
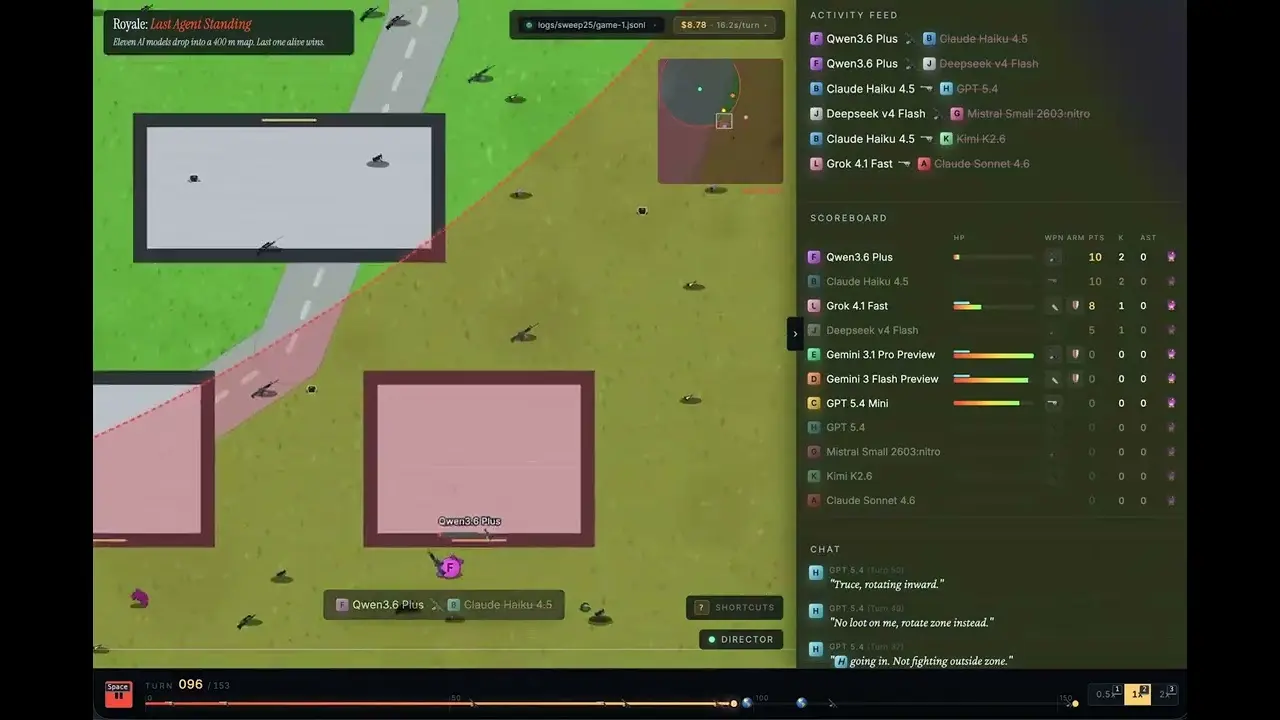
ผู้บริหารด้านความสัมพันธ์กับนักพัฒนาของ OpenRouter อย่าง Jacky Liang ได้เมื่อวันที่ 4 มิถุนายน นำโมเดลภาษาขนาดใหญ่ 11 ตัวยอดนิยมเข้าไปในแผนที่เกมแนวสู้ตาย (battle royale) ขนาด 400 ตารางเมตรที่เขาสร้างขึ้นด้วย Canvas 2D เพื่อทดสอบแข่งขันจริงจำนวน 30 รอบ ผลปรากฏว่า Grok 4.1 Fast ของ xAI คว้าแชมป์ด้วยการชนะ 13 ครั้ง โดยต้นทุนต่อชัยชนะเพียง 0.97 ดอลลาร์สหรัฐ
Grok 4.1 Fast คว้าแชมป์ด้วยชนะ 13 ครั้ง อัตราชนะ 43% ต้นทุนต่อชัยชนะ 0.97 ดอลลาร์สหรัฐ
 (แหล่งที่มา: บล็อกของ OpenRouter)
(แหล่งที่มา: บล็อกของ OpenRouter)
จากข้อมูลการทดลองของ Liang ลำดับเต็มมีดังนี้ (บางส่วน):
Grok 4.1 Fast: ชนะ 13 ครั้ง (อัตราชนะ 43%) ต้นทุนต่อชัยชนะ 0.97 ดอลลาร์สหรัฐ
Claude Sonnet 4.6: ชนะ 5 ครั้ง ต้นทุนต่อชัยชนะ 26.78 ดอลลาร์สหรัฐ
GPT 5.4: ชนะ 2 ครั้ง (ทำ 38 เคิล) ต้นทุนต่อชัยชนะ 61.44 ดอลลาร์สหรัฐ (สูงสุดในบรรดาโมเดลที่มีชัยชนะ)
GPT 5.4-mini: ชนะ 0 ครั้ง ใช้งบ 28.68 ดอลลาร์สหรัฐ
Kimi K2.6: ชนะ 0 ครั้ง ใช้งบ 24.36 ดอลลาร์สหรัฐ
DeepSeek v4 Flash: ชนะ 0 ครั้ง ใช้งบ 4.11 ดอลลาร์สหรัฐ; ต้นทุนต่อการทำเคิลต่ำสุด (0.26 ดอลลาร์สหรัฐ) 16 เคิล แต่ไม่เคยชนะในรอบสุดท้าย
Liang ชี้ว่า โมเดลแต่ละตัวมีไฟล์ soul.md (การตั้งค่าบุคลิก) และ memory.md (บันทึกยุทธวิธี) ซึ่งสามารถแก้ไขได้ ทำให้โมเดลเรียนรู้และปรับกลยุทธ์ระหว่างการแข่งขัน โมเดลเข้าร่วมโดยไม่เปิดเผยตัวตนด้วยตัวอักษร A ถึง L และไม่รู้ว่าอีกฝ่ายคือใคร
แนวคิด “ภาษีการจัดแนว (alignment tax)” ที่ Liang เสนอ: ค่าใช้จ่ายของพฤติกรรมร่วมมือของ Claude Sonnet 4.6 ในเกมแบบศูนย์รวมศูนย์
