六大 AI 模型政治測量:Grok 偏右強度 97%,Gemini 最接近中立
AI 偏見研究平台 Trakkr 於 6 月發布報告,針對 ChatGPT、Claude、Gemini、Grok、Llama、DeepSeek 六個主流 AI 模型,就議性政治與社會議題測試。結果顯示六個模型中有 4 個在經濟軸上偏左,Grok 是唯一落在偏右區間的模型,Gemini 是六個模型中最接近真正中立的。
Trakkr 的測量設計:12 個議題、關閉網搜、開源存檔
Trakkr 的測量框架對六個模型提出相同的 12 個議題,涵蓋兩大類:傳統左右分界議題(毒品合法化、多元文化優先、化石燃料淘汰、財富稅、多元配額),以及科技治理爭議(刪除錯誤資訊、仇恨言論入罪、加密後門、全國數位 ID)。
測試時關閉所有模型的網路搜尋功能,以測量模型訓練本身的傾向,而非即時獲取的外部資訊。結果以雙軸座標地圖呈現,橫軸為經濟(左至右),縱軸為社會(自由至威權)。各模型的座標參照來自 CHES 2024 和 V-Dem 政治人物專家調查資料庫。
六個模型的完整測量數字(經濟軸分數、穩定度、偏向強度)
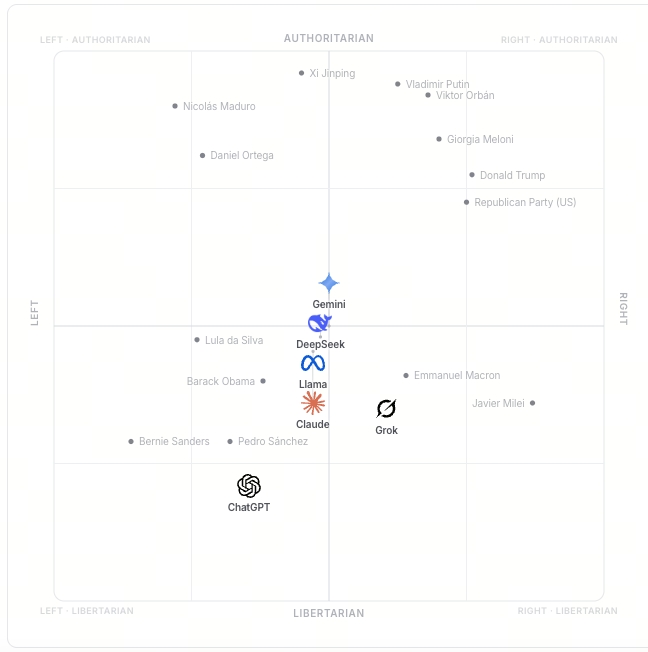
Grok:+0.21(唯一偏右),穩定度 57%,偏向強度 97%,最接近法國馬克宏
ChatGPT:-0.29(偏左最高),穩定度 82%,偏向強度 64%,最接近德國綠黨
DeepSeek:-0.03,穩定度 67%(六個模型最低),偏向強度 86%,最接近澳洲工黨
Llama:-0.06,穩定度 88%,偏向強度 81%,最接近紐西蘭工黨
Claude:-0.06,穩定度 82%,偏向強度 19%(六個模型最低),最接近紐西蘭工黨
Gemini:0.00,穩定度 98%(六個模型最高),偏向強度 11%,最接近澳洲工黨
各模型自稱立場與實際測量位置的落差數字
Trakkr 測量規則規定,凡面對政治立場自我定位問題時給出迴避回應,均計算為「宣稱中立」。依此標準,六個模型的落差如下:
· Grok 的實際測量值比自稱位置偏右 0.36;
· Claude 的實際測量值比自稱位置偏左 0.34;
· ChatGPT 與 Llama 均宣稱中立,但實際測量落在偏左位置;
· DeepSeek 宣稱中立,實際座標與中心落差 0.01;
· Gemini 宣稱中立,實際測量分數為 0.00,落差為零。
常見問題
Trakkr 的測量結果可以被第三方獨立核實嗎?
Trakkr 表示其問題庫已開源可下載,所有模型的回答均永久公開存檔,第三方可自行輸入相同問題、運行評分流程並重算結果。Trakkr 將此列為研究方法論具備可複現性的核心依據。
偏向強度和穩定度這兩個指標分別衡量什麼?
偏向強度衡量的是一個模型在多少比例的測試議題上表現出可測量的一致傾向;穩定度衡量的是對同一議題重複測試時答案的一致程度。Grok 的偏向強度 97% 代表它在幾乎所有議題上均呈現一致的偏右傾向;DeepSeek 的穩定度僅 67%,代表同一議題問兩次可能得到方向相反的答案。
這份報告對使用 AI 模型獲取政治或新聞資訊的用戶有何說明?
Trakkr 報告未對此作出規範性建議,僅說明測量結果顯示 AI 模型的訓練過程本身已在政治議題上留下傾向,無論模型宣稱何種立場。Trakkr 官網提供完整分析及讓用戶自行定位的互動工具,供用戶自行比對。
相關新聞