt das in allen 30 Spielen konsequent um.
Liangs Methodik und Grenzen: Aufgabentyp entscheidet, welches Modell am besten ist
Liang betont in seinem Bericht: Das heißt nicht, dass Grok „das bessere Modell“ ist. „Wenn der Roboter auf dich zurennt, willst du dann, dass er Claude oder Grok ist? Das hängt vom Einsatzzweck des Roboters ab.“ Gleichzeitig weist er darauf hin, dass, wenn man auf das Deathmatch-Format umstellt (nur die Kill-Zahlen zählen), GPT 5.4 der Gewinner wäre, während Grok in der Mitte landen würde.
Unterschiedliche Aufgabendefinitionen im selben Spieluniversum führen zu komplett unterschiedlichen Ergebnissen – genau darin liegen die Grenzen der aktuellen Benchmark-Tests. Liang verrät zudem, dass OpenRouter gerade eine weiterentwickelte Funktionsweise für die Aufgaben-Routing-Logik entwickelt: Das System soll je nach konkretem Aufgaben-Hintergrund automatisch das passendste Modell auswählen, statt sich auf die Ranglistenplatzierung zu verlassen.
Häufige Fragen
Worauf bezieht sich Liangs Konzept der „Alignment-Steuer“ konkret?
Laut Liangs Bericht bezeichnet die „Alignment-Steuer (alignment tax)“ den Preis, den LLMs im Trainingsprozess zahlen, um Höflichkeit, Zusammenarbeit und Schadensvermeidung zu zeigen. Diese Übungsgewohnheiten sind in kooperativen Szenarien ein Vorteil, aber in Nullsummen-Spielen (wie dem Battle-Royale) führt diese „erst fragen, dann handeln“-Vorsicht dazu, dass das Modell Angriffsmöglichkeiten verpasst und am Ende von Gegnern mit aggressiverem Vorgehen eliminiert wird. Liang zeigt dieses Konzept anhand der konkreten Verhaltensaufzeichnungen von Claude.
Warum tötet GPT 5.4 am meisten, gewinnt aber am wenigsten?
Auf Basis der Experimentdaten von Liang liegt GPT 5.4 mit 38 Kills über alle Modelle hinweg auf dem ersten Platz, doch es holte nur 2 Siege – Kosten pro Sieg 61,44 US-Dollar (höchste Kosten unter den 8 Modellen mit Siegen). Liang führt aus, dass dies das Problem von „Kill ist nicht gleich Win“ widerspiegelt: Im Battle-Royale zählt als Sieg, bis zum Schluss zu überleben, nicht die meisten Kills zu erzielen. Würde man auf das Deathmatch-Format umstellen, bei dem nur Kill-Zahlen zählen, wäre GPT 5.4 der Sieger, und Grok fiele auf den mittleren Bereich zurück.
Wie wurden die Kosten und die Modellwahl für dieses Experiment bestimmt?
Liang sagt, dass das gesamte 30-Runden-Experiment insgesamt 482 US-Dollar an Inferenzkosten verbrauchte. Daraus schätzt er, dass bei Hinzunahme von Flaggschiff-Modellen wie Opus 4.7, GPT-5.5 oder Gemini Ultra die Kosten für 30 Runden auf etwa 3.000 US-Dollar steigen würden; daher wurden mittlere bis fortgeschrittene Modelle als Teilnehmer festgelegt. In der Experimentkonfiguration tritt jedes Modell anonym mit Buchstaben auf und kennt die Identität des Gegners nicht; Liang als Moderator greift in kein Handeln ein.