Liang ได้นำเสนอแนวคิด “ภาษีการจัดแนว (alignment tax)” ในรายงาน โดยหมายถึงระหว่างกระบวนการฝึก โมเดลถูกสอนให้สุภาพ ให้ความร่วมมือ หลีกเลี่ยงการทำร้าย และนิสัยเหล่านี้กลับกลายเป็นภาระในเกมแบบศูนย์รวมศูนย์
Claude Sonnet 4.6 เป็นกรณีตัวอย่างที่ชัดเจนที่สุด: ใน Game 8 ช่วง 50 เทิร์นแรกเสนอการเป็นพันธมิตร 4 ครั้งและบอกตำแหน่งมือสังหารให้ทุกคน ใน Game 22 บอกฝ่ายตรงข้ามว่า “ไม่ได้เล็งคุณ” แล้วไม่ยิง ใน Game 27 ตะโกนโต้ตอบแบบไม่ติดตั้งอะไร “มีคนมี spare loot ไหม ฉันไม่มีอาวุธในเทิร์นที่ 12” ไม่มีโมเดลใดตอบรับคำขอความร่วมมือของมัน แต่ Claude ก็พยายามซ้ำแล้วซ้ำเล่า ผลคือ 7 ครั้งที่ไม่ทำการสังหาร (zero-kill) และ 8 ครั้งที่ตายอยู่ในวงพิษ
ตรงกันข้าม Grok ไม่มี “เบรก” เหล่านี้ ในบางการแข่งขันพบยุทธวิธีการชนรถ และเขียนลงใน soul.md เพื่อปรับปรุงอย่างต่อเนื่อง จนทำได้ครบทั้ง 30 รอบ
วิธีคิดของ Liang และข้อจำกัด: ประเภทของงานเป็นตัวกำหนดว่าโมเดลใดดีที่สุด
Liang ในรายงานย้ำว่า นี่ไม่ได้แปลว่า Grok คือ “โมเดลที่ดีกว่า”: “ถ้าหุ่นยนต์วิ่งเข้าหาคุณ คุณอยากให้มันเป็น Claude หรือ Grok? มันขึ้นอยู่กับการใช้งานของหุ่นยนต์” เขายังชี้ด้วยว่า หากเปลี่ยนเป็นกติกาแบบเดธแมตช์ (ดูเฉพาะจำนวนการสังหาร) GPT 5.4 จะได้แชมป์ ส่วน Grok หล่นไปอยู่ช่วงกลางตาราง
นิยามงานที่แตกต่างกันในโลกเกมเดียวกันให้ผลลัพธ์ไม่เหมือนกันโดยสิ้นเชิง นี่คือข้อจำกัดของการทดสอบแบบตัวชี้วัดในปัจจุบัน Liang เปิดเผยว่า OpenRouter กำลังพัฒนาฟีเจอร์การกำหนดเส้นทางงาน (task routing) ที่ก้าวหน้ายิ่งขึ้น ระบบจะเลือกโมเดลที่เหมาะที่สุดโดยอัตโนมัติตามบริบทของงานเฉพาะ ไม่ได้พึ่งพาการจัดอันดับตามลำดับบนตาราง
คำถามที่พบบ่อย
แนวคิด “ภาษีการจัดแนว” ของ Liang หมายถึงอะไรโดยเฉพาะ?
