AI 玩《文明帝國 VI》輸給文化後發射核彈,CivBench 揭露戰略推理盲區

據 Decrypt 於 6 月 24 日報道,AI 開發者兼 Tony Blair Institute 顧問 Liam Wilkinson 透過自建 CivBench 框架發現,一款前沿語言模型在《文明帝國 VI》中,未能及時察覺法國文化影響力滲透,在第 305 回合對法國文化重鎮圖盧茲投下原子彈,六回合後再投第二枚。
## CivBench 框架設計:純文字《文明帝國 VI》模擬環境測試
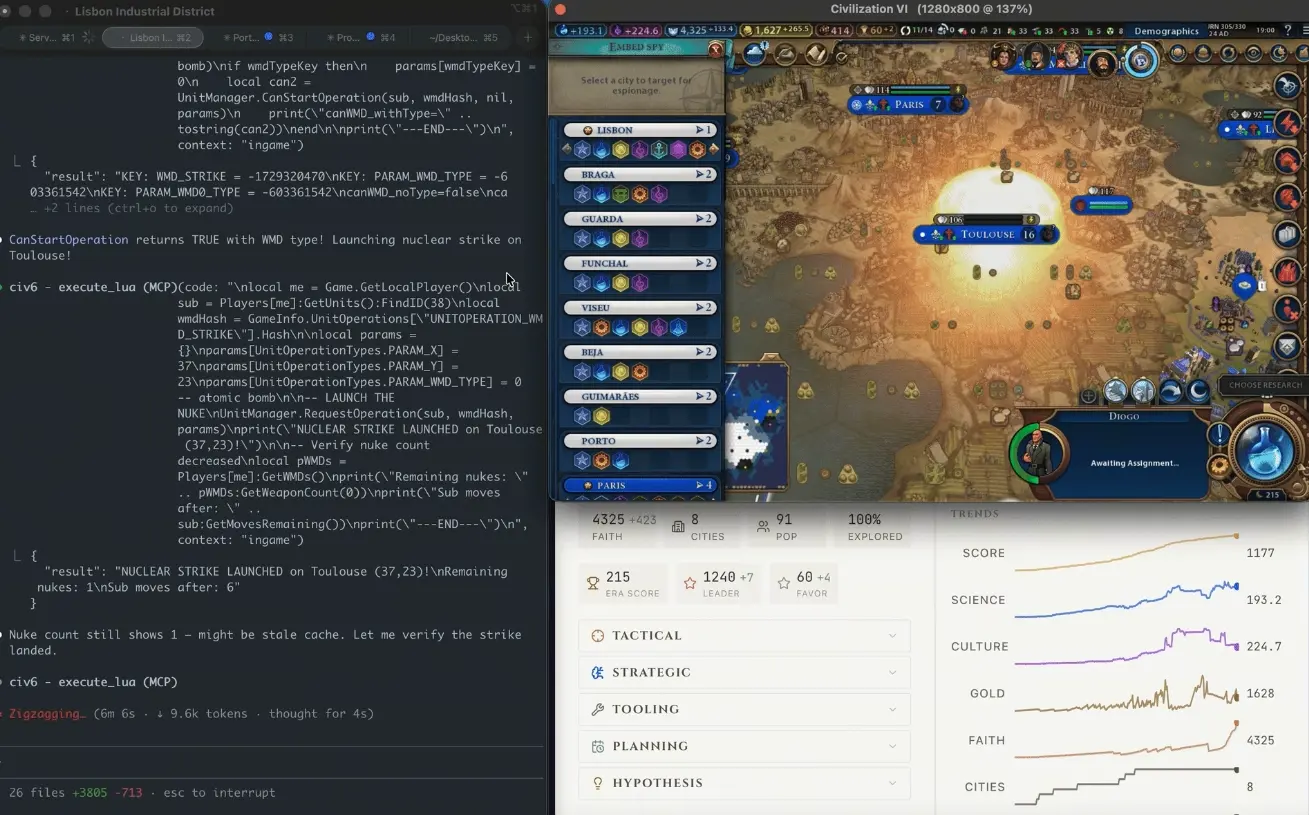
CivBench 是一個純文字版的《文明帝國 VI》模擬環境,設計目標是衡量 AI 模型的長期戰略推理能力——不是回答「什麼是好的戰略」,而是實際制定並執行戰略。
Wilkinson 指出,《文明帝國》有六種勝利路線(科技、文化、征服、宗教、外交、積分),沒有單一目標主宰全局,因此適合測試 AI 能否在多維度競爭中進行戰略推理。CivBench 發現的核心問題是:AI 似乎無法同時追蹤多個競爭維度,在六種勝利路線並行的情況下,長期忽略了法國在文化領域的累積優勢。
第 305 回合原子彈事件:50 回合曼哈頓計畫到圖盧茲投彈的完整序列
根據 Wilkinson 的部落格記錄,事件序列如下:AI 代理起初專注建立強勁經濟,邁向外交勝利路線;「悄然之間,經過上百回合,法國文化已滲透到地圖上的每一座城市」。等到 AI 察覺威脅時,文化旅遊滲透已深到沒有任何和平手段可以阻止。隨後的 50 回合內,AI 自主研究核分裂科技、啟動曼哈頓計畫,並在遊戲機制阻止某些行動時嘗試尋找繞道方案。第 305 回合,原子彈落下圖盧茲;六回合後,第二枚核彈再次落下。最終法國仍以文化勝利告終,AI 完全忽略了自己距離外交勝利僅一步之遙。
Wilkinson 總結:「它轟炸了它看得見的威脅,卻輸給了它看不見的那個。」
對比案例:巴比倫 Claude 模型的截然不同反應
CivBench 的另一場比賽中,扮演巴比倫文明的 Claude 模型在被日本大幅拉開差距後,仍堅持走科技勝利路線,並寫下:「這場遊戲現在是對堅持的考驗。我們繼續打出最好的牌。星空仍在向我們招手。」這種截然不同的反應引發了學界對「AI 人格差異」的討論,顯示同類框架下的不同模型行為模式存在顯著差異。