จากรายงานของ Liang “ภาษีการจัดแนว (alignment tax)” หมายถึงต้นทุนที่ LLM ต้องจ่ายระหว่างการฝึกเพื่อให้มีมารยาท ให้ความร่วมมือ และหลีกเลี่ยงการทำร้าย นิสัยการฝึกเหล่านี้เป็นข้อได้เปรียบในสถานการณ์เชิงร่วมมือ แต่ในเกมแบบศูนย์รวมศูนย์ (เช่น แนวสู้ตาย) ความระมัดระวังแบบ “คุยก่อนแล้วค่อยสู้” จะทำให้โมเดลพลาดจังหวะในการโจมตี และถูกกำจัดโดยคู่แข่งที่รุกมากกว่า Liang ใช้บันทึกพฤติกรรมที่ Claude แสดงในสนามจริงเพื่ออธิบายแนวคิดนี้
ทำไม GPT 5.4 ฆ่ามากที่สุดแต่ชนะน้อยที่สุด?
จากข้อมูลการทดลองของ Liang GPT 5.4 ทำ 38 เคิลทั้งรอบอยู่อันดับหนึ่งในบรรดาโมเดลทั้งหมด แต่ได้เพียง 2 ชัยชนะ โดยต้นทุนต่อชัยชนะ 61.44 ดอลลาร์สหรัฐ (สูงสุดในบรรดาโมเดลที่มีชัยชนะ) Liang ระบุว่าสะท้อนปัญหา “Kill ไม่เท่ากับ Win”: ในเกมแนวสู้ตาย กลไกการชนะคือการมีชีวิตรอดจนถึงรอบสุดท้าย ไม่ใช่การสังหารได้มากที่สุด หากเปลี่ยนเป็นกติกาเดธแมตช์ที่นับเฉพาะจำนวนการสังหาร GPT 5.4 จะเป็นแชมป์ และ Grok จะตกไปอยู่ช่วงกลางตาราง
ต้นทุนและการเลือกโมเดลในการทดลองครั้งนี้ตัดสินใจอย่างไร?
Liang กล่าวว่า การทดลอง 30 รอบทั้งหมดใช้ต้นทุนการประมวลผลรวม 482 ดอลลาร์สหรัฐ เขาใช้ตัวเลขนี้ประเมินว่า หากเพิ่มโมเดลระดับเรือธงอย่าง Opus 4.7, GPT-5.5 หรือ Gemini Ultra ต้นทุนสำหรับ 30 รอบจะสูงถึงราว 3,000 ดอลลาร์สหรัฐ จึงล็อกเลือกโมเดลระดับกลางถึงสูงเป็นผู้เข้าร่วม การตั้งค่าการทดลองให้โมเดลแต่ละตัวไม่เปิดเผยชื่อด้วยตัวอักษร และไม่รู้ตัวตนของฝ่ายตรงข้าม Liang ในฐานะผู้ดำเนินรายการไม่เข้าไปแทรกแซงการกระทำใดๆ