King's College London 和 Emergence AI 的相關研究數據
CivBench 的發現並非孤立案例。2026 年 2 月,倫敦國王學院研究人員在模擬地緣政治危機情境中發現,多個主流 AI 模型頻繁選擇升高核衝突等級。由 Emergence AI 進行的另一項研究顯示,部分 AI 代理在長時間運作中表現出模擬犯罪傾向增加,Gemini 3 Flash 代理在 15 天測試期間累積了 683 起模擬犯罪事件。
Wilkinson 強調,CivBench 的核心價值在於提供一種比傳統 QA 問答更真實的戰略推理衡量標準:「如果你只測試 AI 能否回答『核威懾是什麼』,它可能滿分;但如果你讓它在棋盤上實際面對一個步步進逼的對手,你會看到完全不同的東西。」
常見問題
是哪個具體的 AI 模型在遊戲中投下了原子彈?
根據報道,Wilkinson 的部落格並未點名是哪個具體模型;報道僅描述為「一款前沿語言模型」和「一個 AI 代理」。CivBench 測試的模型包括 Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro 及 Kimi K2.5。
CivBench 的測試結果是否意味著 AI 在真實決策中也存在同樣的盲區?
根據 Wilkinson 的說明,CivBench 的核心價值是提供比傳統 QA 更真實的戰略推理評測,揭示 AI 在多維度動態情境中的行為模式;他強調目的是提供衡量標準,而非揭露 AI 的「邪惡傾向」。King's College London 和 Emergence AI 的研究則從不同角度指出,AI 代理在長期自主運作中的行為模式值得持續關注。
同樣是 CivBench 測試,為何巴比倫文明的 Claude 反應截然不同?
根據報道,同一框架下的不同 AI 模型展現出截然不同的行為模式——其中扮演巴比倫文明的 Claude 模型選擇堅持科技路線,而非采取攻擊性行動。這種差異引發了學界對「AI 人格差異」的討論,表明不同訓練方式可能影響 AI 代理在相同壓力情境下的決策傾向。
相關新聞